Hash index trong SQL
Bài đăng này đã không được cập nhật trong 7 năm
Chào các bạn, hẳn khi làm việc với SQL các bạn đều đã biết về khái niệm index. Index giúp tăng hiệu năng cho SQL, giúp cho những câu truy vấn tìm kiếm của chúng ta được nhanh hơn rất nhiều.
Vậy index nó hoạt động như thế nào để có thể truy vấn nhanh như vậy? Về cơ bản, index được lưu trữ có cấu trúc và áp dụng các kỹ tìm kiếm hiệu quả, giúp việc tìm tiếm diễn ra nhanh nhất có thể, với độ phức tạp nhỏ, thay vì phải đi scan toàn bộ records như các tìm kiếm thông thường.
Mặc định storage engines InnoDB của MySQL sẽ sử dụng cấu trúc data B-Tree ở lưu trữ index. B-Tree là một cấu trúc data được xây dựng tổng quát hóa từ cây tìm kiếm nhị phân và cũng khá là nổi tiếng.
Tuy nhiên bài viết hôm nay mình xin được giới thiệu về Hash index, một cấu trúc data được storage engines MEMORY của MySQL sử dụng.
Hash index là gì?
Hash index sử dụng kỹ thuật hashing, được xây dựng trên một hash table để lưu trữ và tìm kiếm dữ liệu.
Hash table là một cấu trúc dữ liệu mà có thể cho phép thực hiện việc map các cặp keys, values. Hash Table sử dụng Hash function để tính toán một index vào một mảng các buckets, từ đó có thể tìm thấy các giá trị mong muốn.
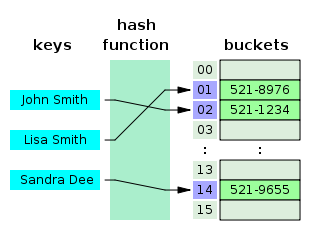
Ví dụ, chúng ta có một table như sau
CREATE TABLE testhash (
fname VARCHAR(50) NOT NULL,
lname VARCHAR(50) NOT NULL,
KEY USING HASH(fname)
) ENGINE=MEMORY;
chứa data:
| fname | lname |
|---|---|
| Arjen | Lentz |
| Baron | Schwartz |
| Peter | Zaitsev |
| Vadim | Tkachenko |
Giả sử, chúng ta có một hash function f(), tính toán các giá trị của trường fname được đánh index và trả về kết quả như sau:
f('Arjen') = 2323
f('Baron') = 7437
f('Peter') = 8784
f('Vadim') = 2458
Lúc này, buckets sẽ lưu trữ như sau:
| Index | Value |
|---|---|
| 2323 | Pointer to row 1 |
| 2458 | Pointer to row 4 |
| 7437 | Pointer to row 2 |
| 8784 | Pointer to row 3 |
Với câu truy vấn
SELECT lname FROM testhash WHERE fname='Peter';
Storage Engine sẽ dùng hash function f() ở trên và return f('Peter') = 8784 để tìm đến chính xác record chúng ta mong muốn.
Kỹ thuật Hashing được chia thành 2 loại là: Static Hashing và Dynamic Hashing
Static Hashing
Trong static hashing, với mỗi key được cung cấp, hash function luôn tính toán và trả về một giá trị địa chỉ giống nhau. Sẽ không có bất kỳ thay đổi nào với địa chỉ bucket này.
Các hoạt động trong static hashing:
- Thêm mới: Khi một record được thêm mới, hash function sẽ generate một bucket address mới
- Tìm kiếm: Khi muốn tìm kiếm record với key đã được đánh index, hash function sẽ sử dụng key đó là params để tính toán và trả về địa chỉ của bucket tương ứng, trong bucket này sẽ chứa value là tất cả con trỏ tới record
- Xóa: Khi muốn xóa một record, hash function sẽ tính toán và tìm bản ghi cần xóa và sau đó xóa nó khỏi bộ nhớ
Bây giờ bạn muốn thêm mới một record nhưng lúc này địa chỉ bucket được hash function tính toán đã được sử dụng. Lúc này sẽ xử lý như thế nào?
Có một số phương pháp cung cấp để giải quyết vấn đề này:
Open Hashing
Với Open hashing, data block phù hợp kế tiếp sẽ được sử dụng để thêm mới record thay vì ghi đè lên address cũ.
