Giải mã captchas với Python
Bài đăng này đã không được cập nhật trong 6 năm
Như chúng ta đều biết, captcha là những thứ gây phiền nhiễu như "Nhập các chữ cái bạn nhìn thấy trên hình ảnh" trên các trang đăng ký hoặc phản hồi.
CAPTCHA được thiết kế để con người có thể hiểu văn bản mà không gặp khó khăn, trong khi máy thì không thể. Nhưng trên thực tế, điều này thường không có tác dụng, bởi vì hầu hết mọi captcha văn bản đơn giản được đăng lên trang web đều bị bẻ khóa sau vài tháng. Một ít lâu sau ReCaptcha v2 ra mắt với độ phức tạp hơn nhiều, nhưng nó vẫn có thể được bỏ qua trong chế độ tự động.
Trong khi cuộc đấu tranh giữa các nhà sản xuất captcha và người giải captcha dường như là vô tận, những người khác nhau quan tâm đến cách giải mã captcha tự động để duy trì hoạt động của phần mềm của họ. Đó là lý do tại sao trong bài viết cụ thể này, tôi sẽ trình bày cách bẻ khóa văn bản captcha bằng phương pháp OCR.
Tất cả các ví dụ được viết bằng Python 2.5 sử dụng thư viện PIL. Nó cũng sẽ hoạt động trong Python 2.6 và nó đã được test thành công trong Python 2.7.3.
Python: www.python.org
PIL: www.pythonware.com/products/pil
Cài đặt chúng theo thứ tự trên và bạn đã sẵn sàng để chạy các ví dụ.
Ngoài ra, trong các ví dụ tôi sẽ đặt nhiều giá trị trực tiếp trong mã. Tôi không có mục tiêu tạo ra một trình nhận dạng captcha phổ thông, mà mục tiêu chính chỉ để cho thấy cách thức việc này được thực hiện.
CAPTCHA: Nó thực sự là gì?
Chủ yếu captcha là một ví dụ về chuyển đổi một chiều. Bạn có thể dễ dàng lấy một bộ ký tự và nhận captcha từ nó, nhưng không phải ngược lại. Một sự tinh tế khác - nó sẽ dễ dàng cho con người đọc, nhưng không thể nhận ra bởi máy. CAPTCHA có thể được coi là một thử nghiệm đơn giản như "Bạn có phải là con người không?" Về cơ bản, chúng được thực hiện dưới dạng một hình ảnh với một số biểu tượng hoặc từ.
Chúng được sử dụng để ngăn chặn thư rác trên nhiều trang web. Ví dụ: captcha có thể được tìm thấy trên trang đăng ký của Windows Live ID.
Bạn sẽ được xem một hình ảnh và nếu bạn là người thật, thì bạn cần nhập văn bản trong ảnh vào một trường riêng. Có vẻ như một ý tưởng tốt có thể bảo vệ khỏi hàng ngàn đăng ký tự động để spam hoặc phân phối Viagra trên các diễn đàn, phải không? Vấn đề là AI, và đặc biệt là các phương pháp nhận dạng hình ảnh, đã trải qua những thay đổi đáng kể và đang trở nên rất hiệu quả trong một số lĩnh vực nhất định. OCR (Nhận dạng ký tự quang học) ngày nay khá chính xác và dễ dàng nhận ra văn bản in. Vì vậy, các nhà sản xuất captcha đã quyết định thêm một chút màu sắc và đường kẻ vào captcha để làm cho máy tính khó giải quyết hơn, nhưng không gây thêm bất kỳ sự bất tiện nào cho người dùng. Đây là một loại chạy đua vũ trang và như thường lệ, một nhóm xuất hiện những vũ khí mạnh hơn cho mọi hàng phòng thủ do một nhóm khác chế tạo. Đánh bại một captcha được củng cố như vậy là khó khăn hơn, nhưng vẫn có thể. Thêm vào đó, hình ảnh vẫn khá đơn giản để không gây khó chịu ở người bình thường.
![]()
Hình ảnh này là một ví dụ về captcha thực mà chúng ta sẽ giải mã. Đây là một captcha thực được đăng trên một trang web thực sự.
