HBase: Overview, Architecture và Data Flow
Bài đăng này đã không được cập nhật trong 4 năm
HBase là 1 hệ cơ sở dữ liệu phân tán, mã nguồn mở được xây dựng dựa trên Apache Software. Ban đầu, nó được gọi là Google Big Table, sau đó được đổi thành Hbase và được viết bởi ngôn ngữ Java. Hbase có thể lưu trữ lượng lớn data.
Tính năng độc đáo của HBase
- HBase được sử dụng rộng rãi cho các phương thức đọc và viết ngẫu nhiên
- HBase lưu trữ số lượng lớn các dữ liệu
- Cung cấp khả năng mở rộng tuyến tính
- Phù hợp để đọc và ghi các phương thức
- Hỗ trợ chuyển đổi dự phòng tự động giữa các Region Servers
- Các lớp cơ sở thuận tiện để hỗ trợ công việc Hadoop MapReduce trong các bảng HBase
- Dễ dàng sử dụng Java API để truy cập client
- Chặn bộ nhớ cache và bộ lọc Bloom cho các truy vấn real-time
- Thuộc tính truy vấn đẩy qua các bộ lọc phía máy chủ
Tại sao chọn HBase?
Một table cho một ứng dụng web có thể bao gồm hàng tỷ row. Nếu chúng ta muốn tìm kiếm một hàng cụ thể từ số lượng lớn dữ liệu như vậy, HBase là sự lựa chọn lý tưởng khi truy vấn thời gian tìm kiếm ít hơn. Hầu hết các ứng dụng phân tích trực tuyến đều sử dụng HBase. Các mô hình dữ liệu quan hệ truyền thống không đáp ứng các yêu cầu về hiệu năng. Những hạn chế hiệu suất và chế biến này đã được HBase khắc phục.
Tầm quan trọng của cơ sở dữ liệu NoSQL trong Hadoop
Trong phân tích dữ liệu lớn, Hadoop đóng một vai trò quan trọng trong việc giải quyết các vấn đề business điển hình bằng cách quản lý bộ dữ liệu lớn và đưa ra các giải pháp tốt nhất. Trong hệ sinh thái Hadoop, mỗi thành phần đóng vai trò đặc biệt trong việc:
- Xử lí dữ liệu
- Xác nhận dữ liệu
- Lưu trữ dữ liệu
Các loại lưu trữ NoSQL khác
Một số mô hình NoSQL có mặt trên thị trường là Cassandra, MongoDB và CouchDB. Mỗi mô hình này có các cơ chế lưu trữ khác nhau.
Sự khác biệt giữa HBase và các mô hình NoSQL khác
HBase lưu trữ dữ liệu dưới dạng các cặp key/value trong một mô hình cột. Trong mô hình này, tất cả các cột được nhóm lại với nhau thành các nhóm cột. HBase cung cấp mô hình dữ liệu linh hoạt và độ trễ thấp để truy cập vào một lượng nhỏ dữ liệu được lưu trong bộ dữ liệu lớn. HBase ở bên trên của Hadoop sẽ làm tăng thông lượng và hiệu suất của phân cụm được thiết lập. Đổi lại, nó giúp cho việc đọc và ghi nhanh hơn.
HBase được sử dụng ở đâu?
- Công nghiệp Viễn thông
- Công nghiệp Banking
Cơ chế lưu trữ trong Hbase
HBase là một cơ sở dữ liệu theo cột và dữ liệu được lưu trữ trong bảng. Các bảng được sắp xếp bởi RowId. Như được trình bày dưới đây, HBase có RowId, collect một vài Column Family có trong bảng:
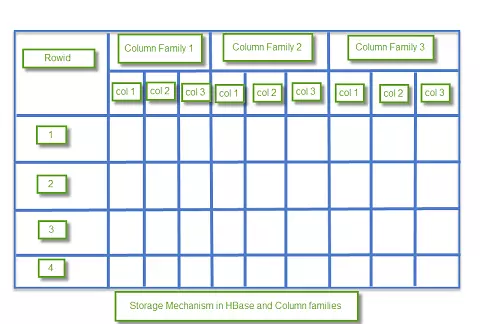 Các Column Family có trong lược đồ là các cặp key-value. Column Family có nhiều cột (col). Giá trị col được lưu trữ trong bộ nhớ đĩa. Mỗi ô của bảng có dữ liệu Meta riêng như time stamp và các thông tin khác.
Các thuật ngữ:
Các Column Family có trong lược đồ là các cặp key-value. Column Family có nhiều cột (col). Giá trị col được lưu trữ trong bộ nhớ đĩa. Mỗi ô của bảng có dữ liệu Meta riêng như time stamp và các thông tin khác.
Các thuật ngữ:
- Table: Collect tất cả các row
- Row: Collect tất cả các column family
- Column Family: Collect tất cả các cột (col)
- Column: Collect các cặp key-value
- Namespace: Logical grouping of tables.
- Cell: Bộ {row, column, version} xác định một cell trong Hbase
Hbase bao gồm những gì?
Tập các table
- Mỗi table bao gồm nhiều row.
- Mỗi row được xác định bởi 1 rowkey duy nhất. (tương đương với primaryKey trong CSDL thông thường).