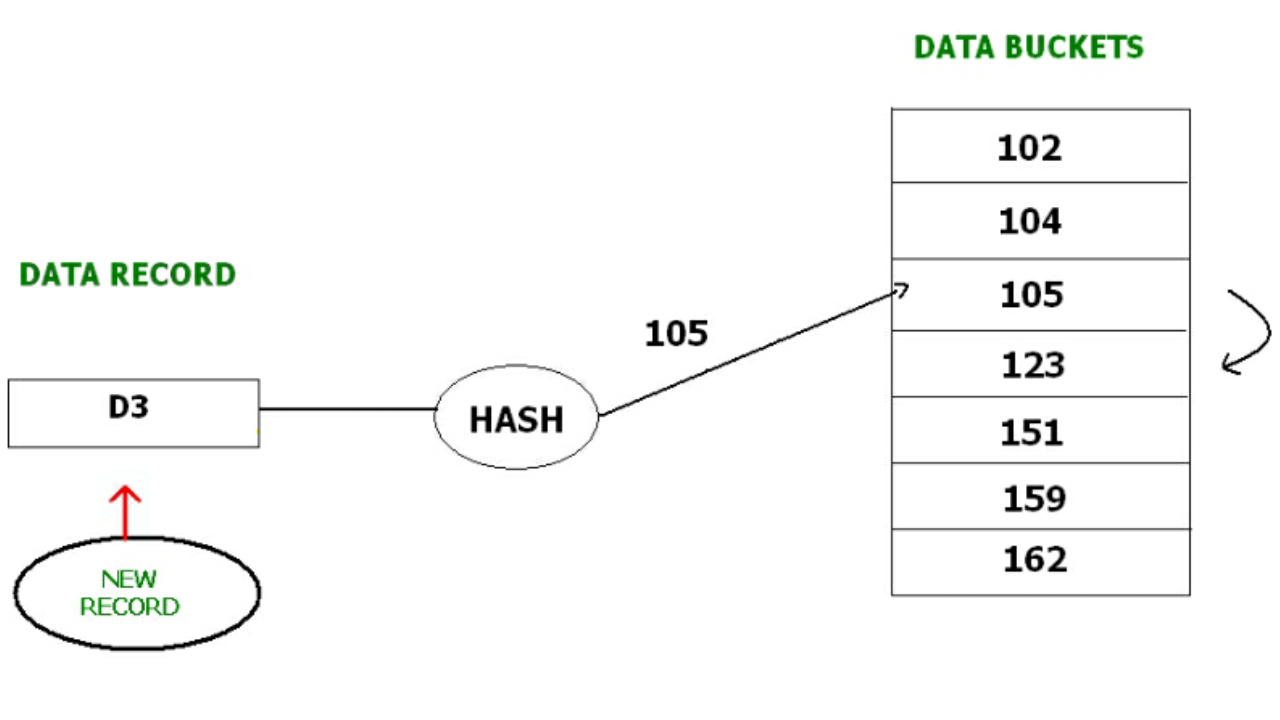
Ví dụ, D3 là record muốn thêm vào, nhưng hash function lại tính toán đến địa chỉ 105 đã được sử dụng. Lúc này, hệ thống sẽ tìm kiếm để bucket khả dụng tiếp theo là 123, và assign D3 cho nó
Closed hashing
Với Closed hashing, một cái data bucket mới sẽ được phân bố cùng địa chỉ và được liên kết sau bucket cũ.
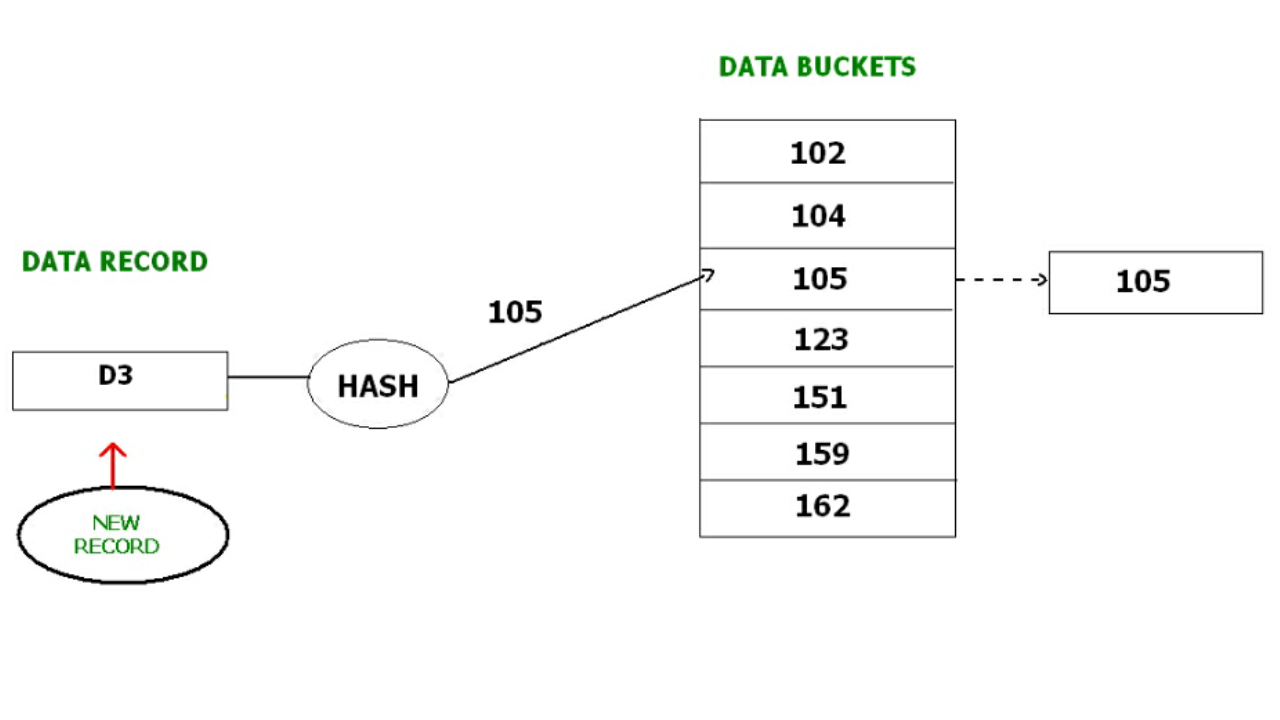
Ví dụ, chúng ta muốn thêm D3 vào table. Nhưng hash function tính toán địa chỉ cho D3 là 105 và bucket này đã được sử dụng. Lúc này, một butket mới sẽ được thêm vào và liên kết với butket 105, D3 sẽ được assign cho bucket này.
Dynamic Hashing
Hạn chế của Static Hashing là không mở rộng hoặc thu hẹp buckets một cách linh hoạt khi kích thước dữ liệu của database thay đổi.
