Giới thiệu về Apache Storm
Bài đăng này đã không được cập nhật trong 6 năm
1. Giới thiệu
1.1. Apache Storm là gì?
 Apache Storm là hệ thống tính toán phân tán mã nguồn mở thời gian thực miễn phí. Nếu như Hadoop xử lý dữ liệu hàng loạt (batch processing) thì Apache Storm thực hiện xử lý dữ liệu luồng (unbounded streams of data) một cách đáng tin cậy.
Apache Storm là hệ thống tính toán phân tán mã nguồn mở thời gian thực miễn phí. Nếu như Hadoop xử lý dữ liệu hàng loạt (batch processing) thì Apache Storm thực hiện xử lý dữ liệu luồng (unbounded streams of data) một cách đáng tin cậy.
Storm được phát triển bởi Nathan Marz và team BackType, sau này được Twitter mua lại vào năm 2011. Năm 2013, Twitter công khai Storm trên GitHub. Storm đã cũng tham gia vào Apache Software Foundation vào năm 2013. Apache Storm được viết bằng Java và Clojure và đã trở thành chuẩn cho các hệ thống tính toán phân tán thời gian thực.
1.2. Đặc điểm
- Có thể xử lý hơn một triệu tính toán trong một thời gian ngắn trên một node
- Tích hợp với hadoop để khai thác lượng thông tin cao hơn
- Dễ triển khai và có thể tương tác với bất kỳ ngôn ngữ lập trình nào
2. Các khía niệm
Storm đọc luồng dữ liệu thời gian thực, truyền qua một chuỗi các đơn vị xử lý nhỏ và trả về thông tin hữu ích ở đầu kia. Chuỗi xử lý được xác định bởi topology (đồ thị tính toán có hướng).
2.1. Tuple
Tuple là cấu trúc dữ liệu chính trong Storm. Đó là danh sách các yếu tố được sắp xếp. Một Tuple hỗ trợ tất cả các kiểu dữ liệu. Nói chung, nó được mô hình hóa như một tập hợp các giá trị được phân cách bằng dấu phẩy và được chuyển đến một cụm Storm.
2.2. Stream
Stream là một chuỗi các tuple không sắp xếp.

2.3.Spouts
Spouts là nguồn của stream. Một spout có thể được xem là một nơi tiếp nhận các dữ liệu đầu vào trong mô hình kiến trúc Storm. Nó đóng vai trò thu thập các dữ liệu từ hệ thống Kafka hoặc từ Twitter API hoặc bất kỳ hệ thống nào cung cấp cơ chế xử lý dữ kiện theo luồng. Spouts có trách nhiệm liên lạc với nguồn dữ liệu thực tế, nhận dữ liệu liên tục, chuyển đổi dữ liệu đó thành các luồng dữ liệu thực tế và cuối cùng gửi chúng đến các Bolts để xử lý.
ISpout là giao diện cốt lõi để thực hiện các spouts.
2.4. Bolts
Bolt là đơn vị xử lý.
Bolt nhận dữ liệu từ Spouts và xử lý để tạo ra nguồn dữ liệu mới cho các bolt khác hoặc gửi dữ liệu để lưu trữ. Bolt có khả năng chạy các hàm, lọc tuple, tổng hợp và nối các luồng, liên kết với cơ sở dữ liệu, v.v.
IBolt là giao diện cốt lõi để triển khai các Bolts.
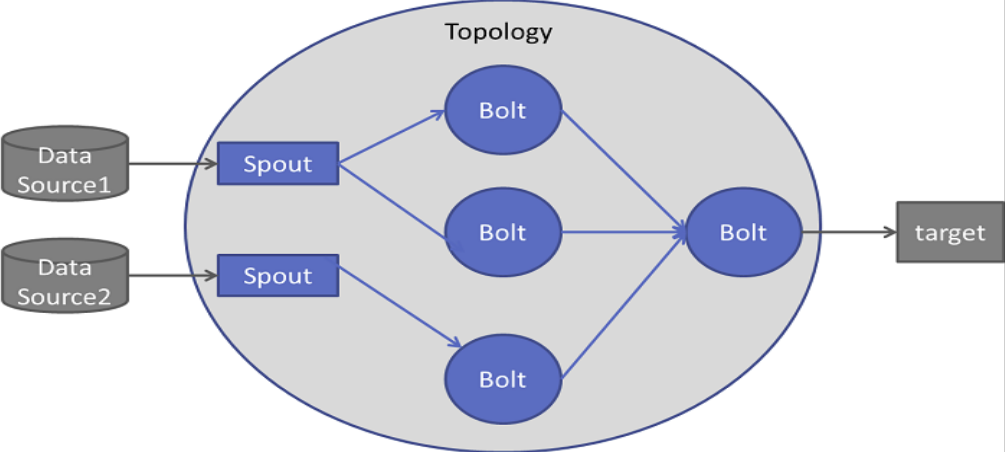
2.5. Topologies
Topology là một cấu trúc liên kết các Spouts và Bolts. Hay đơn giản, topology là một đồ thị có hướng với các đỉnh là nơi tính toán, còn các cạnh là luồng dữ liệu.