Đó là một captcha khá đơn giản, bao gồm các ký tự có cùng màu và kích thước trên nền trắng với một số nhiễu (pixel, màu sắc, đường kẻ). Bạn có thể nghĩ rằng các hình nhiễu trên nền này sẽ gây khó khăn cho việc nhận ra, nhưng tôi sẽ chỉ ra cách dễ dàng để loại bỏ nó. Mặc dù đây không phải là một captcha rất mạnh, nhưng nó là một ví dụ tốt cho chương trình của chúng ta.
Cách tìm và trích xuất văn bản từ hình ảnh
Có nhiều phương pháp để xác định vị trí của văn bản trên hình ảnh và trích xuất nó. Bạn có thể google và tìm thấy hàng ngàn bài viết giải thích các phương pháp và thuật toán mới để định vị văn bản.
Trong ví dụ này tôi sẽ sử dụng trích xuất màu. Đây là một kỹ thuật khá đơn giản mà tôi nhận được kết quả khá tốt.
Đối với các ví dụ của chúng ta, tôi sẽ sử dụng thuật toán multi-valued image decomposition. Về bản chất, điều này có nghĩa là trước tiên chúng ta vẽ biểu đồ màu sắc của hình ảnh. Điều này được thực hiện bằng cách lấy tất cả các pixel trên ảnh được nhóm theo màu, và sau đó việc đếm được thực hiện cho từng nhóm. Nếu bạn nhìn vào captcha thử nghiệm của chúng tôi, bạn có thể thấy ba màu chính:
Trắng (Nền)
Xám (tiếng ồn)
Màu đỏ (văn bản)
Trong Python, điều này sẽ trông rất đơn giản.
Đoạn mã sau sẽ mở hình ảnh, chuyển đổi nó thành GIF (chúng ta dễ dàng làm việc hơn vì nó chỉ có 255 màu) và in một biểu đồ màu:
from PIL import Image
im = Image.open("captcha.gif")
im = im.convert("P")
print im.histogram()
Kết quả chúng ta nhận được như sau:

Ở đây chúng ta thấy số pixel của mỗi màu trong số 255 màu trên ảnh. Bạn có thể thấy rằng màu trắng (255, số cuối cùng) được tìm thấy thường xuyên nhất. Nó được theo sau bởi màu đỏ (văn bản). Để xác minh điều này, chúng ta sẽ viết một đoạn script nhỏ:
from PIL import Image
from operator import itemgetter
im = Image.open("captcha.gif")
im = im.convert("P")
his = im.histogram()
values = {}
for i in range(256):
values[i] = his[i]
for j,k in sorted(values.items(), key=itemgetter(1), reverse=True)[:10]:
print j,k
Và chúng ta nhận được dữ liệu sau:
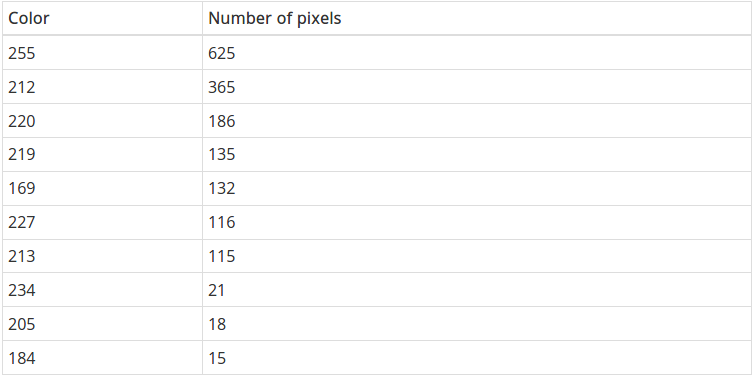
Đây là danh sách 10 màu phổ biến nhất trên ảnh. Như mong đợi, màu trắng lặp lại thường xuyên nhất. Sau đó đến màu xám và đỏ.
Khi chúng ta nhận được thông tin này, chúng ta tạo ra hình ảnh mới dựa trên các nhóm màu này. Đối với mỗi màu phổ biến nhất, chúng ta tạo một hình ảnh nhị phân mới (gồm 2 màu), trong đó các pixel của màu này được lấp đầy bằng màu đen và mọi thứ khác đều có màu trắng.
