Giới thiệu sơ lược về Elastic Search. Từ cơ bản đến nâng cao
This post hasn't been updated for 6 years
I. Mở đầu
Searching chắc hẳn là một trong những chức năng rất quan trọng hiện nay, đặc biệt là Big Data ngày càng trở nên phổ biến. Do đó, để đáp ứng ngày càng tăng thì đã xuất hiện rất nhiều phương thức search khác nhau, và nổi lên cả là Elastic Search và Kibana. Mình đã dành rất nhiều thời gian để nghiên cứu về nó, kèm theo đó rất nhiều điều rất hay về nền tảng này, trong bài viết này sẽ chia sẻ một cách đơn giản và mở đầu cho 1 chuỗi các bài về về Elastic Search từ cơ bản đến nâng cao.
II.Elastic Search là gì?
Elasticsearch là một open source serch engine có khả năng highly scalable.
Nó cho phép chúng ta lưu trữ, phân tích một lượng lớn thông tin realtime.
Elasticsearch làm việc với JSON documents files. Sử dụng internal structure đặc trưng, nó có thể parse data của bạn một cách realtime và có thể search mọi thông tin mà bạn muốn.
Trong những bài viết tới mình sẽ phân tích sâu hơn về cách thức làm việc và những điều mạnh mẽ mà Elasticsearch có thể làm được, và cực kì hữu dụng khi làm với dữ liệu lớn. Bài viết này gần giống với 1 bài 101 Introduction Elasticsearch for dummy, dành cho những người chưa bao giờ làm việc với nó và chưa mường tượng được luồng xử lý của ElasticSearch
ElasticSearch hiện có thể sử dụng ở đây
III. Định nghĩ và một số thuật ngữ
Một số thông tin, về kĩ thuật, khá là hữu dụng và sử dụng thường xuyên về ElasticSearch mà mình đang sử dụng.
Reatime distributed và analytics engine. (Mình để nguyên tiếng anh, để là key-word cho mọi người dễ search, hơn là dịch thành tiếng Việt)
Nó là open source và được build trên nền Java
Structure được based theo documents thay vì tables và schema Lợi ích lớn nhất mà mình có thể cảm nhận thấy là tốc độ và khả năng scalability (khả năng mở rộng). Nó có thể đc implement bằng cách để đảm bảo cho việc mình có thể query nhanh nhất có thể. Về khả năng mở rộng, thì chúng ta có thể run trên laptop với hang trăm server và hang petabytes dữ liệu. Bên cạnh tốc độ, và khả năng mở rộng, thì khả năng phục hồi (high resiliency) nhữngđiều liên quan đế sự linh hoạt khi liên quna đến giữ liệu bị lỗi. Do đó, như đã nói ở trên thì Elasticsearch rất là hữu hiệu khi làm việc với dữ liệu lớn, với hàng trăm nghỉ bản ghi một cách realtime. Đó chính là điều mà Elasticsearch làm được một cách rất tuyệt vời.
Về analysis, Elasticsearch sẽ cung cấp cho người dùng log đầy đủ để có thể giúp chúng ta có thể tìm và phân tích ra được trend dựa theo partern trong data Ví dụ:
- Show data với value cụ thể. Ví dụ: show tất cả users 23 tuổi trong database

- Search data theo vị trí địa lý

- Tổng hợp thông tin theo ngày
IV.Clients
Khá nhiều clients lớn đang sử dụng ElasticSearch và các nhà cung cấp các dịch vụ cloud cũng đã tích hợp rất nhiều dịch vụ hỗ trợ ElasticSearch. Một số dịch vụ lớn đang sử dụng như Mozilla, GitHub, Stack Exchange, Netflix
V. Cách cài đặt
Về cơ bản cách cài đặt khá đơn giản, bạn có thể follow theo guide của trang chủ. Nhưng như mình dã đề cập ở trên thì server của ElasticSearch sử dụng Java do đó cần phải cài Java trước khi install > version 8 Interface
VI. Interface
ElasticSearch đơn thuần chỉ là một sever (backend) do đó chúng ta cần interface để có thể visualize thông tin. Và ElasticSearch đã cung cấp Kibana để hỗ trợ việc đó. Cách cài đặt bạn cũng có thể xem trên trang chủ, và khá đơn giản Ttương tác với Elastics thì có một số ngôn ngữ được hỗ trợ như sau
- Java
- C#
- Python
- JavaScript
- PHP
- Perl
- Ruby
VII. Basic Concepts
Ok, để tiếp tục, giả sử đến bây giờ bạn đã hoàn thành setup Kibana vầ ElasticSearch. Bây giờ, để bắt đâu, chúng ta cần biết về concept cơ bản của ElasticSearch
Elasticsearch được tạo ra từ ?
