Giải pháp Big Data - Hadoop
Bài đăng này đã không được cập nhật trong 4 năm
1. Big data là gì?
Với sự phát triển không ngừng của mang xã hội, sự ra đời của các thiết bị mới tiên tiến, mọi hoạt động thường ngày đang dần được internet hóa. Dẫn đến lượng thông tin ngày càng đa dạng đã đặt ra thách thức cho các nền công nghiệp khác nhau phải tìm một phương pháp khác để xử lý dữ liệu. Big Data có thể hiểu là “Dữ liệu lớn” – sở dĩ có tên gọi là Big data không đơn giản đó nói về khối lượng dữ liệu, còn có 2 yếu tố khác là tốc độ dữ liệu và tính đa dạng của dữ liệu.

Những nguồn thông tin chính tạo ra Big data:
- Dữ liệu từ các kênh truyền thông xã hội: Facebook, Instagram, Twiter..
- Dữ liệu giao dịch chứng khoán
- Dữ liệu điện lực
- Dữ liệu giao thông
- Các dữ liệu tìm kiếm
Giải pháp nào cho Big data?
- Big Data lớn về số lượng, dữ liệu phức tạp có thể có cấu trúc hoặc không có cấu trúc (noSQL). Những yếu tố này làm cho Big Data khó bắt giữ lại, khai phá và quản lý nếu dùng các phương thức truyền thống.
Ví dụ bạn có một con server, với lượng data khổng lồ, bạn chỉ có thể nghĩ đến phương án tăng RAM, tăng CPU. Nhưng số lượng đó cũng có giới hạn. Vậy thì phải làm sao?
Hadoop ra đời để giải quyết vấn đề đó

2. Hadoop là gì?
Năm 2005, Hadoop được tạo ra bởi Doug Cutting và Mike Cafarella khi làm việc tại Yahoo. Doug Cutting đặt tên Hadoop theo con voi đồ chơi của con trai mình
- Là Framework cho phép phát triển các ứng dụng phân tán.
- Hadoop hiện thực mô hình MapReduce, mô hình mà ứng dụng sẽ được chia nhỏ ra thành nhiều phân đoạn khác nhau được chạy song song trên nhiều node khác nhau
- Viết bằng Java tuy nhiên hỗ trợ được các ngôn ngữ khác như C++, Python, Perl bằng cơ chế streaming.
- Là một ứng dụng Linux-based (chỉ chạy trên môi trường Linux).
3. Vấn đề mà Hadoop giải quyết
- Làm việc với khối lượng dữ liệu khổng lồ (tính bằng Petabyte).
- Xử lý trong môi trường phân tán, dữ liệu lưu trữ ở nhiều phần cứng khác nhau, yêu cầu xử lý đồng bộ
- Các lỗi xuất hiện thường xuyên.
- Băng thông giữa các phần cứng vật lý chứa dữ liệu phân tán có giới hạn.
4. Hướng giải quyết của Hadoop
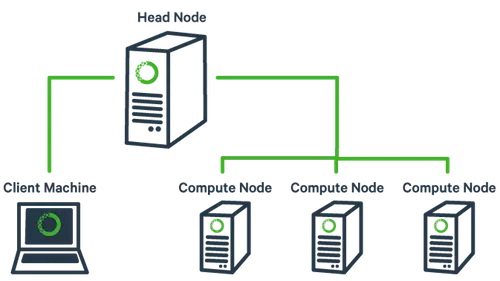
- Quản lý file phân tán: Hadoop Distributed File System (HDFS) sẽ chia nhỏ dữ liệu ra thành nhiều phần. Dữ liệu được quản lý một cách có hệ thống.

- MapReduce là mô hình tổ chức của Hadoop, MapReduce sẽ chia nhỏ task ra thành nhiều phần và xử lý song song trên các Node CPU khác nhau, máy chủ là Master Node
5. Các điểm thuận lợi khi dùng Hadoop
- Robus and Scalable – Có thể thêm node mới và thay đổi chúng khi cần.
- Affordable and Cost Effective – Không cần phần cứng đặc biệt để chạy Hadoop.
- Adaptive and Flexible – Hadoop được xây dựng với tiêu chí xử lý dữ liệu có cấu trúc và không cấu trúc.
- Highly Available and Fault Tolerant – Khi 1 node lỗi, nền tảng Hadoop tự động chuyển sang node khác.
- Một điểm cộng khác cho Hadoop nó là mã nguồn mở, có thể tương thích với tất cả platforms
Tóm lại, Big Data đã và đang được nghiên cứu và ứng dụng rộng rãi trong nhiều lĩnh vực, từ các ông lớn trong lĩnh vực công nghệ như Google, Facebook, Twitter... cũng như các công ty trong nước và ngoài nước. Big Data là thách thức đặt ra cho các tổ chức, doanh nghiệp trong thời đại số hiện nay. Một khi làm chủ được dữ liệu lớn thì họ sẽ có cơ hội thành công lớn hơn trong bối cảnh cạnh tranh ngày nay, thế giới thì sẽ được hưởng lợi hơn từ việc trích xuất thông tin một cách chính xác hơn, hữu ích hơn với chi phí thấp hơn. Trong tương lai, chúng ta sẽ còn tiếp tục chứng kiến sự tăng trưởng của Big Data.
Tham khảo: https://www.tutorialspoint.com/hadoop/
All rights reserved