Một topology bắt đầu với spout. Spout phát ra dữ liệu đến một hoặc nhiều bolt. Bolt đại diện cho một nút trong topology có logic xử lý nhỏ nhất và đầu ra của một bolt có thể trở thành đầu vào của 1 bolt khác hoặc được gửi đến nơi lưu trữ.
Storm giữ cho cấu trúc liên kết luôn chạy, cho đến khi topology bị tắt. Công việc chính của Apache Storm là chạy các topology và sẽ chạy bất kỳ số lượng topology nào tại một thời điểm nhất định.
2.6. Tasks (tác vụ)
Mỗi spout hoặc bolt thực hiện nhiều tác vụ trên 1 cluster. Mỗi tác vụ tương ứng với một luồng thực thi. Tại một thời điểm nhất định, mỗi spout và bolt có thể chạy trong nhiều luồng riêng biệt.
2.7. Worker
Topology chạy theo cách phân tán, trên nhiều nút worker. Storm lan truyền các nhiệm vụ đồng đều trên tất cả các nút worker. Vai trò của nút worker là lắng nghe các công việc, bắt đầu hoặc ngừng công việc khi có một công việc mới đến.
2.8. Stream Grouping
Luồng dữ liệu bắt đầu từ spout đến các bolt ( hoặc từ bolt này đến bolt khác ). Stream grouping điều khiển cách các tuple được định tuyến trong một topology. Có 4 stream grouping chính:
- Shuffle Grouping
Các tuple được phân phối ngẫu nhiên trên các worker của bolt theo cách sao cho mỗi bu-lông được đảm bảo nhận được số lượng bộ dữ liệu bằng nhau.
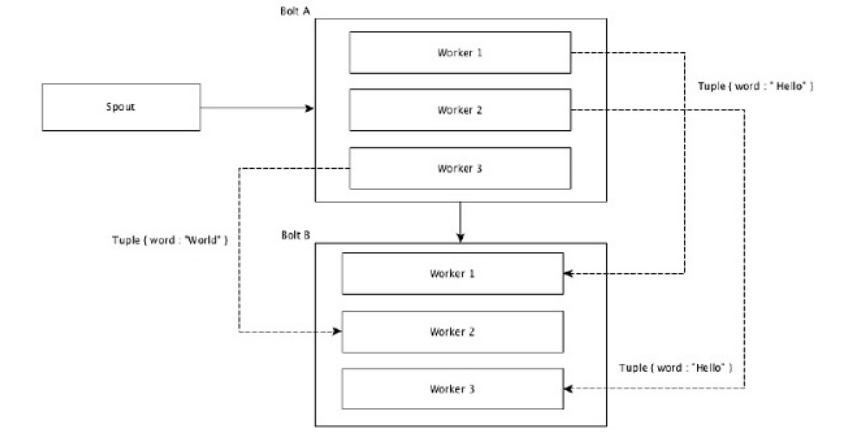
- Field Grouping
Các trường có cùng giá trị trong tuple sẽ được nhóm lại với nhau. Tuples cùng giá trị trường được gửi tới cùng worker thực thi trên bolts.
Ví dụ: nhóm cùng trường ‘word’ thì tuple mà cùng giá trị ‘hello’ sẽ được gửi tới cùng một worker.
