Giải mã kiến trúc Kafka qua các thuật ngữ cốt lõi mà developer cần nắm
Apache Kafka không chỉ là một hệ thống truyền message, mà là nền tảng event streaming được thiết kế để xử lý dữ liệu liên tục với quy mô lớn. Khi doanh nghiệp bắt đầu xây dựng pipeline thời gian thực cho log, tracking, transaction hay đồng bộ dữ liệu giữa nhiều hệ thống, Kafka thường xuất hiện như một thành phần trung tâm.
Tuy nhiên, để làm việc hiệu quả với Kafka, việc hiểu định nghĩa bề mặt là chưa đủ. Điều quan trọng hơn là phải nhìn được vai trò kỹ thuật của từng thành phần trong toàn bộ luồng dữ liệu: dữ liệu được ghi vào đâu, ai chịu trách nhiệm lưu trữ, consumer đọc theo cơ chế nào, tại sao phải có partition, offset dùng để làm gì và cluster vận hành ra sao khi mở rộng quy mô.
Kafka thực chất đang giải quyết bài toán gì?
Trong các hệ thống truyền thống, dữ liệu thường được ghi trực tiếp vào database hoặc đi qua các API đồng bộ giữa nhiều dịch vụ. Cách làm này vẫn hoạt động ở quy mô nhỏ, nhưng khi số lượng sự kiện tăng nhanh, nhiều vấn đề bắt đầu xuất hiện: nghẽn kết nối, tăng độ trễ, khó scale, khó replay dữ liệu, và khó tách biệt producer với consumer.
Kafka được sinh ra để xử lý đúng bài toán đó. Thay vì để các hệ thống giao tiếp chặt với nhau, Kafka đóng vai trò như một lớp trung gian cho luồng sự kiện, nơi dữ liệu được ghi nhận theo thứ tự, lưu trữ bền vững trên đĩa và cho phép nhiều consumer khai thác song song theo thời gian thực. Đây là lý do Kafka trở thành hạ tầng quan trọng trong các kiến trúc microservices, data platform, log aggregation, fraud detection, recommendation engine và analytics pipeline.
Nhìn Kafka theo góc độ kiến trúc hệ thống
Nếu xem Kafka như một hệ thống phân tán, ta có thể chia nó thành 3 lớp chính.
- Lớp đầu tiên là lớp ghi dữ liệu, nơi producer gửi event vào hệ thống.
- Lớp thứ hai là lớp lưu trữ và phân phối, do broker, topic và partition đảm nhiệm.
- Lớp thứ ba là lớp tiêu thụ dữ liệu, nơi consumer hoặc consumer group đọc dữ liệu để xử lý nghiệp vụ.
Cách chia này giúp việc học Kafka trở nên dễ hiểu hơn rất nhiều, bởi mỗi thuật ngữ không còn là khái niệm rời rạc mà gắn trực tiếp với một vai trò cụ thể trong pipeline.
Broker
Broker là máy chủ Kafka chịu trách nhiệm tiếp nhận, lưu trữ và phục vụ dữ liệu. Một cụm Kafka có thể có một broker hoặc nhiều broker, nhưng trong thực tế production, Kafka gần như luôn được triển khai dưới dạng cluster nhiều broker để đảm bảo khả năng mở rộng và tính sẵn sàng cao.
Mỗi broker quản lý một phần dữ liệu của hệ thống thông qua các partition nằm trên nó. Khi producer gửi dữ liệu vào topic, Kafka sẽ quyết định partition nào nhận event đó; còn khi consumer đọc dữ liệu, broker sẽ phản hồi dữ liệu từ partition tương ứng.
Về bản chất, broker không chỉ là “máy chủ trung gian” giữa bên gửi và bên nhận. Nó còn là thành phần đảm bảo lưu trữ bền vững, đồng bộ replica, quản lý network I/O và phục vụ yêu cầu đọc/ghi với thông lượng lớn. Trong kiến trúc Kafka, hiệu năng của broker ảnh hưởng trực tiếp đến độ ổn định của toàn bộ hệ thống.
Event và Message
 Trong nhiều tài liệu cũ, người ta thường dùng từ “message”. Nhưng trong các hệ thống hiện đại, “event” là cách gọi chính xác hơn vì nó thể hiện bản chất của dữ liệu: một sự kiện đã xảy ra trong hệ thống.
