Giới thiệu về Intent Classification
Bài đăng này đã không được cập nhật trong 6 năm

- Gần đây tôi đã biết về một thứ gọi là phân loại ý định (intent classification) của người dùng cho một dự án, vì vậy tôi sẽ chia sẻ nó với tất cả các bạn và cách tạo một lớp phân loại cho nó. Phân loại ý định là một phần rất quan trọng trong hệ thống Natural Language Understanding (NLU) trong bất kỳ nền tảng chatbot nào.
- Cách tốt nhất để hiểu nó là lấy một ví dụ:
- Như tôi đã nói, phân loại ý định là một phần quan trọng của nền tảng chatbot và chúng ta đều biết rằng chatbot giống như trợ lý cho chúng ta trong cuộc sống hàng ngày. Vì vậy, giả sử bạn có một trợ lý và bạn nói với anh/cô ấy là "đặt cho bạn một chiếc taxi". Bây giờ trợ lý của bạn đã biết phải làm thế nào để trả lời cho truy vấn đó của bạn bởi vì anh/cô ấy có bộ não được đào tạo cho việc này. Nhưng làm thế nào để bạn đào tạo chatbot của mình để trả lời cho một truy vấn cụ thể. Trong trường hợp chatbot, để làm cho chúng trả lời theo truy vấn của người dùng, chúng tôi sử dụng phân loại ý định (intent classification) và các danh mục mà một chatbot phản hồi dựa trên những điều đó được gọi là các ý định (intent).
- Vì vậy, giả sử bạn đã yêu cầu đặt một chiếc taxi thì nó sẽ trả lời theo mục đó và nếu bạn yêu cầu đặt một chuyến bay thì nó cũng sẽ trả lời theo danh mục đó,...
Đưa ra vấn đề
- Tôi đã đưa ra một tập dữ liệu nhỏ gồm 1113 câu lệnh (hoặc truy vấn) với intent tương ứng của chúng và tôi được yêu cầu xây dựng một trình phân loại ý định (intent classifier) cho nó. Có tổng số 21 intent (categories/classes) trong bộ dữ liệu này.
- Tôi đã sử dụng Python , Google Colab Notebook để phát triển các thành phần này và Deep Learning để tạo ra nó.
Chuẩn bị dữ liệu
- Trong lĩnh vực Machine Learning và Deep Learning tôi nghĩ bước này là yếu tố quyết định dự án của bạn. Đơn giản hóa dữ liệu của bạn nhiều nhất có thể, từ đó mang giúp cho mô hình (model) của bạn đào tạo dễ dàng và nhanh hơn.
def load_dataset(filename):
df = pd.read_csv(filename, encoding = "latin1", names = ["Sentence", "Intent"])
intent = df["Intent"]
unique_intent = list(set(intent))
sentences = list(df["Sentence"])
return (intent, unique_intent, sentences)
Có các bước sau mà tôi đã thực hiện trong đó:
1. Làm sạch dữ liệu
"Dữ liệu giống như dầu thô. Nó có giá trị, nhưng nếu không được tinh chế thì nó thực sự không thể được sử dụng."
- Nếu bạn đang sử dụng dữ liệu thô, bạn nên làm sạch nó trước khi đưa nó vào mô hình của bạn. Để làm sạch dữ liệu chúng ta có thể sử dụng một số phương thức và thủ thuật không có phương pháp xác định.
def cleaning(sentences):
words = []
for s in sentences:
clean = re.sub(r'[^ a-z A-Z 0-9]', " ", s)
w = word_tokenize(clean)
#lemmatizing
words.append([lemmatizer.lemmatize(i.lower()) for i in w])
return words
Ở đây trước tiên tôi loại bỏ mọi dấu câu và ký tự đặc biệt (nếu có) khỏi dữ liệu sau đó tôi mã hóa các câu thành từ. Sau đó, tôi viết thường tất cả các từ và sử dụng từ vựng trên chúng. Chúng ta hãy xem xét nhanh khái niệm từ vựng và lý do tại sao tôi sử dụng nó ở đây.
1.1. Lemmatization
"Lemmatisation (hoặc lemmatization) trong ngôn ngữ học, là quá trình nhóm lại với nhau dưới các hình thức chia từ khác nhau để chúng có thể được phân tích như một từ đơn."
