Giới thiệu về Analysis và Analyzers trong Elaticsearch
Bài đăng này đã không được cập nhật trong 6 năm
Analysis là gì
Analysis là quá trình chuyển đổi văn bản thành tokens hoặc terms được thêm vào inverted index để tìm kiếm. Analysis được thực hiện bởi analyzer có thể là analyzer tích hợp hoặc analyzer tùy chỉnh được xác định cho mỗi chỉ mục.
Giải thích quá trình Analyzing
Khi chúng ta lập chỉ mục các tài liệu cho Elaticsearch, quy trình xử lý như sau:
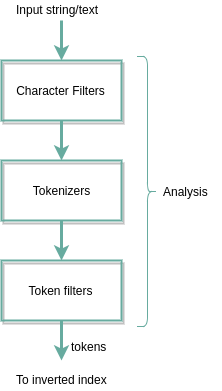
Bây giờ mình sẽ giải thích qua từng giai đoạn trước khi tạo inverted index
Character filters
Character filters có khả năng thực hiện các hành động bổ sung, xóa hoặc thay thế trên văn bản đầu vào được cung cấp. Để hiểu rõ hơn, nếu các chuỗi đầu vào chứa một từ sai chính tả lặp lại và ta cần thay thế nó bằng một từ đúng, ta có thể sử dụng các character filters. Một trong những ứng dụng phổ biến nhất của character filters là loại bỏ các thẻ html khỏi văn bản đầu vào.
Chúng ta hãy xem hoạt động của Character filters bằng cách sử dụng Analyze API của Elaticsearch. Ở đây chúng ta sẽ xóa các thẻ html khỏi một văn bản với character filters có tên là htmlstrip. Yêu cầu curl cho điều đó là:
curl -XPOST 'localhost:9200/_analyze?pretty' -H 'Content-Type: application/json' -d '{
"tokenizer": "standard",
"char_filter": [
"html_strip"
],
"text": "The <b> Auto-generation </b> is a success"
}'
Kết quả có các tokens như sau:
“The”,”Auto”,”generation”,”is”,”a”,”success”
Ở đây chúng ta có thể thấy không có thẻ html nào trong các tokens. Tương tự, hãy thử yêu cầu curl ở trên mà không cần đến char_filter “char_filter”:[“html_strip”] và xem sự khác biệt.
Tokenizer
Văn bản đầu vào sau khi chuyển đổi từ Character filter được chuyển đến tokeniser. Tokeniser sẽ chia văn bản đầu vào này thành các tokens riêng lẻ (hoặc terms) tại các ký tự cụ thể. Tokenizer mặc định trong elaticsearch là standard tokeniser, trong đó sử dụng kỹ thuật mã thông báo dựa trên ngữ pháp, có thể được mở rộng không chỉ sang tiếng Anh mà còn nhiều ngôn ngữ khác.
Ví dụ về standard tokeniser:
curl -XPOST ‘localhost:9200/_analyze?pretty’ -H ‘Content-Type: application/json’ -d '{
“tokenizer”: “standard”,
“text”: “The Auto-generation is a success”
}'
Trong phản hồi, bạn có thể thấy văn bản được chia thành các mã thông báo bên dưới:
“The”,”Auto”,”generation”,”is”,”a”,”success”
Ở đây các từ được phân chia bất cứ khi nào có khoảng trắng và dấu gạch nối
Lưu ý: Có nhiều loại mã thông báo khác nhau cho các mục đích khác nhau. Trong một số trường hợp sử dụng, chúng ta có thể không cần phải phân tách các ký tự đặc biệt, như trong trường hợp id email hoặc url, do đó, để phục vụ các nhu cầu mã thông báo như UAX URL Email Tokenizer có sẵn để chúng ta xử lý. Danh sách các mã thông báo được cung cấp bởi Elaticsearch có thể được tìm thấy ở đây
Token filter
Sau khi văn bản đầu vào được chia thành tokens/terms nó được chuyển giao cho giai đoạn cuối cùng của analysis là token filtering. Token filters có thể hoạt động trên các tokens được tạo từ tokenizers và sửa đổi, thêm hoặc xóa chúng. Hãy để chúng tôi thử token filter với ví dụ dưới. Bộ lọc mã thông báo mà chúng ta sẽ thử ở đây là lowercase token filter, sẽ viết thường tất cả các tokens vào đó. Yêu cầu curl sau đây sử dụng Analyze API để chứng minh:
curl -XPOST 'localhost:9200/_analyze?pretty' -H 'Content-Type: application/json' -d'{
"tokenizer": "standard",
"filter": [
"lowercase"
],
"text": "The Auto-generation is a success"
}'
Kết quả sẽ tạo ra các tokens như sau:
“the”,”auto”,”generation”,”is”,”a”,”success”
Lưu ý rằng mọi tokens bây giờ được viết thường. Đây là những gì lowercase token filter làm với tokens.
