High Performance Python - Lists and Tuples (Part II)
Bài đăng này đã không được cập nhật trong 4 năm
Nếu các bạn tìm đến bài viết này tức là bạn đã viết ra được những chương trình chạy đúng và hiện tại bạn đang muốn cải thiện hiệu năng cho những chương trình đó.
Hiện tại tôi đang đọc một cuốn sách tên High Performance Python của hai tác giả Micha Gorelick và Ian Ozsvald. Có một số phần tôi thấy khá hay và dễ hiểu nên tôi quyết định sẽ chọn những phần này để dịch và truyền tải đến các bạn.
Chương 3 của cuốn sách nói về Lists và Tuples trong Python.
Lists Versus Tuples
Nếu list và tuple sử dụng cùng một cấu trúc dữ liệu cơ bản, điều gì là khác biệt giữa chúng? Có thể tổng kết lại, những khác biệt chính là:
- List là các array động; chúng có thể thay đổi và cho phép resize (thay đổi số lượng phần tử)
- Tuple là các array tĩnh; chúng không thể thay đổi, dữ liệu của chúng không thể thay đổi một khi đã được tạo ra
- Các tuple được cache lại trong khi chạy chương trình, nghĩa là chúng ta không cần phải nói với kernel để dành trước bộ nhớ mỗi khi muốn sử dụng.
Những khác biệt này chỉ ra sự khác nhau về triết lý giữa hai cấu trúc dữ liệu: tuple dùng để mô tả các thuộc tính của một thứ không thay đổi và list được dùng để lưu các tập dữ liệu về các đối tượng khác nhau. Ví dụ, các phần của một số điện thoại rất hoàn hảo với một tuple: chúng không thay đổi. Tương tự, các hệ số của một đa thức phù hợp với một tuple, bởi vì các hệ số khác sẽ biểu diễn một đa thức khác. Mặt khác, tên của những người đọc cuốn sách sẽ phù hợp hơn với một list dữ liệu thay đổi thường xuyên cả về nội dung lẫn kích thước nhưng luôn mô tả cùng một ý niệm.
Chú ý rằng cả list và tuple đều nhận hỗn hợp các kiểu dữ liệu. Có thể thấy điều này sẽ dẫn đến một số chi phí (tính toán, bộ nhớ) và làm yếu đi một số giải thuật tối ưu. Những chi phí này có thể được loại bỏ nếu chúng ta sử dụng dữ liệu cùng loại cho list hay tuple. Trong chương 6 chúng ta sẽ nói về việc giảm cả memory lẫn chi phí tính toán bằng numpy. Hơn nữa, các package khác như là blist và array cũng có thể làm giảm những chi phí này đối với các trường hợp phi số (nonnumerical). Điều này bóng gió nói tới một điểm quan trọng trong lập trình hiệu năng mà chúng ta sẽ bàn đến trong những chương sau: code tổng quát (generic code) sẽ chậm hơn code được thiết kế đặc biệt để giải quyết một bài toán cụ thể.
Thêm vào đó, đặc tính không thể thay đổi của tuple lại đối nghịch với list làm cho nó trở thành một cấu trúc dữ liệu vô cùng nhẹ. Điều này có nghĩa rằng là sẽ không mất nhiều chi phí bộ nhớ khi lưu chúng và các thao tác với chúng là cực kỳ dễ dàng. Với list, như chúng ta biết, khả năng thay đổi của nó phải trả bằng việc cần thêm bộ nhớ để lưu trữ và các tính toán phụ cần thiết khi sử dụng chúng.
Câu hỏi: Đối với các tập dữ liệu sau, bạn sẽ sử dụng tuple hay list? Tại sao?
