Giới thiệu về Shards và Replicas trong Elasticsearch
Chào các bạn, hôm nay, mình muốn chia sẻ với các bạn về hai khái niệm quan trọng trong Elasticsearch mà bất kỳ ai làm việc với ES đều cần phải hiểu rõ: Shards và Replicas.
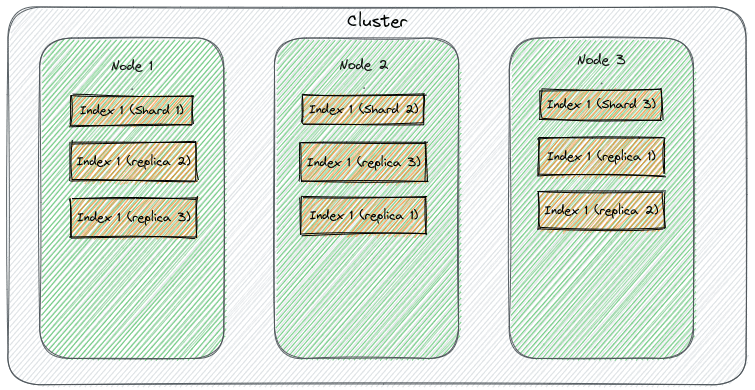
Shards là gì?
Khi làm việc với Elasticsearch, bạn sẽ thường xuyên nghe đến thuật ngữ shard. Vậy shard là gì? Đơn giản mà nói, shard là một phần nhỏ của index.
Mỗi index trong Elasticsearch có thể được chia thành nhiều shard, và mỗi shard là một "đơn vị độc lập" chứa một phần dữ liệu của index đó.
Tại sao lại cần Shards?
Elasticsearch là một hệ thống phân tán, có nghĩa là dữ liệu được chia thành nhiều phần nhỏ hơn gọi là shards để có thể lưu trữ trên nhiều node khác nhau. Mỗi shard về cơ bản là một chỉ mục (index) nhỏ có đầy đủ các đặc điểm như một chỉ mục lớn.
Mỗi index trong Elasticsearch được chia thành nhiều shards để:
-
Tăng khả năng mở rộng (Scalability): Khi dữ liệu của bạn ngày càng lớn, việc lưu trữ toàn bộ dữ liệu trên một máy chủ duy nhất sẽ trở nên khó khăn. Bằng cách chia index thành nhiều shard, bạn có thể phân phối dữ liệu trên nhiều máy chủ khác nhau, giúp hệ thống có khả năng mở rộng tốt hơn.
-
Hiệu suất (Performance): Khi bạn thực hiện tìm kiếm hoặc truy vấn dữ liệu, Elasticsearch sẽ phân tán các yêu cầu này đến các shard khác nhau. Điều này giúp tăng tốc độ xử lý vì các shard có thể làm việc song song.
Mỗi shard thực tế là một Lucene index riêng biệt, do đó, Elasticsearch chỉ là một lớp quản lý giúp phân tán và truy vấn dữ liệu một cách hiệu quả.
Ví dụ về Shards
Giả sử bạn có một index chứa 1 triệu tài liệu. Nếu bạn chia index này thành 5 shard, mỗi shard sẽ chứa khoảng 200,000 tài liệu. Khi bạn thực hiện một truy vấn, Elasticsearch sẽ tìm kiếm trên cả 5 shard cùng lúc, giúp giảm thời gian truy vấn.
Replicas là gì?
Nếu shard là một phần của index, thì replica là một bản sao của shard. Mỗi shard có thể có một hoặc nhiều replica, và các replica này được sử dụng để đảm bảo tính sẵn sàng cao (high availability) và độ tin cậy của dữ liệu.
Tại sao lại cần Replicas?
-
Tính sẵn sàng cao (High Availability): Nếu một shard bị lỗi hoặc máy chủ chứa shard đó gặp sự cố, các replica sẽ đảm nhận vai trò thay thế. Điều này giúp hệ thống của bạn vẫn hoạt động bình thường ngay cả khi có sự cố xảy ra.
-
Cân bằng tải (Load Balancing): Các replica không chỉ dùng để dự phòng mà còn có thể tham gia vào việc xử lý các yêu cầu đọc (read requests). Điều này giúp phân tán tải và tăng hiệu suất của hệ thống.
Ví dụ về Replicas
Giả sử bạn có một index với 5 shard và mỗi shard có 1 replica. Điều này có nghĩa là bạn sẽ có tổng cộng 10 shard (5 shard chính và 5 replica). Khi một shard chính gặp sự cố, replica của nó sẽ tiếp quản và đảm bảo rằng dữ liệu vẫn có thể được truy cập.