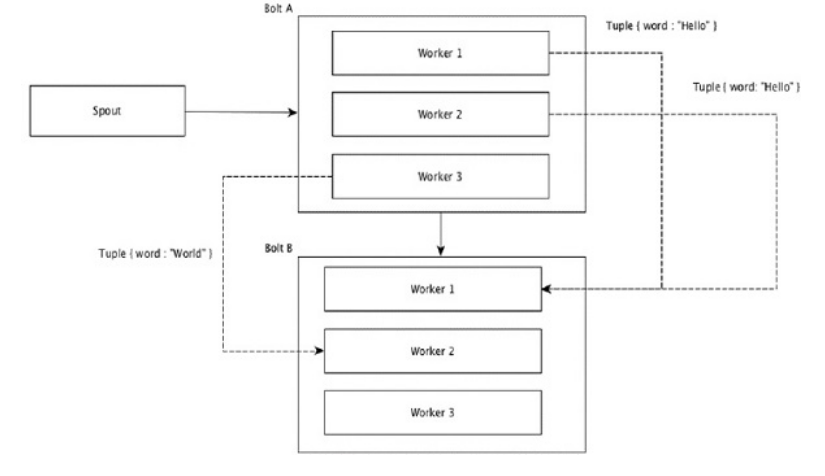
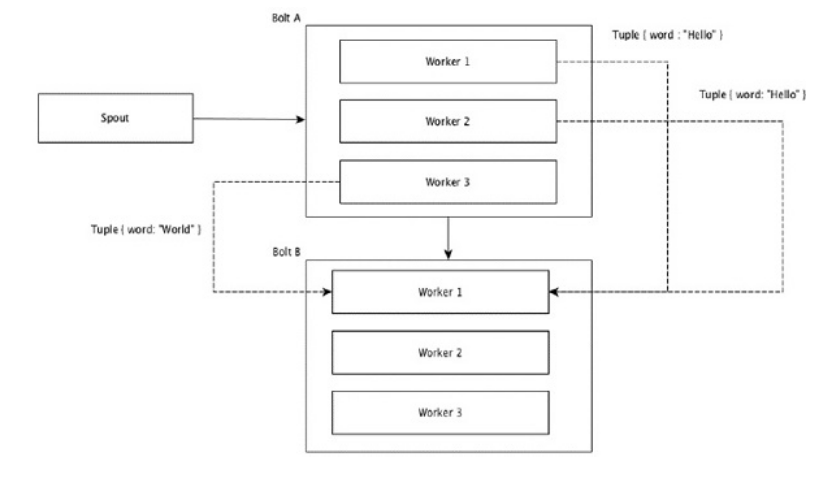
- Global Grouping
Tất cả các luồng có thể được nhóm lại và chuyển tiếp tới cùng một bolt. Nhóm này gửi các tuple được tạo bởi tất cả các nguồn tới một đích duy nhất (cụ thể, chọn worker có ID thấp nhất).
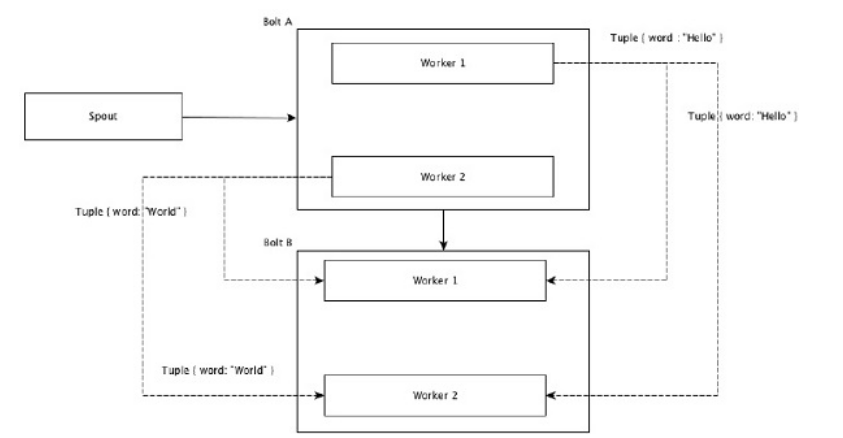
- All Grouping
Tất cả các nhóm gửi một bản sao của mỗi bộ tuple cho tất cả các worker của bolt nhận. Loại nhóm này được sử dụng để gửi tín hiệu đến bolt.
