
Giới thiệu về Protocol Buffers
Bài đăng này đã không được cập nhật trong 3 năm
Giới thiệu
Chào các bạn 👋👋👋, trong bài viết giới thiệu về RPC và gRPC mình có đề cập đến một khái niệm đó là Protobuf. Trong bài viết đó mình chỉ giới thiệu qua về khái niệm của nó nên bài viết này mình sẽ đi sâu giải thích về Protobuf để giúp các bạn có thể làm chủ và sử dụng vào trong thực tế. Bạn nào quan tâm bài viết trước về RPC và gRPC thì các bạn có thể tham khảo ở đây. Nếu các bạn đã sẵn sàng rồi thì cùng bắt đầu thôi!!!
Tổng quan

Khái niệm
Protocol Buffers là một ngôn ngữ dùng để mô tả cấu trúc dữ liệu tương tự như JSON hoặc XML nhưng protobuf lưu trữ dữ liệu có cấu trúc dưới dạng nhị phân một cách hiệu quả hơn, nhỏ gọn hơn và cho phép truyền dữ liệu nhanh hơn qua kết nối mạng. Nó được phát triển bởi ông lớn Google và được công bố một cách chính thức vào năm 2008.
Protobuf hỗ trợ hầu hết các loại ngôn ngữ lập trình ở hiện tại và nó không phụ thuộc vào bất kỳ nên tảng nào. Ta có thể định nghĩa dữ liệu có cấu trúc một lần (vớ i.proto file) và sử dụng cho các nền tảng khác nhau và tạo ra code của ngôn ngữ khác nhau. Nó là một giải pháp hiệu quả để tạo dữ liệu có cấu trúc cho các ứng dụng khác nhau như ứng dụng web, hệ thống gRPC,... và đặc biệt hiệu dụng trong microservices sử dụng gRPC.
Vấn đề mà protocol buffer giải quyết?
Protocol buffer hỗ trợ định dạng các gói dữ liệu có cấu trúc lên tới vài megabytes. Cấu trúc của nó phù hợp cho cả truyền dữ liệu qua đường truyền mạng và lưu trữ những dữ liệu dài hạn (long-term data). Nó còn có thể mở rộng những dữ liệu mới mà không ảnh hưởng đến những dữ liệu đã có hoặc những dữ liệu cần được cập nhật. So với dạng XML hoặc JSON thì dữ liệu của protobuf nhỏ gọn gấp 3-10 lần và được xử lý rất nhanh. Các bạn có thể tham khảo biểu đồ benchmarking giữa protobuf với JSON và XAML khi sử dụng trong Go phía bên dưới.

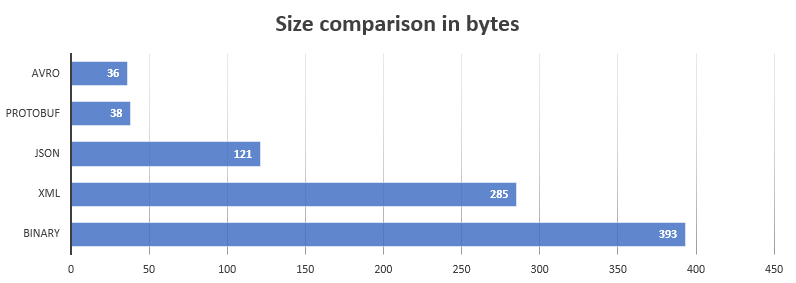
Protobuf là giao thức định dạng dữ liệu được sử dụng phổ biến nhất tại Google. Nó được sử dụng rộng rãi trong việc giao tiếp giữa các máy chủ và lưu trữ dữ liệu trên ổ đĩa. Protocol buffer message và services được định nghĩa bằng proto file. Dưới đây là một ví dụ về message:
message Person {
optional string name = 1;
optional int32 age = 2;
optional string phone = 3;
}
Lợi ích
Protocol buffer là một ý tưởng tuyệt vời có thể áp dụng vào bất kỳ tình huống nào mà ta muốn tuần tự hoá dữ liệu có cấu túc (serialize structured). Hiện tại nó thường được sử dụng để định nghĩa giao tiếp dữ liệu qua đường truyền mạng (cùng với gRPC) và để lưu trữ dữ liệu.
Mốt số ưu điểm của Protobuf có thể kể đến như:
- Lưu trữ dữ liệu một cách tối ưu
- Tốc độ encode và decode dữ liệu nhanh
- Hỗ trợ cho hầu hết các ngôn ngữ lập trình hiện tại
- Tối ưu hoá dữ liệu thông quá các class được tạo tự động từ
.protofile.
Những ngôn ngữ mà protobuf hỗ trợ có thể kể đến như:
- C++
- C#
- Java
- Kotlin
- Python
- Go
- Dart
- ...
Syntax
Khi sử dụng protobuf ta có các tuỳ chọn sau:
- Proto2: ngôn ngữ giao thức dùng để mã hoá dữ liệu có cấu trúc. Nó hỗ trợ tạo mã cho nhiều ngon ngữ như C++, Python, ...
- Proto3: là phiên bản mới nhất của Protobuf, là sự phát triển của proto2 với nhiều tính năng mới được thêm vao.
Vì Proto3 là phiên bản mới nhất nên trong bài viết này mình sẽ đưa ra những syntax của proto3 còn về proto2 các bạn có thể tham khảo tại đây.
