Hiểu và ứng dụng HNSW trong tìm kiếm ngữ nghĩa với embedding
Trong các hệ thống AI xử lý ngôn ngữ tự nhiên, việc biểu diễn văn bản dưới dạng vector là bước nền tảng để mô hình có khả năng đánh giá mức độ liên quan giữa các câu truy vấn và tập dữ liệu. Khi khối lượng embedding tăng lên hàng triệu điểm, bài toán tìm kiếm lân cận không còn đơn giản, đặc biệt khi yêu cầu độ trễ thấp.
HNSW (Hierarchical Navigable Small World) hiện được xem là một trong những thuật toán Approximate Nearest Neighbor (ANN) hiệu quả nhất cho bài toán này, đặc biệt trong bối cảnh vector database được ưu tiên sử dụng trong RAG, chatbot, hệ thống phân tích và AI Agent.
Vai trò của semantic search trong hệ thống AI
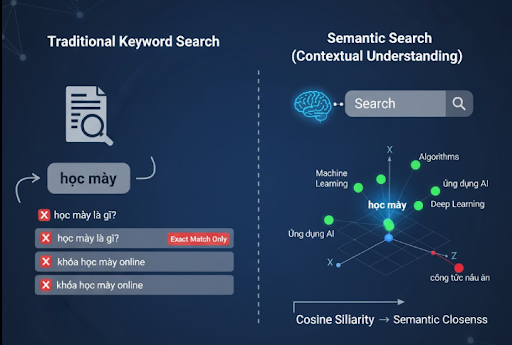
Tìm kiếm ngữ nghĩa khác với đối sánh từ khóa truyền thống nhờ khả năng hiểu:
- Ý định của câu truy vấn
- Ngữ cảnh
- Các mối quan hệ ngữ nghĩa không xuất hiện trực tiếp trong văn bản
Ví dụ, truy vấn “học máy” có thể khớp với nội dung “Machine Learning”, “thuật toán học có giám sát”, “AI dùng dữ liệu để học”…
Để đạt được điều này, văn bản cần được chuyển đổi sang các vector đa chiều (embedding). Khoảng cách giữa các vector, cosine similarity, dot product hoặc L2, thể hiện mức độ tương đồng về ý nghĩa giữa các câu.
Embedding hoạt động như thế nào?
Embedding được sinh ra từ mô hình deep learning, ánh xạ văn bản vào không gian nhiều chiều sao cho các câu có ý nghĩa gần nhau được gom lại thành các cụm yếu tố ngữ nghĩa.
Ví dụ:
- “Mua laptop ngân sách thấp” và “Laptop giá mềm cho sinh viên” → cùng cụm
- Hai câu không liên quan → cách xa nhau
Một số mô hình tạo embedding hiệu quả
- OpenAI Text-Embedding-3 Large – độ chính xác cao, phù hợp các pipeline RAG.
- SBERT / Sentence-Transformers – mã nguồn mở, chạy tốt môi trường on-premise.
- E5 / Instructor – tối ưu cho nhiệm vụ truy xuất ngữ nghĩa.
Ví dụ tạo embedding với SBERT:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
vectors = model.encode(["Tối ưu HNSW", "Semantic search trong RAG"])
Kết quả là mảng vector numpy dùng để index vào các vector database.
Vector Database và nhu cầu ANN
Khi tập dữ liệu đạt mức hàng triệu vector, brute-force search O(n) trở nên không khả thi. Các hệ quản trị vector như FAISS, Milvus, Weaviate, Pinecone… được xây dựng để thực hiện:
- Tìm kiếm top-k nhanh (thường <50 ms)
- Tối ưu bộ nhớ
- Lưu trữ và mở rộng theo chiều ngang
- Hỗ trợ các thuật toán ANN: IVF, HNSW, PQ…
FAISS đặc biệt mạnh trong môi trường local hoặc self-hosted nhờ khả năng index vector rất lớn và GPU acceleration.
HNSW – thuật toán ANN mạnh nhất hiện nay
Cơ chế cốt lõi
HNSW xây dựng một cấu trúc đồ thị nhiều tầng:
- Các tầng trên chứa ít điểm, liên kết thưa, hỗ trợ điều hướng nhanh.
- Các tầng dưới đặc hơn, đảm nhiệm tìm kiếm chính xác.