- Đây là định nghĩa chính thức nhưng tôi không bao giờ hiểu nó vì vậy theo tôi, từ vựng là một quá trình trong đó chúng ta có một bổ đề (từ thực tế) của một từ. Ví dụ:
lemmatizer.lemmatize("cats") ==> cat
lemmatizer.lemmatize("churches") ==> church
lemmatizer.lemmatize("abaci") ==> abacus
Đây là từ vựng và tôi đã sử dụng nó để nếu ai đó viết một từ biến thể khác đi thì bộ phân loại vẫn có thể hiểu nó và cho chúng tôi kết quả tốt nhất có thể.
2. Mã hóa
Mã hóa đầu vào
- Sau khi làm sạch dữ liệu tôi nhận được danh sách các từ của mỗi câu. Để lập chỉ mục những từ này vào để tôi có thể sử dụng chúng như là đầu vào tôi cho lớp Tokenizer của Keras.
#creating tokenizer
def create_tokenizer(words, filters = '!"#$%&()*+,-./:;<=>?@[\]^_`{|}~'):
token = Tokenizer(filters = filters)
token.fit_on_texts(words)
return token
#getting maximum length
def max_length(words):
return(len(max(words, key = len)))
#encoding list of words
def encoding_doc(token, words):
return(token.texts_to_sequences(words))
- Ở đây tôi đã sử dụng các bộ lọc sau mà bạn sẽ thấy mục đích này ở phần sau. Sau khi thực hiện, tôi có kích thước vocab là 462 và độ dài tối đa của từ là 28.
- Sau đó, tôi sử dụng padding function để làm cho chúng có độ dài bằng nhau để có thể sử dụng chúng trong mô hình.
def padding_doc(encoded_doc, max_length):
return(pad_sequences(encoded_doc, maxlen = max_length, padding = "post"))
2.2 Mã hóa đầu ra
- Đối với các kết quả đầu ra, tôi đã làm điều tương tự, đầu tiên lập chỉ mục các intent đó bằng cách sử dụng lớp Tokenizer của Keras.
output_tokenizer = create_tokenizer(unique_intent, filters = '!"#$%&()*+,-/:;<=>?@[\]^`{|}~')
- Ở đây tôi đã sử dụng filter khác với filter mặc định ở trên và khi tôi kiểm tra các đầu ra (intents) thì chúng trông như thế này:
{'commonq.assist',
'commonq.bot',
'commonq.how',
'commonq.just_details',
'commonq.name',
'commonq.not_giving',
'commonq.query',
'commonq.wait',
'contact.contact',
'faq.aadhaar_missing',
'faq.address_proof',
'faq.application_process',
'faq.apply_register',
'faq.approval_time',
'faq.bad_service',
'faq.banking_option_missing',
'faq.biz_category_missing',
'faq.biz_new',
'faq.biz_simpler',
'faq.borrow_limit',
'faq.borrow_use'}
- Sau khi xem xét các intent đầu ra, tôi phát hiện ra rằng hiện diện trong chuỗi đầu ra có "." và "_".
- Vì vậy, nếu khi tôi sử dụng bộ lọc mặc định của lớp Tokenizer, nó sẽ loại bỏ chúng và tôi chỉ nhận được "commonq" hoặc "faq". Vì vậy, để có được chuỗi như tôi đã thay đổi bộ lọc mặc định và loại bỏ "." và "_".
- Sau khi lập chỉ mục 21 ý định đó, đã đến lúc mã hóa one-hot để chúng có thể được đưa vào mô hình.
def one_hot(encode):
o = OneHotEncoder(sparse = False)
return(o.fit_transform(encode))
3. Bộ huấn luyện và xác thực
- Dữ liệu đã sẵn sàng cho mô hình, vì vậy bước cuối cùng mà tôi đã làm là chia tập dữ liệu thành tập huấn luyện và xác thực.
train_X, val_X, train_Y, val_Y = train_test_split(padded_doc, output_one_hot, shuffle = True, test_size = 0.2)
- Ở đây tôi chia tập dữ liệu thành 80% tập huấn luyện và 20% tập xác thực và chúng ta có được hình dạng dữ liệu này.