Message
Mình sẽ đưa ra một ví dụ đơn giản về một message Person được định nghĩa trong proto3.
syntax = "proto3";
message Person {
string name = 1;
int32 id = 2;
string email = 3;
}
Nhìn vào ví dụ trên ta thấy dòng đầu tiên ta sẽ định nghĩa version của protobuf sẽ được sử dụng. Ở đây mình sử dụng version proto3. Ta có một message có tên là Person có các trường là name và email có kiểu dữ liệu là string, id có kiểu là int32. Khi định nghĩa các trường cho message thì ta sẽ bắt buộc có tên và kiểu dữ liệu.
Field numbers
Ta bắt buộc phải đánh số cho các trường của message trong file .proto từ số 1 đến 536,870,911 như ví dụ trên là mình đánh số lần lượt là 1, 2, 3. Ta có một số ràng buộc như sau:
- Các số được đánh phải là duy nhất (unique) trong các trường được định nghĩa.
- Các số từ 19000 đến số 19999 được dành riêng cho việc triển khai protobuf. Khi ta sử dụng những số này thì compiler sẽ báo lỗi.
- Ta không được sử dụng những số trong các trường reserved hoặc bất kỳ số nào được định nghĩa trong extensions.
Các con số được đánh này là không thể thay đổi khi message này đã được sử dụng bởi vì protobuf sẽ sử dụng những số này để encoding. Thay đổi những con số này đồng nghĩa với việc ta đang xoá trường đó đi và tạo một trường mới.
Ta nên sử dụng những số từ 1 đến 15 để đánh số cho các trường được định nghĩa vì những số có giá trị bé sẽ chiếm ít không gian khi format dữ liệu. Điển hình là các số từ 1 đến 15 sẽ chỉ chiếm 1 byte để encode trong khi đó các số từ 16 đến 2047 chiếm đến 2 bytes. Các bạn có thể tìm hiểu kỹ hơn phần này trong mục Protocol Buffer Encoding trên trang chủ của protobuf.
Field Rules
Những trường có message có thể có một số ràng buộc như sau:
singular: đây là rule mặc định khi ta không định nghĩa gì cả. Giá trị ban đầu của trường này phải được cung cấp nếu không field sẽ không được khởi tạo.optional: tương tự nhưsingularnhưng vớioptionalthì protobuf sẽ kiểm tra xem trường đó có được đặt giá trị hay không. Nếu trường đó được đặt giá trị thì sẽ được encoding vào dải dữ liệu. Nếu trường đó không được đăng giá trị thì sẽ không được encoding vào dài dữ liệu. Hay hiểu đởn giản trường này có thể có hoặc không có trong dữ liệu khi encoding.repeated: trường này có thể lặp lại với số lần bất kỳ.map: đây là trường kiểu có dạng key/value.
Comments
Để thêm comment vào .proto file ta sử dụng // hoặc /* ... */;
syntax = "proto3";
/* This is message Person */
message Person {
string name = 1; // Name of the person
int32 id = 2;
string email = 3;
}
Reserved Fields
Nếu ta update một message bằng cách xoá một trường bất kỳ trong nó hoặc comment trường đó ra khỏi message, những người developer trong tương lai chẳng may lại sử dụng lại những số được đánh cho các trường đã bị xoá đi đó khi cập nhật message. Điều này có thể gây ra một vài vấn đề. Để tránh xảy ra tình huống trên khi thực hiện xoá các trường trong message ta sẽ thêm số được đánh cho trường đó vào danh sách reserved . Để chắc chắn rằng với kiểu dữ liệu JSON hoặc Text vẫn được parsed ta sẽ thêm tên của trường được xoá vào danh sách reserved. Dưới đây là một ví dụ cho việc sử dụng reserved fields
message Employer {
reserved 2, 15, 9 to 11;
reserved "name", "email";
}
Trong ví dụ trên vì mình vẫn muốn khi sử dụng kiểu dữ liệu JSON hoặc text thì 2 trường name và email vẫn được parse thành dữ liệu nên mình thêm 2 trường đó vào danh sách reserved mặc dù hai trường đó đã bị xoá. Và những số đã bị xoá ở đây là 2, 15, 9 , 10, 11 .
Values Type
Protobuf hỗ trợ hầu hết kiểu dữ liệu bao gồm chuỗi số, số nguyên, float, boolean, enums, map, ... Những cú pháp này là độc lập với ngôn ngữ lập trình nên cho phép các chương trình được bởi những ngôn ngữ khác nhau có thể giao tiếp một cách đáng tin cậy. Các bạn có thể xem toàn bộ kiểu dữ liệu được hỗ trợ tại đây.
Default Values
Khi một message được phân tích nếu các trường không được gán giá trị thì ta sẽ có những giá trị mặc định sau được phân tích với từng kiểu dữ liệu:
string: empty stringbytes: empty bytesbools: giá trị sẽ là falsenumeric: giá trị mặc định là 0- Với
message, nếu không có trường nào được định nghĩa thì giá trị mặc định của nó sẽ tuỳ thuộc vào loại ngôn ngữ khi được compile
Lời kết
Qua bài viết này mình và các bạn đã cùng tìm hiểu về khái niệm, công dụng cũng như cách sử dụng của protocol buffer (protobuf). Những kiến thức trên cũng chỉ là do mình tự tìm hiểu và học từ nhiều nguồn khác nhau nếu có sai sót gì mong mọi người có thể góp ý để bài viết hoàn thiện hơn. Hy vọng qua bài viết này các bạn có thể hiểu hơn về protobuf, cách chúng hoạt động. Trong các bài viết tiếp theo mình sẽ hướng dẫn các bạn sử dụng protobuf khi triển khai hệ thống microservices để các bạn thấy rõ hơn những lợi ích mà nó mạng lại. Cảm ơn các bạn đã theo dõi đến hết bài viết ❤️.
Tham khảo
All rights reserved