Để biết danh sách các token filters, hãy truy cập liên kết tại đây
Analyzers
Quá trình analyzing nội dung của các trường trong documents của Elaticsearch đã được giải thích trong phần trên. Như đã đề cập trong phần trên, có một số loại character filters, tokenizers và bộ token filters có sẵn và chúng ta phải chọn chúng một cách khôn ngoan theo trường hợp sử dụng mà chúng ta đang gặp phải. Sự kết hợp của ba thành phần này (character filters, tokenizers và token filters) được gọi là Analyzers. Có một số loại analysers có sẵn trong Elaticsearch để xử lý các trường hợp sử dụng phổ biến nhất. Ví dụ như Standard Analyzer là analyzer mặc định của Elasticsearch nó gồm một standard tokenizer và 2 token filters(standard token filter, lowercase và stop token filter). Tương tự như vậy, rất nhiều loại analyzers có thể tùy thuộc vào sự kết hợp của các char filters, tokenizers và token filters.
Cấu trúc chung của analyser được trình bày dưới đây:
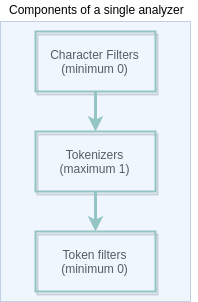
Chúng ta cũng có thể tạo các custom analyzers bằng cách chọn các filters cần thiết và tokenizer.
Analysis Phases
Bây giờ chúng ta đã có một bức tranh rõ ràng về analysis và analyzers là gì, chúng ta hãy chuyển sang hai giai đoạn analysis xảy ra trong Elaticsearch, index time analysis và search time analysis
Index time analysis
Chúng ta xem xét các documents sau đây để lập chỉ mục
curl -XPOST localhost:9200/testindex-0203/testtype/1 -d '{
"text": "My name is Arun"
}'
Vì chúng ta không áp dụng analyzers, Elaticsearch áp dụng analyzer mặc định Standard analyzer. Chúng ta xem các tokens cuối cùng của tài liệu trên khi áp dụng Standard Analyser với sự trợ giúp của Standard Analyser
curl -XPOST 'localhost:9200/_analyze?pretty' -H 'Content-Type: application/json' -d'{
"analyzer": "standard",
"text": "My name is Arun"
}'
Các tokens được tạo để lưu trữ trong inverted index là:
“my”,”name”,”is”,”arun”
inverted index sẽ trông giống như bảng dưới đây:
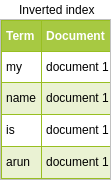
Toàn bộ quá trình này xảy ra trong thời gian chỉ mục và do đó có tên là index time analysis.
Search time analysis
Search time analysis như tên cho thấy sẽ xảy ra tại thời điểm tìm kiếm. Nhưng có một sự khác biệt, đó là phân tích này xảy ra trên truy vấn tùy thuộc vào truy vấn nào được sử dụng.
Term query — Case 1
Hãy xem xét các truy vấn sau:
curl -XPOST localhost:9200/testindex-0203/testtype/_search -d '{
“query”: {
“term”: {
“text”: “name”
}
}
}'
Nếu chúng ta chạy truy vấn này trên index testindex-0203, nó sẽ trả về tài liệu được lập chỉ mục là kết quả. Token “name” là có trong inverted index và được ánh xạ lại document 1. Vì vậy, khi chúng ta tìm term “name”, nó sẽ tìm kiếm inverted index và vì term được tìm thấy ở đó, tài liệu tương ứng đã được tìm nạp dưới dạng kết quả
Term query — Case 2
Bây giờ hãy xem xét một trường hợp khác với cùng một “term” query, như bên dưới:
curl -XPOST localhost:9200/testindex-0203/testtype/_search -d '{
“query”: {
“term”: {
“text”: “Name”
}
}
}'
Giống với term query case 1 chỉ khác ở chỗ search keyword là "Name" thay thế cho "name". Bây giờ một cái gì đó xen kẽ xảy ra, tìm kiếm này sẽ không cho chúng tôi bất kỳ tài liệu nào. Lý do cho hành vi kỳ lạ này là vì "Name" không tồn tại trong inverted index và do đó không có tài liệu nào để hiển thị
Vì vậy, với “term” query không có analysis nào được phép thực hiện trên từ khóa tìm kiếm.
Đây là trường hợp “term” query trong elasticsearch. Chúng ta hãy thử một query khác gọi là match query và kiểm tra kết quả đầu ra.
Match query
Ở đây, khi chúng ta sử dụng “term” query mối quan hệ của người dùng trong case 2, nó không mang lại phản hồi. Nhưng với match query, bất kỳ analysis nào được áp dụng cho trường được truy vấn (văn bản) tại thời điểm lập chỉ mục, analysis cũng sẽ được thực hiện trên từ khóa tìm kiếm (“Name”). Điều này làm cho keyword search trải qua "standard analysis" và từ khóa tìm kiếm "Name" đổi thành "name"(Do lowercase token filter trong standard analyzer). Keyword mới "name" tồn tại trong inverted index nên sẽ có kết quả trả về.
Vậy nên, phụ thuộc vào kiểu query các từ khóa tìm kiếm có được phân tích trong khoảng thời gian tìm kiếm hay không. Đây gọi là search time analysis.
Kết luận
Trên đây mình đã giới thiệu các thành phần rất cơ bản của Analyzers và các loại analysis xảy ra trong Elaticsearch. Để hiểu rõ hơn bạn có thể tham khảo tài liệu đính kèm bên dưới
Tài liệu tham khảo
All rights reserved