Trong nhiều tài liệu cũ, người ta thường dùng từ “message”. Nhưng trong các hệ thống hiện đại, “event” là cách gọi chính xác hơn vì nó thể hiện bản chất của dữ liệu: một sự kiện đã xảy ra trong hệ thống.
Ví dụ, khi người dùng tạo đơn hàng, đăng nhập, click nút, thanh toán thành công hoặc hủy giao dịch, mỗi hành động đó có thể được biểu diễn thành một event. Kafka không quan tâm nhiều đến ý nghĩa nghiệp vụ bên trong event; nó tập trung vào việc nhận, ghi, lưu và phân phối event đó một cách ổn định và có thứ tự trong phạm vi partition.
Dữ liệu trong Kafka thường được lưu dưới dạng key-value hoặc chuỗi byte. Điều này khiến Kafka trở nên linh hoạt: cùng một nền tảng có thể phục vụ log system, monitoring stream, CDC pipeline hoặc các bài toán analytics mà không bị ràng buộc bởi một mô hình dữ liệu cố định.
Producer
Producer là ứng dụng hoặc dịch vụ chịu trách nhiệm gửi event vào Kafka. Đây có thể là backend service, hệ thống tracking, connector, ứng dụng IoT hoặc một thành phần ETL.
Điều quan trọng là producer không chỉ “đẩy dữ liệu vào topic”. Trong thực tế, producer còn tham gia vào nhiều quyết định kỹ thuật như:
- Gửi dữ liệu vào topic nào
- Chọn partition theo key hay round-robin
- Có yêu cầu ack từ broker hay không
- Có nén dữ liệu hay không
- Có retry khi lỗi hay không
Những lựa chọn này ảnh hưởng trực tiếp đến độ trễ, độ bền dữ liệu và tính nhất quán khi hệ thống chạy ở quy mô lớn. Vì vậy, producer trong Kafka không đơn thuần là bên gửi, mà là thành phần đầu tiên quyết định chất lượng của pipeline event streaming.
Consumer
Nếu producer là nơi tạo dòng dữ liệu, thì consumer là nơi chuyển dữ liệu đó thành hành động thực tế. Consumer có thể đọc event để cập nhật database, gửi notification, đồng bộ hệ thống, tính toán realtime, kích hoạt workflow hoặc đẩy dữ liệu sang kho phân tích.
Kafka không ép consumer phải đọc dữ liệu ngay khi event xuất hiện. Thay vào đó, consumer chủ động pull dữ liệu từ broker. Mô hình này giúp hệ thống tiêu thụ linh hoạt hơn, tránh tình trạng bị “đẩy ngập” dữ liệu như một số kiến trúc push-based.
Điểm mạnh của Kafka nằm ở chỗ nhiều consumer khác nhau có thể cùng đọc một topic cho các mục đích khác nhau mà không ảnh hưởng lẫn nhau. Một luồng event phát sinh từ hệ thống thanh toán có thể đồng thời được dùng cho fraud detection, billing, BI dashboard và email automation.
Topic
 Topic có thể hiểu là “kênh logic” nơi event được ghi và đọc. Nhưng nếu chỉ dừng ở định nghĩa đó thì chưa đủ. Trong kiến trúc Kafka, topic là lớp tổ chức dữ liệu theo miền nghiệp vụ hoặc loại sự kiện.
Topic có thể hiểu là “kênh logic” nơi event được ghi và đọc. Nhưng nếu chỉ dừng ở định nghĩa đó thì chưa đủ. Trong kiến trúc Kafka, topic là lớp tổ chức dữ liệu theo miền nghiệp vụ hoặc loại sự kiện.
Chẳng hạn, một hệ thống thương mại điện tử có thể có các topic như order-created, payment-success, inventory-updated, user-clickstream. Việc tách topic rõ ràng giúp hệ thống dễ quản lý, dễ phân quyền và dễ mở rộng pipeline xử lý.
Topic không phải là một file hay một queue đơn lẻ. Bên dưới topic là tập hợp các partition. Chính partition mới là nơi dữ liệu thực sự được ghi xuống đĩa và phục vụ đọc/ghi. Đây là lý do khi thiết kế Kafka, không thể chỉ nghĩ ở mức “tạo topic”, mà phải tính luôn cách chia partition, retention, replication factor và pattern tiêu thụ sau này.