1. Cluster
Cluster là một tập hợp gồm một hoặc nhiều nodes, đồng thời, chúng sẽ lưu trữ thông tin. Nó cung cấp khả năng lập chỉ mục (index) và tìm kiếm theo node và được xác định bằng một cái unique name. (default đường dẫn là ‘/ elasticsearch’/)
2. Node
Một node là một single server cái bao gồm cluster, stores data, và tham gia vào khả năng tìm kiếm và cluster’s indexing
3. Index
Nếu để nói chính xác index trong ElasticSearch cụ thể là gì thì khá là dài dòng và khó hiểu, mình sẽ đề cập trong bài viết tới, nhưng để có thể hiểu đơn giản nhất thì index của ElastisSearch gần giống với index của Database, cái mà sẽ giúp chúng ta tăng tốc độ query, search, update delete v.v...
4. Documents
Đó là một đơn vị thông tin cơ bản (theo mình đọc trong documents là basic unit of information), có thể được index. Nó được biểu thị bằng JSON
5. Các thành phần khác
Ngoài ra, trong ElasticSearch còn có 2 thành phần rất quan trọng khác là Shards và Replicas. Nó có phần hơi trìu tượng và dễ gây rối, nên mình sẽ nhắc lại trong bài viết tiếp.
VII. Excuting
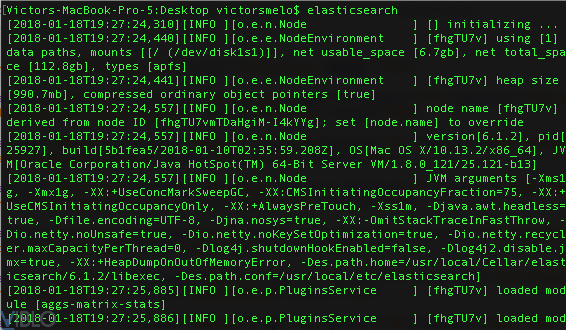
Ok, bây giờ chúng ta sẽ bắt đầu bắt tay vào khởi tạo và chạy thử Elasticsearch. Sau khi được cài đặt và excute chúng thông qua terminal
$ ./elasticsearch
Nếu bạn sử dụng Homebrew thì chỉ cần gõ elasticsearch ở trên terminal thì hệ thống sẽ chạy ngay lập tức
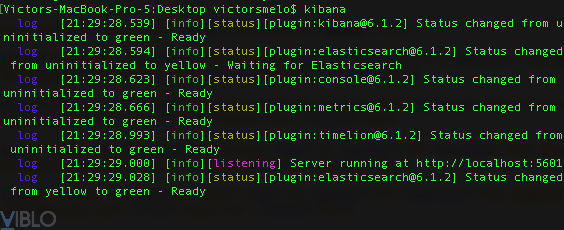
Sau khi chạy xong ElasticSearch thì tần chạy cả Interface Kibana, tương tự như vậy thì mình sẽ chỉ cần chạy kibana nếu đang sử dụng HomeBrew
Nếu mọi thứ đúng hết thì ta có thể vào đc trang http://localhost:9200
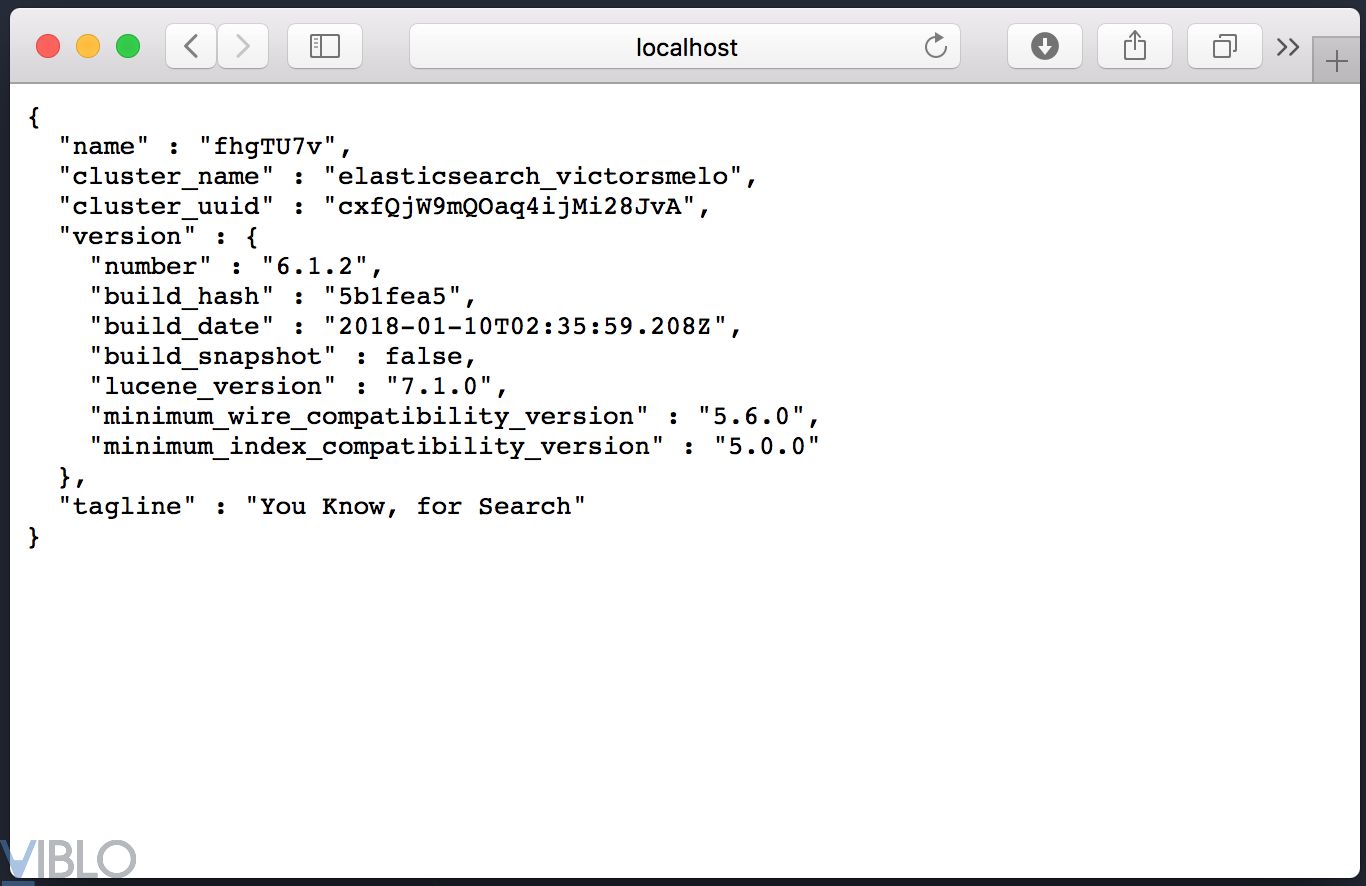
Để vào được Kibana ta vào đường dẫn sau http://localhost:5601
VII. Commands
Ở trong Kibân, chúng ta có thể chọn Dev Tools, ở trên menu. Chúng ta có thể gọi các request và lấy ra thông tin tương ứng mà mình mong muốn.
1. Put
PUT command cho phép chúng ta thêm và document data mới vào ElasticSearch.