Màu đỏ đã trở thành màu thứ ba trong số các màu phổ biến nhất, có nghĩa là chúng tôi muốn lưu một nhóm pixel có màu 220. Khi tôi thử nghiệm, tôi thấy rằng màu 227 khá gần với 220, vì vậy chúng ta cũng sẽ giữ nhóm này. Mã bên dưới mở captcha, chuyển đổi nó thành GIF, tạo một hình ảnh mới có cùng kích thước với nền trắng và sau đó đi qua hình ảnh gốc để tìm kiếm màu chúng ta cần. Nếu anh ta tìm thấy một pixel với màu chúng ta cần, thì anh ta đánh dấu pixel đó trên ảnh thứ hai là màu đen. Trước khi tắt, hình ảnh thứ hai được lưu.
from PIL import Image
im = Image.open("captcha.gif")
im = im.convert("P")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix == 220or pix == 227: _# Đây là các màu được lấy_
im2.putpixel((y,x),0)
im2.save("output.gif")
Chạy đoạn mã trên cho chúng ta kết quả như sau.

Trên hình bạn có thể thấy rằng chúng ta đã có thể trích xuất văn bản từ nền. Để tự động hóa quá trình này, bạn có thể kết hợp tập lệnh thứ nhất và thứ hai.
Tôi nghe bạn hỏi: "Nếu văn bản trên hình ảnh xác thực được viết bằng các màu khác nhau thì sao?". Vâng, công nghệ của chúng tôi vẫn có thể làm việc. Giả sử màu phổ biến nhất là màu nền và sau đó bạn có thể tìm thấy màu của các ký tự.
Vì vậy, tại thời điểm này, chúng ta đã trích xuất thành công văn bản từ hình ảnh. Bước tiếp theo là xác định xem hình ảnh có chứa văn bản không. Tôi sẽ không viết mã ở đây, bởi vì nó sẽ làm cho việc hiểu khó khăn, trong khi bản thân thuật toán khá đơn giản.
for each binary image:
for each pixel in the binary image:
if the pixel is on:
if any pixel we have seen before is next to it:
add to the same set
else:
add to a new set
Ở đầu ra, bạn sẽ có một tập hợp các ranh giới ký tự. Sau đó, tất cả những gì bạn cần làm là so sánh chúng với nhau và xem liệu chúng có đi theo tuần tự không. Nếu có, thì đó là giải độc đắc vì bạn đã xác định chính xác các ký tự tiếp theo. Bạn cũng có thể kiểm tra kích thước của các khu vực nhận được hoặc chỉ cần tạo một hình ảnh mới và hiển thị nó (áp dụng phương thức show() cho hình ảnh) để đảm bảo thuật toán chính xác.
from PIL import Image
im = Image.open("captcha.gif")
im = im.convert("P")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix == 220or pix == 227: # these are the numbers to get_
im2.putpixel((y,x),0)
# new code starts here_
inletter = False
foundletter=False
start = 0
end = 0
letters = []
for y in range(im2.size[0]): _# slice across_
for x in range(im2.size[1]): _# slice down_
pix = im2.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == Falseand inletter == True:
foundletter = True
start = y
if foundletter == Trueand inletter == False:
foundletter = False
end = y
letters.append((start,end))
inletter=False
print letters
Kết quả chúng ta đã nhận được như sau:
[(6, 14), (15, 25), (27, 35), (37, 46), (48, 56), (57, 67)]
Đây là các vị trí ngang của đầu và cuối của mỗi kí tự.
AI và vector để nhận dạng mẫu
Nhận dạng hình ảnh có thể được coi là thành công lớn nhất của AI hiện đại, cho phép nó được nhúng trong tất cả các loại ứng dụng thương mại. Một ví dụ tuyệt vời về điều này là mã zip. Trên thực tế, ở nhiều quốc gia, chúng được đọc tự động, bởi vì dạy máy tính nhận biết số là một công việc khá đơn giản. Điều này có thể không rõ ràng, nhưng nhận dạng mẫu được coi là một vấn đề AI, một vấn đề chuyên môn cao là đằng khác.