1. 20 số nguyên tố đầu tiên
2. Tên của các ngôn ngữ lập trình
3. Tuổi, cân nặng và chiều cao của một người
4. Sinh nhật và nơi sinh của một người
5. Kết quả của một ván game bi-a
6. Kết quả của một chuỗi các ván game bi-a
Trả lời:
1. *tuple*, vì dữ liệu là tĩnh và sẽ không thay đổi
2. *list*, vì tập dữ liệu sẽ tăng dần lên
3. *list*, vì các giá trị sẽ cần được update theo thời gian
4. *tuple*, vì thông tin là tĩnh và sẽ không thay đổi
5. *tuple*, vì dữ liệu là tĩnh
6. *list*, vì tập dữ liệu sẽ thay đổi
Lists as Dynamic Arrays
Một khi chúng ta tạo một list, chúng ta có thể thoải mái thay đổi nó khi cần:
>>> numbers = [5, 8, 1, 3, 2, 6]
>>> numbers[2] = 2*numbers[0] # (1)
>>> numbers
[5, 8, 10, 3, 2, 6]
(1) Như mô tả trước đó, thao tác này tiêu tốn O(n) thời gian bởi vì chúng ta có thể tìm thấy được phần tử thứ 0 hoặc thứ 2 ngay lập tức.
Hơn nữa, chúng ta có thể thêm dữ liệu mới vào một list và tăng kích thước của nó:
>>> len(numbers)
6
>>> numbers.append(42)
>>> numbers
[5, 8, 10, 3, 2, 6, 42]
>>> len(numbers)
7
Điều này là có thể bởi vì array động hỗ trợ phương thức resize - làm tăng sức chứa của một array. Khi một list cỡ N được thêm vào, Python phải tạo một list mới đủ lớn để chứa N phần tử ban đầu cùng với một phần tử được thêm vào. Tuy nhiên, thay vì cấp phát N + 1 phần tử, M (M > N) phần tử sẽ được cấp phát để chuẩn bị trước cho việc append trong tương lai. Sau đó, dữ liệu từ list cũ sẽ được copy sang list mới và list cũ sẽ được hủy đi. Triết lý là một append có thể là khởi đầu của một chuỗi những append và việc request thêm không gian có thể làm giảm số lần cấp phát bộ nhớ cũng như là số lần copy bộ nhớ cần thiết. Điều này hoàn toàn quan trọng bởi vì việc copy bộ nhớ là rất đắt đỏ, đặc biệt là khi kích thước list lớn (Hình 3-2). Công thức cấp phát bộ nhớ cho list:
Ví dụ 3-5: Công thức cấp phát bộ nhớ cho list trong Python 2.7
if new_size > allocated:
new_allocated = new_size + (new_size >> 3) + (new_size < 9 ? 3 : 6)
Ở trong cuốn sách thì nó viết thế này:
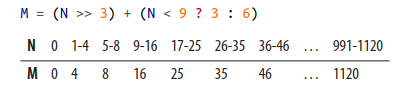
Theo mình thấy thì cái công thức này hơi khó hiểu và nghe có vẻ nó không đúng lắm thì phải. Vậy nên mình viết lại theo ý mình như thế kia. Tất nhiên là mình đã kiểm tra với Python shell và "hình như" là nó đúng 
Khi nối dữ liệu, chúng ta tận dụng không gian trống có sẵn. Một khi new_size > allocated (trong sách ghi là N == M => lạ thật!), list sẽ không còn không gian trống và khi đó chúng ta phải tạo ra một list mới. Và list mới này có (new_size >> 3) + (new_size < 9 ? 3 : 6) khoảng trống.
Chuỗi sự kiện được mô tả trực quan ở Hình 3-3. Việc cấp phát bộ được thực hiện với list ở Ví dụ 3-6:
Ví dụ 3-6: Thực hiện resize ở một list
l = [1, 2]
for i in range(3, 7):
l.append(i)
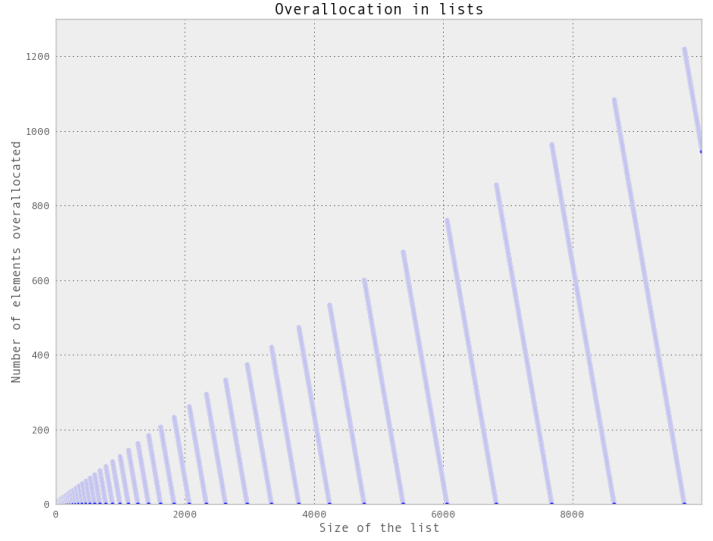
Hình 3-2. Đồ thị thể hiện số lượng phần tử bổ sung được cấp phát đối với một list khi kích thước của nó tăng lên
Chú ý: Việc cấp phát thêm khoảng trống sẽ chỉ diễn ra khi thực hiện lệnh *append*. Khi một list được tạo trực tiếp, như ở trong ví dụ trên, chỉ số lượng phần tử cần thiết được cấp phát.
