Giới Thiệu SQL Server In-Memory OLTP
Bài đăng này đã không được cập nhật trong 4 năm
In-Memory Online Transaction Processing (OLTP), còn được gọi là Hekaton hay In-Memory Optimization, là phiên bản mới nhất của công nghệ xử lý dữ liệu trên bộ nhớ của Microsoft nhằm tối ưu hóa tốc độ truy xuất, được tích hợp trong SQL Server’s Database Engine và được sử dụng hoàn toàn giống như các thành phần của Database truyền thống.
In-Memory OLTP được xuất bản trong SQL Server 2014 nhưng còn rất nhiều thiếu sót như không thể dùng được lệnh ALTER TABLE và được hoàn thiện trong SQL Server 2016. Kiến trúc của nó bao gồm:
- Các bảng tối ưu hóa bằng bộ nhớ Memory-Optimized Tables
- Các thủ tục biên dịch tự nhiên Natively-Compiled Stored Procedures
- Hash index và range index
1. Memory-Optimized Tables là các bảng được tạo ra bằng lệnh CREATE TABLE, hoàn toàn ổn định và bền vững như các table trên ổ cứng truyền thống.
 Dữ liệu của Memory-Optimized tables được lưu trữ bộ nhớ RAM. Các record trong bảng được đọc và ghi vào bộ nhớ, một bản copy dữ liệu của bảng sẽ được bảo quản trong ổ cứng thật để an toàn dữ liệu. Dữ liệu trong bảng memory chỉ được đọc lại từ bảng trên ổ cứng trong quá trình recovery, ví dụ như khi restart server.
Dữ liệu của Memory-Optimized tables được lưu trữ bộ nhớ RAM. Các record trong bảng được đọc và ghi vào bộ nhớ, một bản copy dữ liệu của bảng sẽ được bảo quản trong ổ cứng thật để an toàn dữ liệu. Dữ liệu trong bảng memory chỉ được đọc lại từ bảng trên ổ cứng trong quá trình recovery, ví dụ như khi restart server.
Memory-Optimized Tables sao lưu dữ liệu vào bản trên ổ cứng bằng cơ chế transaction delayed. Các thay đổi dữ liệu sẽ được lưu vào ổ cứng ngay khi giao dịch được xử lý hoàn tất và đã trả kết quả lại cho người dùng. Cho nên đổi lại cho việc tăng đáng kể performance, các transaction đã commit mà không kịp lưu vào đĩa sẽ bị mất nếu server bị down hay treo ngay lúc đó.
Memory-Optimized Tables có 2 dạng:
- Durable (DURABILITY=SCHEMA_AND_DATA): ở dạng mặc định, vừa lưu data vào bảng trên bộ nhớ, vừa lưu data vào bảng trên ổ cứng. Ví dụ: Bảng "Product" được tạo như sau:
CREATE TABLE [dbo].[Product]
(
ID INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1000),
Code VARCHAR(10) NOT NULL,
Description VARCHAR(200) NOT NULL,
Price FLOAT NOT NULL
) WITH (MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_AND_DATA);
GO
- Non-durable (DURABILITY=SCHEMA_ONLY): chỉ lưu dữ liệu trên bộ nhớ mà không lưu lại vào ổ cứng. Các table dạng này thường chỉ dùng lưu dữ liệu tạm thời như các bảng làm trung gian. Những bảng này không cần sử dụng ổ cứng, và dữ liệu không được phục hồi nếu server down. Ví dụ: Giống Durable nhưng thuộc tính DURABILITY sẽ là SCHEMA_ONLY
CREATE TABLE [dbo].[Product]
(
ID INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1000),
Code VARCHAR(10) COLLATE Latinl_General_100_BIN2 NOT NULL,
Description VARCHAR(200) NOT NULL,
Price FLOAT NOT NULL
) WITH (MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_ONLY);
GO
Memory-Optimized Tables được sử dụng giống như bảng truyền thống cho cùng các hoạt động develop, triển khai, bảo trì. Một database có thể chứa cả bảng ảo và bảng thật chung với nhau.
Dữ liệu trong các bảng MO được truy xuất theo 2 cách:
- Qua các lệnh Transact-SQL truyền thống.
- Bằng các Natively-Compiled Stored Procedures
Để tạo một database sử dụng In-Memory OLTP, cần thực hiện các bước:
- Tạo một memory-optimized data filegroup và gán đường dẫn vào file group.
- Tạo các bảng memory-optimized tables và các indexes.
CREATE DATABASE imoltp;
GO
ALTER DATABASE imoltp ADD FILEGROUP [imoltp_mod] CONTAINS MEMORY_OPTIMIZED_DATA;
ALTER DATABASE imoltp ADD FILE (name = [imoltp_dir], filename='c:\data\imoltp_dir') TO FILEGROUP imoltp_mod;
GO
USE imoltp
GO
CREATE TABLE [dbo].[Product]
(
ID INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1000),
Code VARCHAR(10) COLLATE Latinl_General_100_BIN2 NOT NULL,
Description VARCHAR(200) NOT NULL,
Price FLOAT NOT NULL
) WITH (MEMORY_OPTIMIZED=ON,
DURABILITY=SCHEMA_AND_DATA)
2. Các thủ tục biên dịch tự nhiên Natively-Compiled Stored Procedures Natively-Compiled Stored Procedures chỉ có thể được sử dụng để xử lý memory-optimized tables, cũng như các cấu trúc T-SQL khác được hỗ trợ như các truy vấn phụ, các hàm do người sử dụng xác định vô hướng, các hàm toán học tích hợp, vv. Code được thực thi mà không cần thêm bất kỳ trình biên dịch hay thông dịch gì nữa.