Cách hoạt động của Shards và Replicas
Trong thực tế, bạn sẽ thường xuyên kết hợp cả shard và replica để tối ưu hóa hiệu suất và độ tin cậy của hệ thống. Ví dụ, bạn có thể cấu hình một index với 3 shard và mỗi shard có 2 replica. Điều này có nghĩa là bạn sẽ có tổng cộng 9 shard (3 shard chính và 6 replica).
Cấu hình Shards và Replicas
Khi tạo một index mới trong Elasticsearch, bạn có thể chỉ định số lượng shard và replica thông qua cấu hình:
PUT /my_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
number_of_shards: 3: Index sẽ được chia thành 3 shards chính.number_of_replicas: 2: Mỗi shard chính sẽ có 2 bản sao, tức là tổng cộng 6 shards replica.
Cách Elasticsearch phân phối Shards và Replicas
Khi một index được tạo, Elasticsearch sẽ tự động phân bổ các shards và replicas trên các node trong cluster. Dưới đây là cách hoạt động cụ thể:
- Shard Primaries (Shards Chính): Elasticsearch tạo ra number_of_shards shards chính và gán chúng cho các node khả dụng.
- Replica Allocation (Phân bổ Replica): Elasticsearch tạo các bản sao của từng shard chính và phân tán chúng trên các node khác nhau để đảm bảo tính sẵn sàng.
- Cluster Rebalancing (Cân bằng Cluster): Khi một node mới được thêm vào hoặc một node cũ bị mất, Elasticsearch tự động điều chỉnh lại vị trí của shards để đảm bảo hiệu suất và khả năng chịu lỗi tối ưu.
Ví dụ:
- Nếu cluster có 3 nodes và index có 3 shards chính với 1 replica mỗi shard, Elasticsearch sẽ cố gắng phân bổ sao cho mỗi node chứa một shard chính và một bản sao của shard khác.
- Nếu một node bị mất, Elasticsearch sẽ tự động tái tạo các replicas bị mất trên các node còn lại để đảm bảo dữ liệu luôn khả dụng.
Hoạt động truy vấn với Shards và Replicas
- Ghi dữ liệu: Khi dữ liệu được ghi vào một shard chính, Elasticsearch sẽ tự động sao chép dữ liệu đó đến các replicas tương ứng.
- Đọc dữ liệu: Elasticsearch có thể thực hiện truy vấn tìm kiếm trên cả shard chính và replicas để cải thiện hiệu suất.
- Cân bằng tải: Nếu một shard chính quá tải, Elasticsearch có thể chuyển một số truy vấn tìm kiếm sang replicas để giảm áp lực.
Một số lưu ý khi thiết kế Shards và Replicas
Qua nhiều năm làm việc với Elasticsearch, mình nhận thấy rằng việc cấu hình số lượng shard và replica phù hợp là rất quan trọng.
- Chọn số lượng shards hợp lý: Nếu quá nhiều shards, hệ thống sẽ tốn nhiều tài nguyên để quản lý chúng. Nếu quá ít, dữ liệu có thể bị giới hạn về khả năng mở rộng.
- Định cấu hình replicas phù hợp: Nếu hệ thống có nhiều truy vấn đọc (search-heavy), tăng số lượng replicas sẽ giúp cải thiện hiệu suất.
- Cân nhắc về scaling: Một cluster Elasticsearch có thể mở rộng bằng cách thêm node mới, và Elasticsearch sẽ tự động cân bằng shards để tối ưu hiệu suất.
Nếu bạn có quá ít shard, dữ liệu có thể không được phân phối đều, dẫn đến hiệu suất kém. Ngược lại, nếu bạn có quá nhiều shard, hệ thống có thể trở nên phức tạp và khó quản lý.
Một lời khuyên của mình là hãy bắt đầu với số lượng shard vừa phải và tăng dần khi cần thiết. Đồng thời, luôn đảm bảo rằng bạn có ít nhất một replica để đảm bảo tính sẵn sàng cao.
Kết luận
Shard và replica là hai khái niệm cốt lõi trong Elasticsearch mà bất kỳ lập trình viên nào cũng cần nắm vững. Hiểu rõ cách chúng hoạt động và cách cấu hình chúng sẽ giúp bạn xây dựng được một hệ thống Elasticsearch mạnh mẽ, hiệu suất cao và đáng tin cậy. Hiểu về shards và replicas là một trong những điều quan trọng nhất khi làm việc với Elasticsearch mà bất kỳ lập trình viên nào cũng cần nắm vững. Bằng cách cấu hình shards và replicas hợp lý, mình có thể đảm bảo hệ thống hoạt động ổn định, hiệu suất cao và có khả năng mở rộng linh hoạt.
Hy vọng bài viết này sẽ giúp ích cho các bạn trong quá trình làm việc với Elasticsearch. Nếu có bất kỳ câu hỏi nào, đừng ngần ngại để lại bình luận bên dưới. Chúc các bạn thành công!
/Son Do
All rights reserved