- Mọi truy cập vào các bảng Hbase đều phải sử dụng Khóa chính
- Các row trong 1 table luôn được sắp xếp theo thứ tự từ điển theo rowkey.
- Mỗi row bao gồm nhiều columns khác nhau.
- Nhiều column được gộp thành column families.
- Column families được khai báo dưới dạng ”families: qualifier” families là tên của columns families qualifier để xác định column
- Column qualifier gần như là không giới hạn nội dung, độ dài , kiểu dữ liệu. Dữ liệu có thể được thêm không hạn chế vào column qualifier. Đây chính là một trong những yếu tố làm việc lưu trữ dữ liệu HBase rất linh hoạt và mềm dẻo.
Kiến trúc Hbase và Component quan trọng của nó
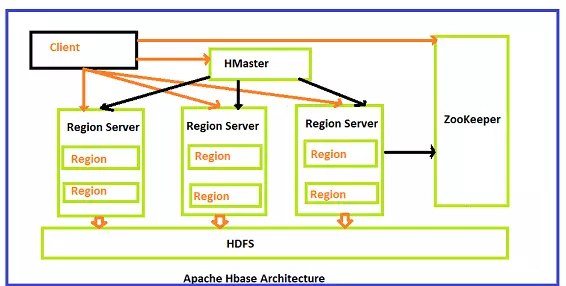 Kiến trúc Hbase gồm 3 component chính:
Kiến trúc Hbase gồm 3 component chính:
- Hmaster: thành phần phản lý hệ thống HMaster là thành phần trung tâm trong kiến trúc của HBase. HMaster giám sát tất cả các Region Server thuộc cluster. Tất cả các thay đổi liên quan đến metadata đều thực hiện thông qua HMaster Những vai trò quan trọng nhất được thực hiện bởi Hmaster: – Table : createTable, removeTable, enable, disable – ColumnFamily : add Column, modify Column – Region : move, assign
- Hregionserver: quản lý và lưu trữ các region HRegionServer chịu trách nhiệm quản lý các region. Khi Region server nhận writes and read requests từ client, nó sẽ assign request cho region riêng biệt, nơi mà đang chứa column family. Tuy nhiên client có thể trực tiếp liên lạc với Hregion servers, mà không cần sự cho phép của HMaster. Hregions: chứa 2 component chính là Memstore và Hfile HRegions là thành phần kiến trúc cơ sở của Hbase cluster. Bao gồm 2 thành phần chính là Memstore và Hfile. Đây chính là nơi lưu trữ dữ liệu của các table.
- Zookeeper: lưu trữ các metadata, region info
Data flow trong Hbase
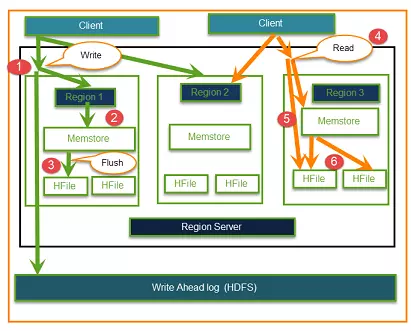 Write operations
Step 1: Client muốn write data, tạo kết nối lần đầu tiên với Regions server và sau đó là regions.
Step 2: Regions liên lạc với memstore, lưu lại liên kết với column family.
Step 3: Dữ liệu trước tiên sẽ được lưu trữ tại Memstore. Tại đây dữ liệu sẽ được sắp xếp (sorted) trước khi chuyển tới HFile.
Có 2 lý do chính cho việc sử dụng Memstore là :
– Hệ thống lưu trữ dữ liệu phân tán dựa trên row Key nên cần sắp xếp trước khi lưu trữ.
– Tối ưu hóa luồng ghi dữ liệu khi sử dụng kiến trúc The Log-Structured Merge Tree
Read operations
Step 4: Client muốn đọc data từ Regions
Step 5: Client có thể trực tiếp truy tập tới Mem store và yêu cầu dữ liệu.
Step 6: Client get data từ HFile.
Write operations
Step 1: Client muốn write data, tạo kết nối lần đầu tiên với Regions server và sau đó là regions.
Step 2: Regions liên lạc với memstore, lưu lại liên kết với column family.
Step 3: Dữ liệu trước tiên sẽ được lưu trữ tại Memstore. Tại đây dữ liệu sẽ được sắp xếp (sorted) trước khi chuyển tới HFile.
Có 2 lý do chính cho việc sử dụng Memstore là :
– Hệ thống lưu trữ dữ liệu phân tán dựa trên row Key nên cần sắp xếp trước khi lưu trữ.
– Tối ưu hóa luồng ghi dữ liệu khi sử dụng kiến trúc The Log-Structured Merge Tree
Read operations
Step 4: Client muốn đọc data từ Regions
Step 5: Client có thể trực tiếp truy tập tới Mem store và yêu cầu dữ liệu.
Step 6: Client get data từ HFile.
Trong bài tiếp theo, tôi sẽ trình bày về install HBase, HBase Shell và một vài command. Refer: https://www.guru99.com/hbase-architecture-data-flow-usecases.html https://vietnamlab.vn/blog/2016/09/26/tong-quan-ve-hbase/
All rights reserved