Gần như thuật toán đầu tiên bạn gặp phải khi gặp một AI nhận dạng mẫu là mạng lưới thần kinh. Cá nhân, tôi chưa bao giờ thành công với mạng lưới thần kinh trong nhận dạng nhân vật. Tôi thường dạy nó 3-4 ký tự, sau đó độ chính xác giảm xuống thấp đến mức nó sẽ cao hơn sau đó đoán ngẫu nhiên các ký tự. May mắn thay, tôi đã đọc một bài viết về các công cụ tìm kiếm không gian vector và tìm thấy một phương pháp thay thế để phân loại dữ liệu. Cuối cùng, hóa ra đây là lựa chọn tốt nhất, bởi vì:
-
Nó không yêu cầu nghiên cứu sâu rộng. -
Bạn có thể thêm / xóa dữ liệu không chính xác và thấy ngay kết quả -
Nó dễ hiểu và dễ lập trình hơn. -
Nó cung cấp kết quả được phân loại để bạn có thể xem các kết quả chính xác hàng đầu. -
Không thể nhận ra một cái gì đó? Thêm cái này và bạn sẽ có thể nhận ra nó ngay lập tức, ngay cả khi nó hoàn toàn khác với thứ được nhìn thấy trước đó.
Tất nhiên, không có phô mai miễn phí. Nhược điểm chính về tốc độ. Chúng có thể chậm hơn nhiều so với mạng lưới thần kinh. Nhưng tôi nghĩ rằng lợi thế của họ vẫn vượt trội hơn nhược điểm này.
Nếu bạn muốn hiểu làm thế nào không gian vector hoạt động, thì tôi khuyên bạn nên đọc Vector Space Search Engine Theory. Đây là thứ tốt nhất tôi tìm thấy cho người mới bắt đầu và tôi đã xây dựng nhận dạng hình ảnh của mình dựa trên tài liệu này. Bây giờ chúng ta phải lập trình không gian vector của chúng ta. May mắn thay, điều này không hề khó khăn. Bắt đầu nào.
import math
class VectorCompare:
def magnitude(self,concordance):
total = 0
for word,count in concordance.iteritems():
total += count \*\* 2
return math.sqrt(total)
def relation(self,concordance1, concordance2):
relevance = 0
topvalue = 0
for word, count in concordance1.iteritems():
if concordance2.has\_key(word):
topvalue += count \* concordance2[word]
return topvalue / (self.magnitude(concordance1) \* self.magnitude(concordance2))
Đây là một triển khai không gian vector của Python trong 15 dòng. Về cơ bản, nó chỉ dùng 2 dictionaries và trả về một số từ 0 đến 1, cho biết cách chúng được kết nối. 0 có nghĩa là chúng không được kết nối và 1 có nghĩa là chúng giống hệt nhau.
Đào tạo
Điều tiếp theo chúng ta cần là một tập hợp các hình ảnh mà chúng ta sẽ so sánh các nhân vật của mình. Chúng ta cần một bộ học tập. Bộ này có thể được sử dụng để đào tạo bất kỳ loại AI nào mà chúng ta sẽ sử dụng (mạng lưới thần kinh, v.v.).
Dữ liệu được sử dụng có thể rất quan trọng cho sự thành công của sự công nhận. Dữ liệu càng tốt, cơ hội thành công càng lớn. Vì chúng tôi dự định nhận ra một hình ảnh xác thực cụ thể và đã có thể trích xuất các biểu tượng từ nó, tại sao không sử dụng chúng làm tập huấn luyện?
Đây là những gì tôi đã làm. Tôi đã tải xuống rất nhiều captcha được tạo và chương trình của tôi đã chia chúng thành các chữ cái. Sau đó, tôi thu thập những hình ảnh nhận được trong một bộ sưu tập (nhóm). Sau nhiều lần thử, tôi đã có ít nhất một ví dụ về mỗi ký tự được tạo bởi captcha. Thêm nhiều ví dụ sẽ tăng độ chính xác nhận dạng, nhưng điều này là đủ để tôi xác nhận lý thuyết của mình.
from PIL import Image
import hashlib
import time
im = Image.open("captcha.gif")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
print im.histogram()
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix == 220or pix == 227: # these are the numbers to get
im2.putpixel((y,x),0)
inletter = False
foundletter=False
start = 0
end = 0
letters = []
for y in range(im2.size[0]): _# slice across_
for x in range(im2.size[1]): _# slice down_
pix = im2.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == Falseand inletter == True:
foundletter = True
start = y
if foundletter == Trueand inletter == False:
foundletter = False
end = y
letters.append((start,end))
inletter=False
# New code is here. We just extract each image and save it to disk with
# what is hopefully a unique name
count = 0
for letter in letters:
m = hashlib.md5()
im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] ))
m.update("%s%s"%(time.time(),count))
im3.save("./%s.gif"%(m.hexdigest()))
count += 1
Ở đầu ra, chúng ta nhận được một tập hợp các hình ảnh trong cùng một thư mục. Mỗi người trong số họ được chỉ định một hàm băm duy nhất trong trường hợp bạn xử lý một số captcha.