- Khi truy vấn, thuật toán bắt đầu từ tầng trên cùng, tìm điểm gần nhất theo chiến lược greedy, sau đó xuống từng tầng để tinh chỉnh.
Kết quả:
- Thời gian tra cứu giảm xuống mức O(log N)
- Độ chính xác rất cao (~0.95+)
- Tốc độ vượt trội so với IVF, Flat trong nhiều kịch bản.
Ví dụ hoạt động với FAISS
import faiss
import numpy as np
dim = 768
index = faiss.IndexHNSWFlat(dim, 32)
index.hnsw.efConstruction = 200
index.hnsw.efSearch = 64
index.add(np.array(vectors))
D, I = index.search(np.array([query_vector]), 5)
print(I)
Ưu – Nhược điểm của HNSW
Ưu điểm
- Tốc độ truy vấn cực nhanh (ms-level)
- Độ chính xác cao trong ANN
- Chèn dữ liệu động tốt
- Mở rộng linh hoạt cho RAG / realtime inference
Nhược điểm
- Tiêu tốn RAM vì lưu đồ thị nhiều tầng
- Tuning tham số (M, efConstruction, efSearch) quyết định chất lượng
- Không phù hợp dataset quá lớn (>100M) nếu không có phần cứng mạnh
Lựa chọn chiến lược index tối ưu
| Kiểu index | Đặc điểm | Khi nên dùng |
|---|---|---|
| Flat | Chính xác tuyệt đối, chậm | Dataset nhỏ, debugging |
| IVF | Phân cụm, tốc độ tốt | Dataset hàng triệu vector |
| HNSW | Tìm kiếm nhanh, hiệu suất cao | RAG, chatbot, realtime |
| PQ/OPQ | Giảm kích thước vector | RAM hạn chế, dataset lớn |
HNSW + PQ thường là lựa chọn cân bằng giữa tốc độ và dung lượng.
Kỹ thuật tối ưu hóa HNSW
1. Chuẩn hóa vector
faiss.normalize_L2(vectors)
Giúp cosine similarity phản ánh chính xác hơn.
2. Giảm chiều vector
PCA/UMAP từ 1536 → 256 chiều có thể tăng tốc đáng kể mà chất lượng gần như không giảm.
3. Reranking
Sau khi lấy top-k từ HNSW, rerank bằng cross-encoder để nâng chất lượng kết quả truy vấn.
4. Query batching
Nếu AI Agent xử lý nhiều truy vấn đồng thời → gộp batch sẽ giúp GPU tối ưu throughput.
Vai trò của HNSW trong RAG & AI Agent
Pipeline RAG chuẩn:
- Người dùng gửi câu hỏi
- Hệ thống chuyển câu truy vấn thành embedding
- HNSW index truy xuất các đoạn văn bản liên quan
- LLM (GPT, Claude, Mistral…) tạo câu trả lời dựa trên ngữ cảnh
Tốc độ và độ chính xác của HNSW có ảnh hưởng trực tiếp đến:
- Quality của câu trả lời
- Latency của hệ thống
- Chi phí inference
Benchmark thực tế
| Thuật toán | Dataset 1M vector | Latency | Recall@10 |
|---|---|---|---|
| Flat | ~1200 ms | 1.0 | |
| IVF | ~60 ms | 0.85 | |
| HNSW | ~25 ms | ~0.95 |
→ HNSW đạt hiệu suất tối ưu nhất trong hầu hết các workload yêu cầu tốc độ + chất lượng.
Kết luận
HNSW là cấu phần quan trọng để xây dựng các hệ thống tìm kiếm ngữ nghĩa, chatbot doanh nghiệp, RAG engine hoặc bất kỳ ứng dụng AI nào phụ thuộc vào việc truy xuất dữ liệu nhanh và chính xác.
Nếu bạn đang phát triển hệ thống AI có quy mô lớn, hãy thử kết hợp embedding + HNSW trên FAISS hoặc ChromaDB. Việc tinh chỉnh đúng cấu hình (M, efConstruction, efSearch) và áp dụng thêm kỹ thuật như PQ, normalization hay reranking sẽ đem lại sự khác biệt rõ rệt về tốc độ và chất lượng truy vấn.
Nguồn tham khảo: https://bizfly.vn/techblog/hieu-va-ung-dung-hnsw-trong-tim-kiem-ngu-nghia-voi-embedding.html
All rights reserved