PUT /my_playlist/song/6
{
"title" : "1000 years",
"artist" : "Christina Perri",
"album" : "Breaking Dawn",
"year" : 2011
}
Chúng ta bấm vào nút Play để excute lệnh
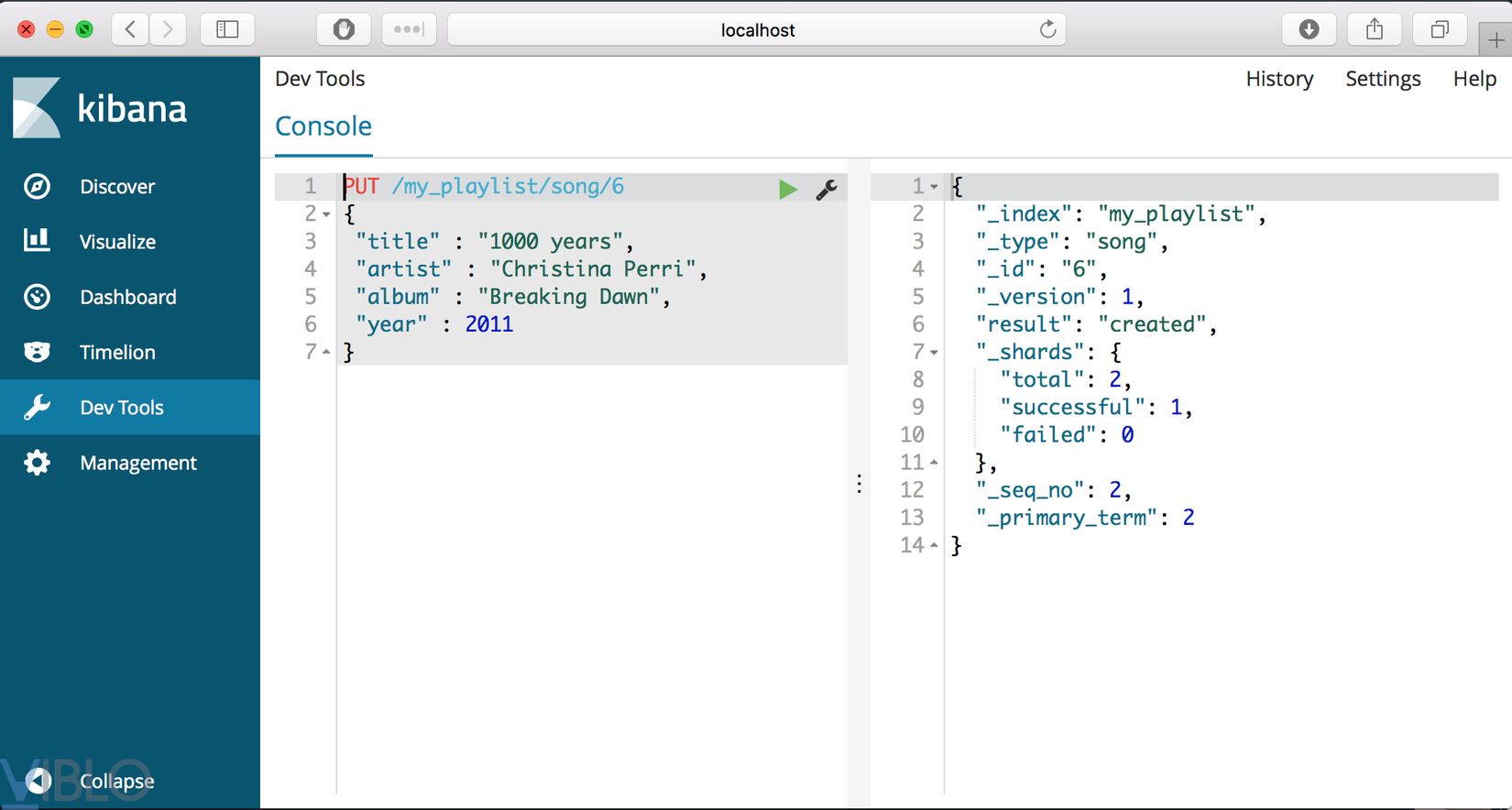
Nghĩa là bạn đã tạo một document data vào trong Elasticsearch. Trong ví dụ này chúng ta có /my_playlist/song/6:
- my_playlist: là tên của index mà bạn sẽ insert data
- song: tên của documents được tạo
- 6: id cuiar element instance. Trong case này là song id
Nếu index my_playlist không tồn tạo, chúng sẽ tự tạo và tương tự như vậy với song và 6