Dựa trên các ví dụ trước, ví dụ sau đây sẽ định nghĩa về natively-compiled stored procedures update cột "Pirce" memory-optimized table “Product”.
CREATE PROCEDURE [dbo].[spProductUpdate]
WITH NATIVE_CCMPILATION,
SCHEMABINDING,
EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH ( TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'us_english' )
UPDATE dbo.Product
SET Price = Price - ( Price * 0.10 );
END;
Ngoài ra có một số điểm cần lưu ý trong định nghĩa ở trên của natively-compiled stored procedures là:
- Mệnh đề WITH NATIVE_COMPILATION được sử dụng
- Mệnh đề SCHMABINDING là bắt buộc bởi vì nó giới hạn các thủ tục lưu trữ vào schema của các đối tượng mà nó tham chiếu
- Mệnh đề BEGIN_ATOMIC là bắt buộc bởi vì thủ tục lưu trữ phải bao gồm chính xác một khối cùng với transaction Isolation level.
3. Hash index In-Memory OLTP Tables
Hash index là một giải pháp lý tưởng để tăng tốc truy vấn, sử dụng tốt nhất cho các truy vấn có mệnh đề WHERE chỉ tới một giá trị chính xác của cột được đánh index. Và nó có cấu trúc như sau:
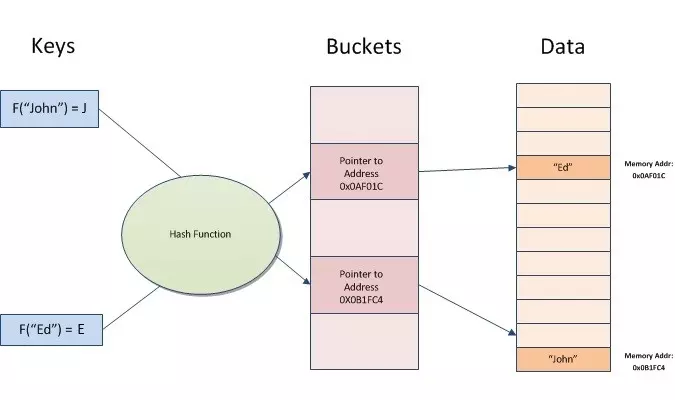 Hash indexes có thể được tạo trong lệnh CREATE TABLE hoặc thêm vào sau bằng lệnh ALTER TABLE.
Hash indexes có thể được tạo trong lệnh CREATE TABLE hoặc thêm vào sau bằng lệnh ALTER TABLE.
CREATE TABLE [dbo].[Product]
(
ID INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1000),
Code VARCHAR(10) NOT NULL,
Description VARCHAR(200) NOT NULL,
Price FLOAT NOT NULL,
INDEX IX_Hash_Code HASH (Code) WITH (BUCKET_COUNT = 100000)
) WITH (MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_AND_DATA);
GO
Khai báo Bucket_Count: mỗi bucket có dung lượng 8 byte chứa một con trỏ tới đúng khóa được index của record. Mỗi record là một phần của chuỗi index, được link tới một record cha và một record con. Nếu số lượng record lớn và số lượng bucket nhỏ thì chuỗi index sẽ dài làm cho tiến trình quét lấy ra đúng record trong chuỗi sẽ mất nhiều thời gian ảnh hưởng tới performance. Tiến trình scan này bao gồm cả tìm ra đúng dòng để update EndTs khi thực hiện lệnh UPDATE hay DELETE. Nếu số lượng bucket lớn và số lượng data ít thì gây dư thừa và lãng phí bộ nhớ. Không có con số lý tưởng hay chính xác để set cho bucket count. Microsoft khuyên nên chọn một số nằm giữa số lượng các record mà có cột index là duy nhất. Ví dụ nếu có table [dbo].[Product] có 100.000 distinct ID thì khi index trên cột này bucket count nên set trong khoảng 100.000 đến 200.000.
Lưu ý: Hash indexes không hiệu quả cao khi được đánh trên cột có quá nhiều trường hợp trùng (duplicates). Các giá trị trùng tạo ra cùng giá trị hash (băm) giống nhau sẽ tạo thành một chuỗi liên kết index dài. Nói chung, nếu tỉ lệ tổng số record trên tổng số record duy nhất lớn hơn 10 thì nên sử dụng range index để thay thế. Ví dụ nếu có 100.000 "Product" trong một bảng mà có tổng số "Code" duy nhất là 300 thì không nên dùng hash index trên cột "Code" mà phải dùng range index, vì tỉ lệ 100.000 / 300 ~ 333.
Nguồn tham khảo: https://www.simple-talk.com/sql/learn-sql-server/introducing-sql-server-in-memory-oltp/ http://lethaihoangquan.blogspot.com/2017/05/gioi-thieu-sql-server-in-memory-oltp.html
All rights reserved