3. Kiến trúc Cluster
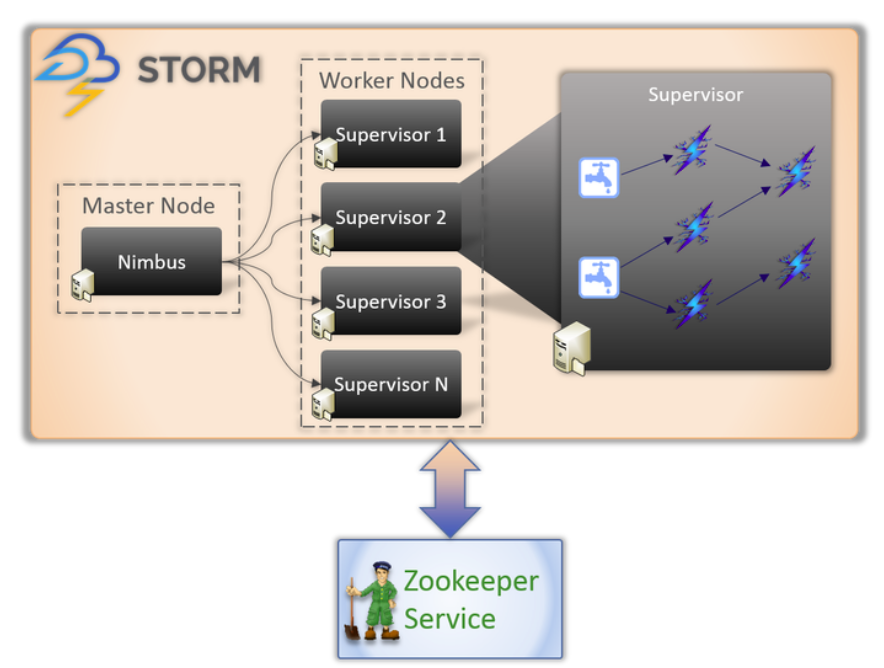
3.1. Các kiểu nodes trong storm cluster
-
Nimbus (Master node)
Nimbus là thành phần trung tâm của Apache Storm. Nimbus chịu trách nhiệm phân phối dữ liệu giữa tất cả các worker node, gán nhiệm vụ cho các node đó và theo dõi lỗi. Do Storm thiếu khả năng quản lý trạng thái, Nimbus phải dựa vào ZooKeeper để giám sát các thông điệp được gửi bởi các worker node trong khi xử lý các nhiệm vụ. Tất cả các worker node cập nhật trạng thái nhiệm vụ của họ trong ZooKeeper service cho Nimbus để xem và giám sát.
-
Supervisor (Worker node)
Supervisor chịu trách nhiệm nhận công việc được giao cho một máy từ Nimbus. Một supervisor có nhiều worker processes và nó điều chỉnh các worker processes để hoàn thành các nhiệm vụ được chỉ định bởi nimbus. Mỗi worker processes này thực hiện một tập hợp con của cấu trúc liên kết hoàn chỉnh.
3.2. Các thành phần khác
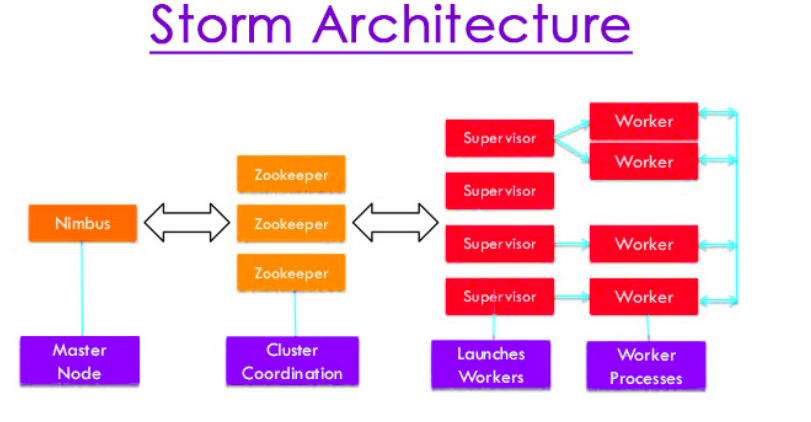
-
Worker process sẽ thực thi các task liên quan được xác định trong topology. Một worker process sẽ không tự thực thi tác vụ. Thay vào đó, nó tạo executors và yêu cầu chúng thực hiện một tác vụ cụ thể. Một worker process có nhiều executors.