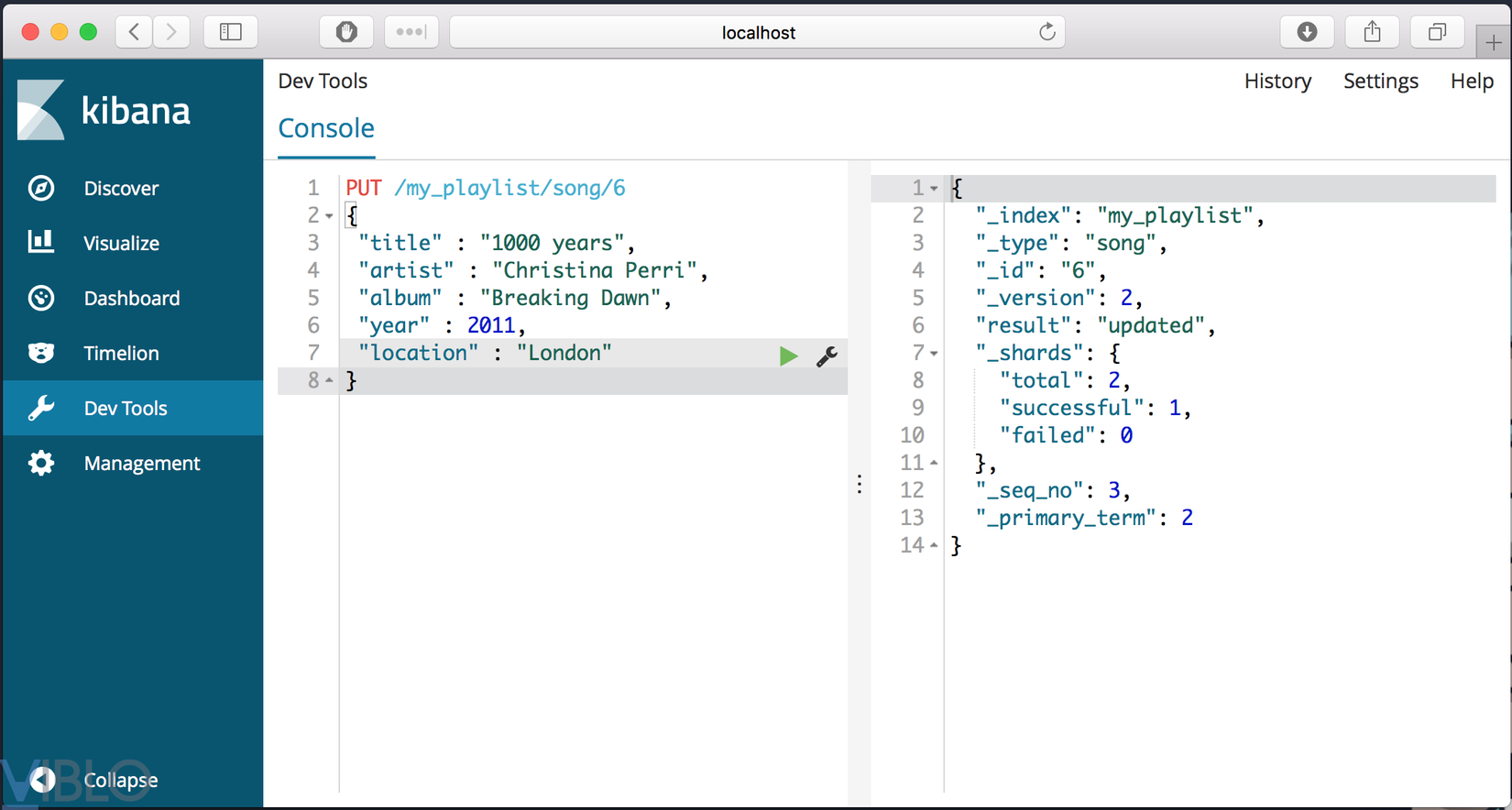
Để UPDATE value, chúng ta sử dụng PUT command với cùng document. Ví dụ nếu bạn muốn thêm parameter location thì chung ta làm như sau
PUT /my_playlist/song/6
{
"title" : "1000 years",
"artist" : "Christina Perri",
"album" : "Breaking Dawn",
"year" : 2011,
"location" : "London"
}
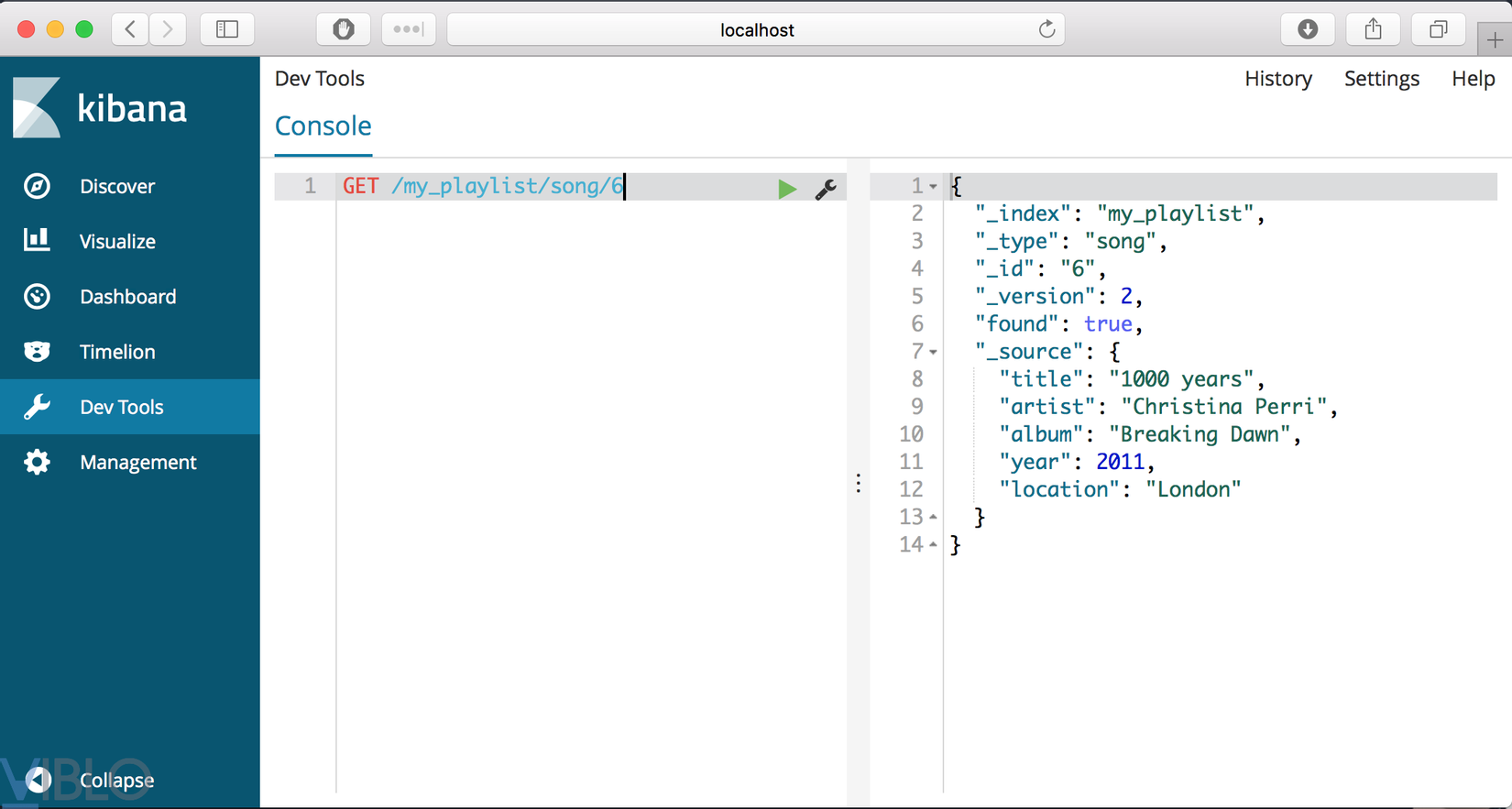
2. GET
Cho phép người dùng có thể lấy thông tin về data
GET /my_playlist/song/6
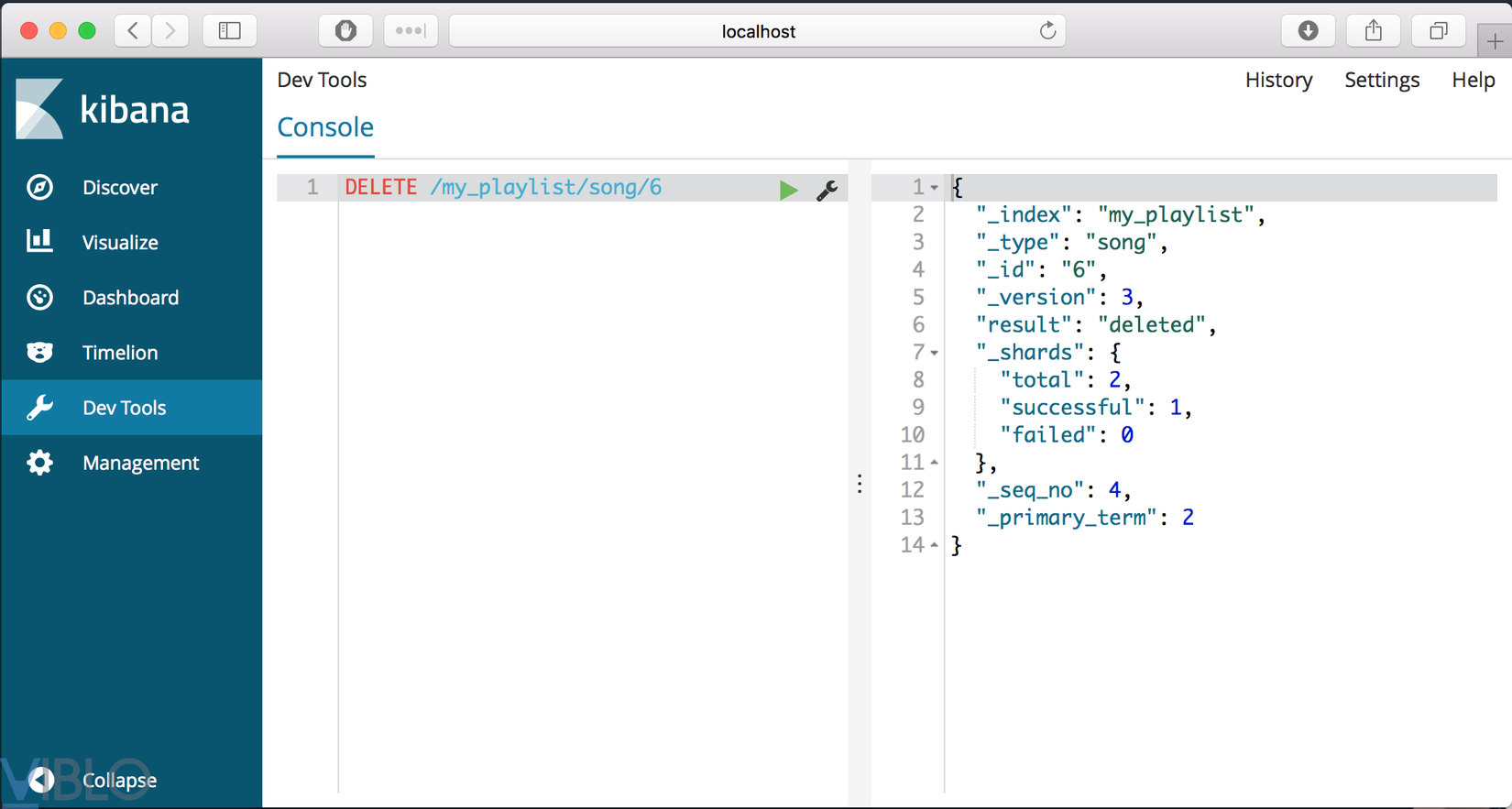
3. Delete
Cho phép người dùng delete docuemtn
DELETE /my_playlist/song/6
4. Search Data