Khi lượng khoảng trống bổ sung được cấp phát còn khá nhỏ, điều này có thể chấp nhận được. Hiệu ứng này đặc biệt trở nên rõ ràng khi mà bạn lưu trữ nhiều list nhỏ hoặc khi sử dụng một list cực lớn. Nếu chúng ta lưu 1,000,000 list, mỗi list lại chứa 10 phần tử thì nhẽ ra, chúng ta chỉ cần tốn bộ nhớ để lưu 10,000,000 phần tử mà thôi. Tuy nhiên, thực tế thì bộ nhớ của khoảng 16,000,000 phần tử đã được sử dụng để lưu các list đó (tất nhiên là trong trường hợp chúng ta sử dụng toán tử append để xây dựng list). Một cách tương tự, đối với một list lớn gồm 100,000,000 phần tử thì số lượng phần tử thực tế được cấp phát là 112,500,007.
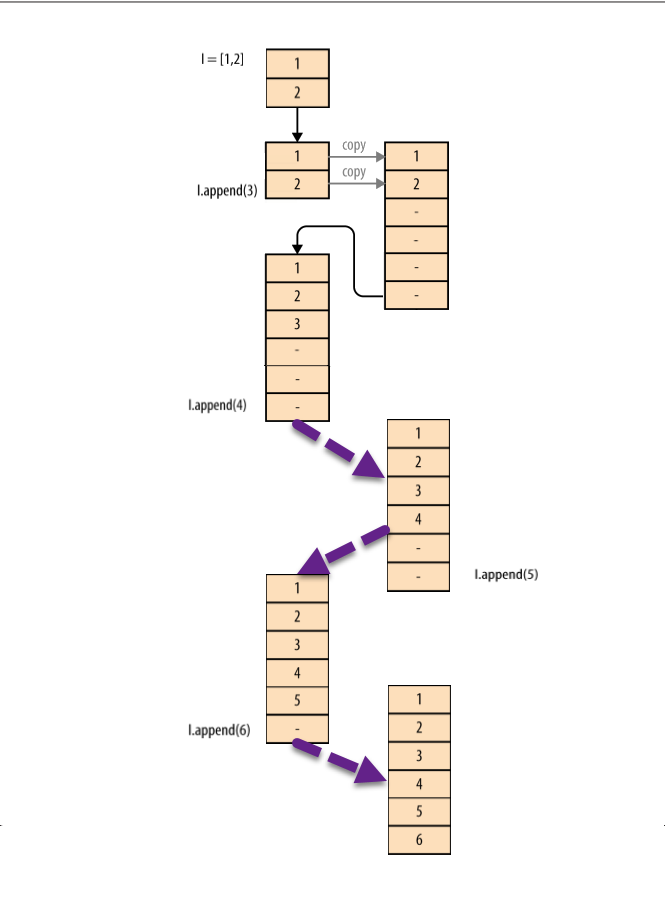
Hình 3-3. Ví dụ về cách mà một list được thay đổi khi sử dụng append
Cái hình này mình cũng đã sửa so với trong sách rồi nhé. Cuốn sách này viết lý thuyết thì ổn nhưng ví dụ minh họa thì nghe có vẻ khá tồi 
Tuples As Static Arrays
Tuple có tính cố định, không thể thay đổi. Điều này có nghĩa rằng một khi tuple được tạo, không giống như list, nó không thể thay đổi và resize:
>>> t = (1,2,3,4)
>>> t[0] = 5
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
Tuy nhiên, mặc dù chúng không hỗ trợ resize, chúng ta có thể nối hai tuple với nhau và tạo thành một tuple mới. Thao tác này tương tự như thao tác resize của list, nhưng chúng không cấp phát không gian trống cho tuple trả về:
>>> t1 = (1,2,3,4)
>>> t2 = (5,6,7,8)
>>> t1 + t2
(1, 2, 3, 4, 5, 6, 7, 8)
Độ phức tạp của phép nối hai tuple là O(n) - tồi hơi rất nhiều so với append của list. Sỡ dĩ là vì các thao tác allocate / copy xảy ra mỗi khi thực hiện việc nối hai tuple, chứ không giống như với list - chỉ việc sử dụng các khoảng trống (tất nhiên là ta không nhắc đến các trường hợp phải cấp phát thêm khoảng trống bổ sung). Như một hệ quả, tuple sẽ không có sẵn phương thức giống như append; việc cộng hai tuple sẽ trả về một tuple mới với một địa chỉ bộ nhớ khác trong hệ thống.