Partition
Partition là đơn vị lưu trữ vật lý nhỏ nhất của một topic. Một topic có thể có một hoặc nhiều partition, và mỗi partition là một log append-only, nghĩa là dữ liệu mới luôn được ghi nối tiếp ở cuối.
Đây là cơ chế quan trọng nhất giúp Kafka đạt throughput cao. Khi một topic có nhiều partition, dữ liệu có thể được phân tán lên nhiều broker khác nhau, cho phép ghi và đọc song song. Nói cách khác, Kafka scale không phải bằng cách tăng kích thước một queue duy nhất, mà bằng cách chia dữ liệu thành nhiều partition để phân tán tải.
Tuy nhiên, partition không chỉ đem lại lợi ích về hiệu năng. Nó cũng đặt ra bài toán thiết kế: càng nhiều partition thì khả năng song song càng cao, nhưng chi phí quản trị, đồng bộ replica, leader election và rebalancing cũng tăng lên. Vì vậy, số lượng partition luôn là quyết định kiến trúc cần được tính toán dựa trên throughput kỳ vọng, mức độ song song của consumer và kế hoạch mở rộng dài hạn.
Offset
Mỗi record trong partition được gán một offset tăng dần theo thứ tự ghi. Offset không phải ID toàn cục của toàn bộ Kafka, mà chỉ có ý nghĩa trong phạm vi từng partition.
Offset giúp consumer biết mình đang đọc tới đâu. Nhờ đó, consumer có thể tạm dừng rồi tiếp tục, replay lại dữ liệu cũ, hoặc phục hồi sau sự cố mà không mất trạng thái xử lý. Đây là một trong những điểm khiến Kafka vượt xa mô hình queue truyền thống: dữ liệu không bị “biến mất” ngay sau khi đọc, mà có thể được giữ lại theo retention policy để phục vụ nhiều mục đích khác nhau.
Ở góc độ hệ thống, offset chính là cơ sở để xây dựng khả năng fault-tolerance cho consumer. Nếu quản lý offset tốt, doanh nghiệp có thể triển khai pipeline có khả năng khôi phục, audit và reprocessing dữ liệu với độ tin cậy cao.
Consumer Group
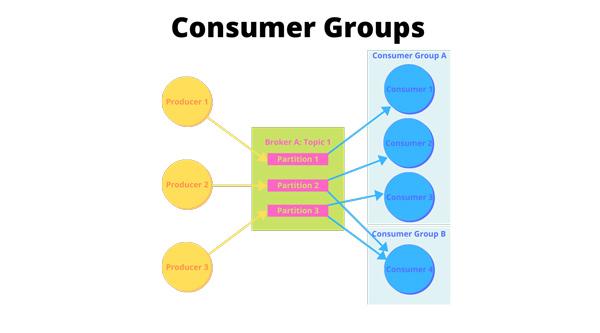 Khi một ứng dụng cần đọc dữ liệu với quy mô lớn, chỉ một consumer là không đủ. Lúc này, Kafka sử dụng consumer group để chia tải.
Khi một ứng dụng cần đọc dữ liệu với quy mô lớn, chỉ một consumer là không đủ. Lúc này, Kafka sử dụng consumer group để chia tải.
Trong một consumer group, mỗi partition chỉ được một consumer đọc tại một thời điểm. Điều đó đảm bảo dữ liệu trong cùng một partition không bị xử lý trùng trong cùng một group. Nếu topic có 6 partition và group có 3 consumer, Kafka sẽ phân phối các partition cho 3 consumer đó. Nếu thêm consumer mới hoặc một consumer bị lỗi, Kafka sẽ thực hiện rebalancing để phân chia lại.
Cơ chế này tạo ra khả năng scale-out rất quan trọng: tăng năng lực xử lý bằng cách thêm consumer instance. Tuy nhiên, nó cũng có nghĩa là mức song song tối đa của một consumer group bị giới hạn bởi số partition. Đây là lý do trong Kafka, thiết kế partition luôn phải đi cùng với chiến lược tiêu thụ.