Với Simple Seasrch data thì có 2 example cơ bản là sử dụng URI Search và sử dụng Query DSL. Với URI search thì chúng ta sẽ thêm thẳng params vào trong query GET, ví dụ
Return all accounts from state UT.
GET /bank/_search?q=state:UTReturn all accounts from UT or CA.
GET /bank/_search?q=state:UT OR CAReturn all accounts from state TN and from female clients.
GET /bank/_search?q=state:TN AND gender:FReturn all accounts from people older than 20 years.
GET /bank/_search?q=age:>20Return all accounts from people between 20 and 25 years old.
GET /bank/_search?q=age:(>=20 AND <=25)
Ngoài ra, chúng ta có thể sử dụng search nâng cao hơn và query được nhiều điều kiện phức tạp hơn, và tốc độ tốt hơn so với URI đó là DSL. Để có thể giới thiệu hết được về sức mạnh của DSL thì mình xin phép giới thiệu trong một bài viết sắp tới, chuyên sâu hơn kèm theo ví dụ thực tế.
VII. Tổng kết
Qua đây chúng ta có thể nắm được một phần về ElasticSearch, và những điều cơ bản về nhất về nó. Trong bài viết tiếp theo mình xin phép giới thiệu thêm DSL Query, Performance, và cách thức xử lý bên trong server Elastic.
All Rights Reserved