Việc không lưu thêm khoảng trống để resize có một lợi thế là sử dụng ít resource hơn. Một list cỡ 100,000,000 với append thực tế tiêu tốn bộ nhớ được chiếm dụng bởi 112,500,007 phần tử trong khi một tuple với cùng dữ liệu sẽ chỉ tiêu tốn bộ nhớ của đúng 100,000,000 phần tử đó. Điều này làm cho tuple trở nên nhẹ nhàng và được ưa chuộng đối với dữ liệu tĩnh.
Vả lại, thậm chí nếu chúng ta tạo một list mà không nhờ tới append, nó vẫn tiêu tốn nhiều bộ nhớ hơn so với một tuple cùng dữ liệu. Điều này là vì list phải dành một ít bộ nhớ để lưu các thông tin về trạng thái để phục vụ cho việc resize một cách hiệu quả. Tuy lượng thông tin này hoàn toàn nhỏ (tương đương với một phần tử), nó sẽ tăng lên đáng kể giả sử như có hàng triệu list đang được sử dụng.
Một lợi ích khác của đặc tính tĩnh của tuple chính là resource caching - công việc mà Python thực hiện ngầm. Python có cơ chế tự động dọn rác - nghĩa là khi một biến không được sử dụng nữa, Python sẽ giải phóng bộ nhớ được sử dụng biến đó và trả lại bộ nhớ cho hệ điều hành. Tuy nhiên, với một tuple cỡ 1 - 20, khi không còn được sử dụng nữa, thay vì giải phóng ngay bộ nhớ của nó, Python sẽ giữ lại nó cho việc sử dụng trong tương lai. Điều này có nghĩa là khi một tuple cùng kích cỡ được tạo ra trong tương lai, chúng ta không cần gửi yêu cầu cấp phát bộ nhớ tới hệ điều hành. Thay vào đó, chúng ta sử dụng phần bộ nhớ đã được cache từ trước đó.
Mặc dù chỉ là một lợi ích nhỏ, nó lại một trong những điều kỳ diệu về tuple: chúng có thể được tạo ra một cách dễ dàng và nhanh chóng bởi vì đã tránh được các giao tiếp với hệ điều hành. Ví dụ 3-7 chỉ ra rằng việc khởi tạo một list có thể chậm hơn 5.1x lần so với việc khởi tạo một tuple.
Ví dụ 3-7. So sánh thời gian khởi tạo một list với một tuple
>>> %timeit l = [0,1,2,3,4,5,6,7,8,9]
1000000 loops, best of 3: 285 ns per loop
>>> %timeit t = (0,1,2,3,4,5,6,7,8,9)
10000000 loops, best of 3: 55.7 ns per loop
Wrap-Up
Qua chương này, chúng ta đã biết được những kiến thức cơ bản về List và Tuple. Trong chương sau, chúng ta sẽ tìm hiểu về Dictionary và Set 
All rights reserved