Với Dynamic Hashing, các data buckets sẽ được tăng hoặc giảm linh hoạt dựa theo sự theo đổi kích thước của database.
Trong Dynamic hashing, hash function sẽ tính toán và tạo ra một tập rất nhiều các giá trị.
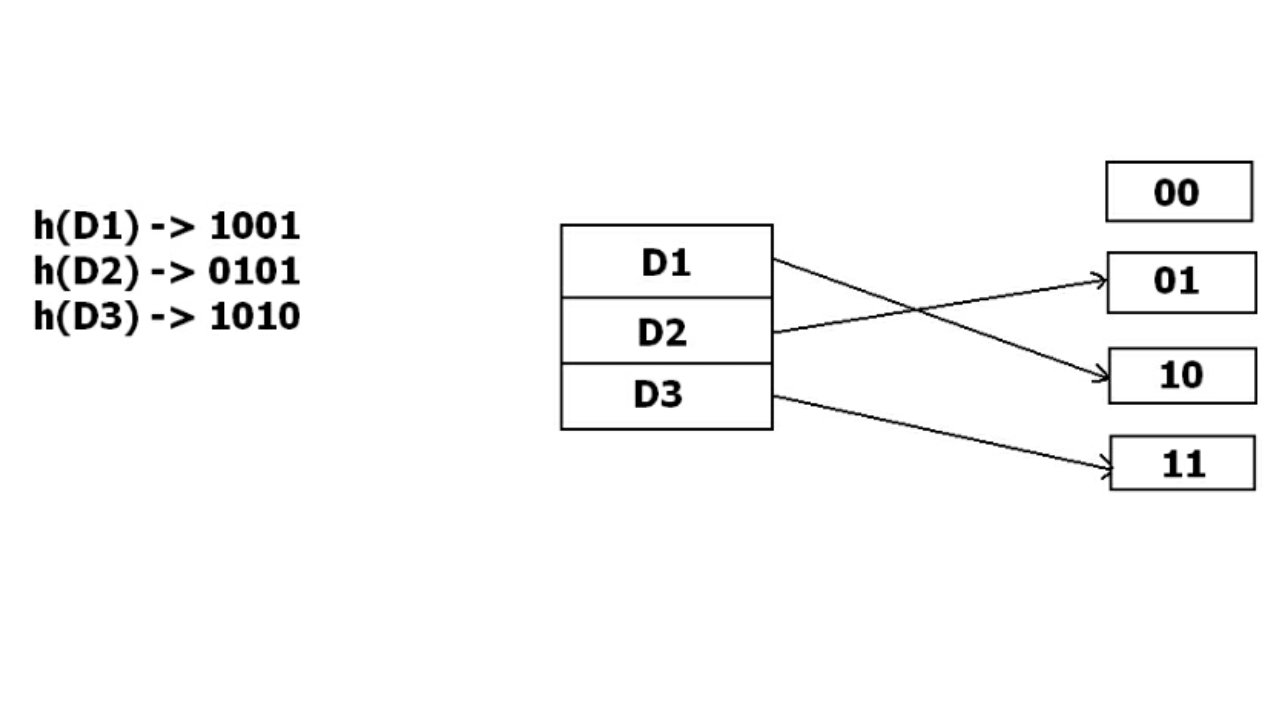
Ví dụ, chúng ta có 3 key D1, D2, D3, hash function sẽ generate ra 3 address tương ứng 1001, 0101, 1010. Với phương pháp lưu trữ này, chỉ xét một phần của địa chỉ nêu trên, lúc đầu buckets chỉ sử dụng một bit để lưu trữ data. Vì vậy nó sẽ cố gắng load 3 giá trị kia vào địa chỉ 0 hoặc 1
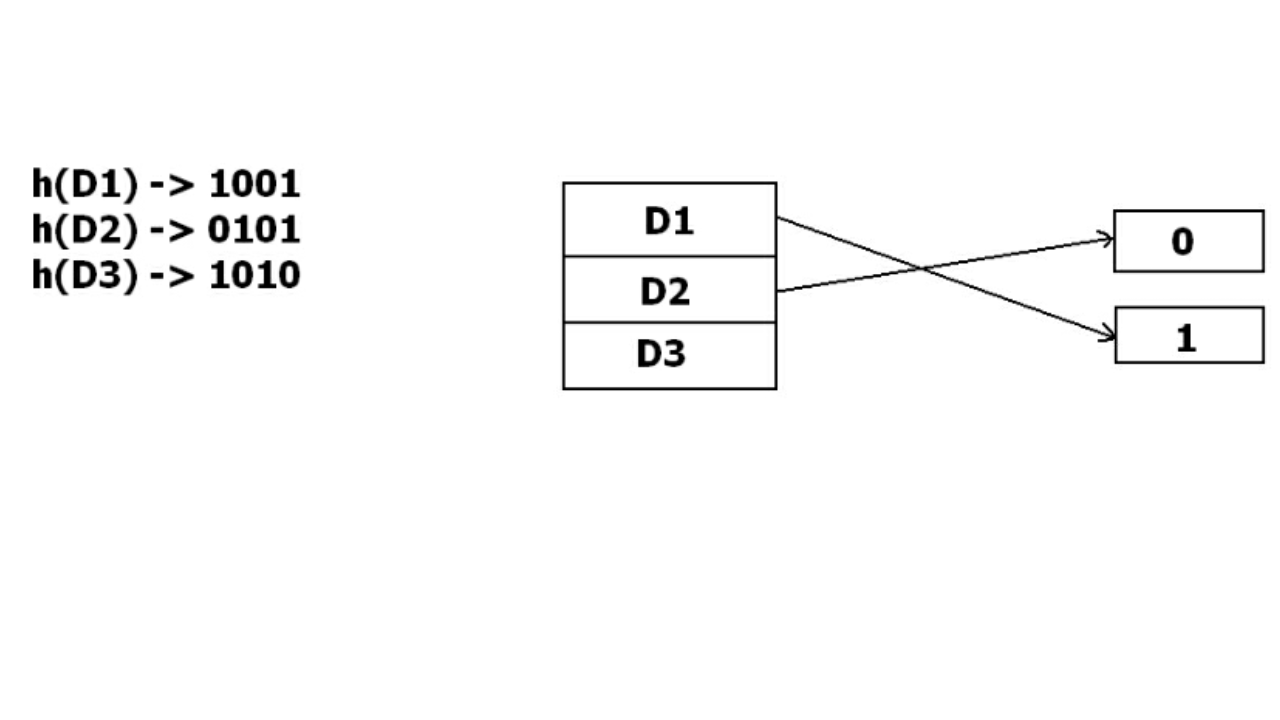
Vậy thì D3 sẽ lưu ở đâu?
Lúc này buckets sẽ được tự động tăng thêm 1 bit và nó sẽ sử dụng 2 bit để lưu trữ, update những giá trị đã tồn tại vào buckets 2 bit và lưu lại giá trị mới thêm vào
Nhận xét
Về ưu điểm của Hash index thì chắc hẳn chúng ta có thể dễ dàng nhận thấy đó là việc tính toán index và tìm kiếm dữ liệu sẽ rất nhanh. Tuy nhiên, có một số hạn chế có thể kể đến như:
- Không thể sorting data
- Không thể tìm kiếm kiểu wildcard, key tìm kiếm phải chính xác thì hash function mới tính toán trả về kết quả chính xác
- Chỉ có thể hỗ trợ tìm kiếm =, IN(), <=>. Không thể hỗ trợ tìm kiếm trong phạm vi.
Bài viết của mình đã giới thiệu sơ qua về một kỹ thuật được sử dụng để lưu trữ index trong SQL. Mặc dù Hash index nó không được sử dụng nhiều lắm nhưng hi vọng các bạn có được một cái nhìn tổng quát. Thank for your reading!
All rights reserved