Đây là kết quả của mã này cho captcha thử nghiệm của chúng ta:
![]()
Bạn quyết định làm thế nào để lưu trữ những hình ảnh này, nhưng tôi chỉ đặt chúng trong một thư mục có cùng tên trên hình ảnh (ký hiệu hoặc số).
Ghép tất cả chúng cùng nhau
Bước cuối cùng. Chúng tôi có trích xuất văn bản, trích xuất ký tự, kỹ thuật nhận dạng và tập huấn luyện.
Chúng ta nhận được một hình ảnh của captcha, chọn văn bản, nhận các ký tự và sau đó so sánh chúng với dữ liệu tập huấn luyện của chúng ta. Bạn có thể tải xuống chương trình cuối cùng với một bộ huấn luyện và một số lượng nhỏ captcha tại liên kết này.
Ở đây chúng ta chỉ cần tải tập huấn luyện để có thể so sánh captcha của chúng ta với nó:
def buildvector(im):
d1 = {}
count = 0
for i in im.getdata():
d1[count] = i
count += 1
return d1
v = VectorCompare()
iconset =
['0','1','2','3','4','5','6','7','8','9','0','a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
imageset = []
for letter in iconset:
for img in os.listdir('./iconset/%s/'%(letter)):
temp = []
if img != "Thumbs.db":
temp.append(buildvector(Image.open("./iconset/%s/%s"%(letter,img))))
imageset.append({letter:temp})
Và sau đó tất cả các phép thuật xảy ra. Chúng ta xác định vị trí của từng kí tự và kiểm tra nó với không gian vector của chúng ta. Sau đó, chúng tôi sắp xếp kết quả và in chúng.
count = 0
for letter in letters:
m = hashlib.md5()
im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] ))
guess = []
for image in imageset:
for x,y in image.iteritems():
if len(y) != 0:
guess.append( ( v.relation(y[0],buildvector(im3)),x) )
guess.sort(reverse=True)
print"",guess[0]
count += 1
Kết luận về việc giải captcha đơn giản
Bây giờ chúng ta có mọi thứ chúng ta cần và chúng ta có thể thử khởi chạy máy của mình.
Tệp đầu vào là captcha.gif. Kết quả dự kiến: 7s9t9j
python crack.py
(0.96376811594202894, '7')
(0.96234028545977002, 's')
(0.9286884286888929, '9')
(0.98350370609844473, 't')
(0.96751165072506273, '9')
(0.96989711688772628, 'j')
Ở đây chúng ta có thể thấy biểu tượng chính xác và mức độ tin cậy của nó (từ 0 đến 1).
Vì vậy, có vẻ như chúng ta thực sự đã thành công!
Trên thực tế, trong thử nghiệm captchas, kịch bản này sẽ tạo ra kết quả thành công chỉ trong khoảng 22% trường hợp.
python crack\_test.py
Correct Guesses - 11.0
Wrong Guesses - 37.0
Percentage Correct - 22.9166666667
Percentage Wrong - 77.0833333333
Hầu hết các kết quả không chính xác có liên quan đến việc nhận dạng không chính xác chữ số "0" và chữ "O", điều này không thực sự bất ngờ, vì ngay cả mọi người thường nhầm lẫn chúng. Ngoài ra, chúng ta vẫn có một vấn đề với việc tách captcha thành các ký tự, nhưng điều này có thể được giải quyết đơn giản bằng cách kiểm tra kết quả của việc phá vỡ và tìm một điểm giữa.
Tuy nhiên, ngay cả với một thuật toán không hoàn hảo như vậy, chúng ta có thể giải chính xác từng captcha thứ năm và nó sẽ nhanh hơn một người thực sự có thể giải một.
Chạy mã này trên Core 2 Duo E6550 cho kết quả như sau:
- real 0m5.750s
- user 0m0.015s
- sys 0m0.000s
Với tỷ lệ thành công 22%, chúng tôi có thể giải quyết khoảng 432.000 captcha mỗi ngày và nhận được 95.040 kết quả chính xác. Hãy tưởng tượng chúng ta sử dụng đa luồng thì sẽ thế nào.
All rights reserved