-
Executor được tạo ra bởi Worker process, thực hiện 1 hoặc nhiều task nhưng chỉ cho một spout hoặc bolt cụ thể.
-
Apache ZooKeeper là một dịch vụ được sử dụng bởi một cluster để điều phối chúng và duy trì việc chia sẻ dữ liệu với các kỹ thuật đồng bộ hóa mạnh mẽ. Nimbus là không trạng thái, do đó, nó phụ thuộc vào ZooKeeper để theo dõi trạng thái nút làm việc. ZooKeeper giúp supervisor tương tác với nimbus. Nó có trách nhiệm duy trì trạng thái của nimbus và Supervisor.
Storm không hoàn toàn là không có trạng thái. Nó lưu trữ trạng thái của nó trong Apache ZooKeeper. Dựa vào Apache ZooKeeper, một nimbus bị hỏng có thể được khởi động lại và thực hiện để làm việc. Thông thường, các công cụ giám sát dịch vụ như monit sẽ giám sát Nimbus và khởi động lại nó nếu có bất kỳ lỗi nào.
4. Luồng thực hiện
Một cluster trong Storm thường có một nimbus và một hoặc nhiều supervisor. Một thành phần quan trọng khác là Apache ZooKeeper, sẽ được sử dụng để điều phối giữa nimbus và các supervisor.
- Ban đầu, nimbus chờ đợi "Storm topology" được gửi đến.
- Sau đó, nó sẽ xử lý topology và thu thập tất cả nhiệm vụ sẽ thực hiện và thứ tự mà tác vụ được thực hiện.
- Sau đó, Nimbus sẽ phân phối đều các nhiệm vụ cho các supervisor có sẵn.
- Tại một khoảng thời gian cụ thể, tất cả supervisor phải gửi heartbeat cho nimbus để thông báo là nó còn hoạt động. Nếu supervisor không hoạt động (không gửi heartbeat cho Nimbus) thì Nimbus sẽ phân công nhiệm vụ cho supervisor khác. Khi hoàn thành công việc, supervisor sẽ đợi nhiệm vụ mới đến.
- Nếu nimbus dừng hoạt động đột ngột thì các supervisor vẫn làm việc bình thường với các nhiệm vụ đã được giao mà không gặp phải vấn đề gì. Trong khi chờ đợi, Nimbus bị hỏng sẽ được khởi động lại tự động bởi các công cụ giám sát dịch vụ (monitoring tools).
- Các nimbus khởi động lại sẽ tiếp tục công việc tại thời điểm nó dừng lại. Tương tự, supervisor bị hỏng cũng có thể được khởi động lại tự động. Vì cả nimbus và supervisor có thể được tự động khởi động lại và tiếp tục làm việc như trước nên Storm được đảm bảo xử lý tất cả nhiệm vụ ít nhất một lần.
- Khi "Storm topology" được xử lý xong, Nimbus sẽ tiếp tục đợi các topology khác đến, các Supervisor tiếp tục đợi công việc được phân công từ Nimbus.
5. Kết luận
Lợi ích của Apache Storm
- Storm là mã nguồn mở, mạnh mẽ và thân thiện với người dùng. Nó có thể được sử dụng trong các công ty nhỏ cũng như các tập đoàn lớn.
- Có khả năng chịu lỗi ( fault tolerant), linh hoạt , tin cậy ( reliable) và có khả năng hỗ trợ nhiều ngôn ngữ.
- Cho phép xử lý luồng thời gian thực.
- Storm có thể theo kịp hiệu suất ngay cả khi tăng tải bằng cách thêm tài nguyên tuyến tính. Có khả năng mở rộng cao (scalable)
- Storm thực hiện làm mới dữ liệu và phản hồi phân phối từ đầu đến cuối trong vài giây hoặc vài phút tùy thuộc vào sự cố, có độ trễ thấp (low latency)
- Storm cung cấp đảm bảo xử lý dữ liệu ngay cả khi kết nối trong 1 cluster chết hoặc mất tin.
Tài liệu tham khảo
https://www.tutorialspoint.com/apache_storm/apache_storm_core_concepts.htm https://techtalk.vn/he-thong-xu-ly-du-lieu-luong-va-kien-truc.html https://www.freecodecamp.org/news/apache-storm-is-awesome-this-is-why-you-should-be-using-it-d7c37519a427/
All rights reserved