Shape of train_X = (890, 28) and train_Y = (890, 21)
Shape of val_X = (223, 28) and val_Y = (223, 21)
- Và kết thúc phần chuẩn bị dữ liệu hoặc tiền xử lý. Bây giờ tất cả những gì chúng ta phải làm là tạo một mô hình kiến trúc và đưa dữ liệu này vào đó.
Định nghĩa mô hình
- Tôi đang sử dụng ở đây Bidirectional GRU nhưng bạn có thể thử nó với các phương pháp khác nhau và thấy sự khác biệt.
def create_model(vocab_size, max_length):
model = Sequential()
model.add(Embedding(vocab_size, 128,
input_length = max_length, trainable = False))
model.add(Bidirectional(GRU(128)))
model.add(Dense(64, activation = "relu"))
model.add(Dropout(0.5))
model.add(Dense(64, activation = "relu"))
model.add(Dropout(0.5))
model.add(BatchNormalization())
model.add(Dense(21, activation = "softmax"))
return model
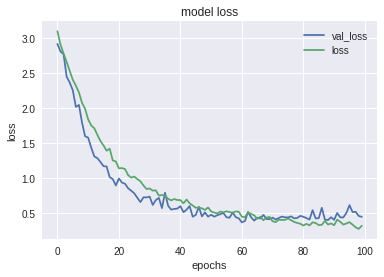
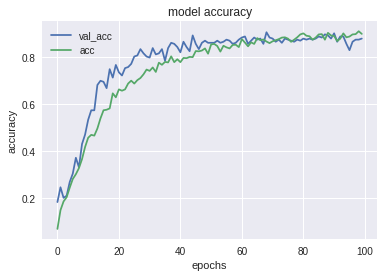
- Tôi đã đào tạo mô hình này với trình tối ưu hóa adam, batch size 16 và epochs 100. Tôi đã đạt được 89% độ chính xác đào tạo và 87% độ chính xác xác thực trong việc này.
- Dưới đây là một số biểu đồ để hình dung tốt hơn về kết quả.
-
Biểu đồ giữa training loss và validation loss:
![]()
-
Biểu đồ giữa training accuracy và validation accuracy:
![]()
-
Dự đoán
def predictions(text):
clean = re.sub(r'[^ a-z A-Z 0-9]', " ", text)
test_word = word_tokenize(clean)
test_word = [lemmatizer.lemmatize(w.lower()) for w in test_word]
test_ls = word_tokenizer.texts_to_sequences(test_word)
#Check for unknown words
if [] in test_ls:
test_ls = list(filter(None, test_ls))
test_ls = np.array(test_ls).reshape(1, len(test_ls))
x = padding_doc(test_ls, max_length)
pred = model.predict_classes(x)
return pred
- Vì vậy, bằng cách đưa ra văn bản đầu vào trong hàm trên, tôi có được lớp dự đoán:
# map an integer to a word
def word_for_id(integer, tokenizer):
for word, index in tokenizer.word_index.items():
if index == integer:
return word
return None
- Để chuyển đổi số nguyên được lập chỉ mục mà tôi nhận được từ dự đoán tôi đã sử dụng hàm trên. Nó sẽ chuyển đổi lại số nguyên thành từ bằng cách sử dụng phép so sánh chỉ mục đầu ra.
- Kết quả dự đoán:
text = "Can you help me?"
pred = predictions(text)
word = word_for_id(pred, output_tokenizer)
Tôi nhận được pre = 17 và từ liên quan đến số nguyên này là commonq.bot".
Kết luận
- Tôi hy vọng bạn thích học về phân loại ý định. Có nhiều điều mà bạn có thể tự mình thử trong việc này và có thể có được độ chính xác cao hơn. Bạn có thể sử dụng các mạng khác nhau trong mô hình, các phương pháp tiền xử lý dữ liệu khác nhau, những điều này hoàn toàn phụ thuộc vào từng người.
- Bạn có thể tham khảo source code từ nguồn: https://github.com/Dark-Sied/Intent_Classification
- Các nguồn tham khảo khác: Dialogue Intent Classification with LSTM
- Link bài viết gốc: A brief introduction to Intent Classification của tác giả Akshat Jain.
All rights reserved