Cluster và Node
Kafka cluster là tập hợp nhiều broker cùng vận hành như một hệ thống thống nhất. Mỗi node thường là một máy chủ hoặc instance độc lập trong hạ tầng triển khai. Việc tổ chức Kafka theo cluster giúp hệ thống không phụ thuộc vào một máy đơn lẻ.
Khi một broker gặp lỗi, các replica trên broker khác có thể được dùng để duy trì khả năng phục vụ. Càng đi vào production, khái niệm cluster càng quan trọng vì nó liên quan đến replication, leader-follower model, fault tolerance, rolling upgrade và disaster recovery.
Thực tế, Kafka không mạnh vì chỉ xử lý nhanh, mà vì nó xử lý nhanh trong khi vẫn duy trì được khả năng chịu lỗi ở quy mô phân tán.
Zookeeper và sự dịch chuyển sang kiến trúc mới
Trong thời gian dài, Zookeeper là thành phần được dùng để quản lý metadata của cluster Kafka, theo dõi broker, hỗ trợ election và lưu một số trạng thái hệ thống. Nhưng đây cũng là một phần khiến vận hành Kafka trở nên phức tạp, bởi doanh nghiệp phải quản trị thêm một hệ thống phân tán độc lập.
Các phiên bản Kafka mới đang dần loại bỏ phụ thuộc này để chuyển sang kiến trúc hiện đại hơn. Điều đó phản ánh một xu hướng rõ ràng: Kafka không chỉ phát triển về hiệu năng mà còn đang được đơn giản hóa ở mặt vận hành, giúp phù hợp hơn với nhu cầu triển khai cloud-native và managed service.
Điều gì khiến việc hiểu đúng thuật ngữ Kafka trở nên quan trọng?
Rất nhiều đội ngũ học Kafka bằng cách ghi nhớ khái niệm rời rạc: topic là gì, partition là gì, offset là gì. Nhưng khi bắt tay vào triển khai thực tế, các vấn đề thường không nằm ở phần định nghĩa, mà nằm ở cách các thành phần tương tác với nhau.
Ví dụ, nếu chọn sai số partition, consumer group sẽ không scale như mong muốn. Nếu quản lý offset không tốt, dữ liệu có thể bị xử lý lặp hoặc bỏ sót. Nếu thiết kế topic kém, pipeline sẽ khó mở rộng về sau. Nếu cấu hình producer không phù hợp, hệ thống có thể giảm độ bền hoặc tăng độ trễ ngoài kiểm soát.
Vì vậy, hiểu thuật ngữ Kafka không phải để “học thuộc”, mà để xây được tư duy kiến trúc dữ liệu thời gian thực.
Từ hiểu Kafka đến triển khai Kafka hiệu quả
Kafka rất mạnh, nhưng cũng không phải công nghệ dễ vận hành nếu doanh nghiệp tự triển khai từ đầu. Khi hệ thống bắt đầu đi vào production, đội ngũ phải xử lý thêm nhiều lớp phức tạp như cấu hình cluster, giám sát broker, bảo mật kết nối, nâng cấp phiên bản, theo dõi topic, kiểm soát consumer lag, mở rộng partition và duy trì tính sẵn sàng cao.
Đó là lý do nhiều doanh nghiệp chuyển sang dùng giải pháp Kafka managed service để giảm tải vận hành hạ tầng. Theo nội dung gốc, Bizfly Cloud Kafka được định hướng như một nền tảng giúp tự động hóa quản lý, mở rộng cluster linh hoạt, theo dõi metrics trên một dashboard tập trung, đồng thời hỗ trợ cơ chế bảo mật, mã hóa và kiểm soát truy cập để đơn giản hóa quá trình khai thác Kafka trong môi trường thực tế.
Kết luận
Kafka không chỉ là công cụ truyền message giữa các hệ thống. Nó là nền tảng event streaming được xây dựng để lưu trữ, phân phối và xử lý dữ liệu liên tục trong môi trường phân tán. Khi nắm chắc các khái niệm như broker, producer, consumer, topic, partition, offset hay consumer group, bạn sẽ không chỉ hiểu Kafka đang hoạt động thế nào, mà còn biết cách thiết kế pipeline dữ liệu ổn định, có khả năng mở rộng và đủ bền cho production.
Tham khảo: https://bizflycloud.vn/tin-tuc/cac-thuat-ngu-trong-kafka-20221226144421179.htm
All rights reserved
