Giác ngộ về index trong cơ sở dữ liệu oracle
1. Mở đầu
Chào mừng anh em đến với series "Giác ngộ index", trong hành trình thỉnh kinh qua các bài viết. Mỗi bài viết sẽ là một thử thách, từ những vấn đề cơ bản đến những khía cạnh nâng cao. Chúng ta sẽ cùng nhau đối mặt với những thử thách và kiếp nạn của index như những người hành hương tìm kiếm sự giác ngộ.
2. Các khái niệm cơ bản
Khi truy cập dữ liệu từ các bảng, Oracle có hai lựa chọn: đọc toàn bộ hàng trong bảng (còn gọi là full table scan) hoặc truy cập từng hàng một qua ROWID. Khi cần truy xuất một tỷ lệ nhỏ các hàng của một bảng lớn, chúng ta sẽ muốn sử dụng chỉ mục (index). Ví dụ, nếu chúng ta chỉ muốn chọn 5% số hàng trong một bảng rất lớn, chúng ta sẽ thực hiện ít thao tác I/O hơn nếu sử dụng index để xác định các block cần đọc. Nếu không sử dụng index, chúng ta sẽ phải đọc tất cả các block trong bảng.
Mức độ mà index cải thiện hiệu suất phụ thuộc vào độ chọn lọc của dữ liệu và cách dữ liệu được phân bố trong các block của bảng. Nếu dữ liệu có độ chọn lọc cao, chỉ có một số ít hàng trong bảng khớp với giá trị index (ví dụ như số hộ chiếu, số căn cước công dân). Oracle có thể nhanh chóng truy vấn index để lấy các ROWID khớp, và các block bảng liên quan sẽ được truy vấn nhanh chóng. Ngược lại, nếu dữ liệu không chọn lọc nhiều (ví dụ tên quốc gia), index có thể trả về nhiều ROWID, dẫn đến việc truy vấn nhiều block khác nhau từ bảng.
Nếu dữ liệu có tính chọn lọc nhưng các hàng liên quan không được lưu gần nhau trong bảng, thì lợi ích của việc sử dụng index sẽ bị giảm đi. Nếu dữ liệu khớp với giá trị index nằm rải rác trong các block của bảng, chúng ta có thể phải chọn nhiều block riêng lẻ từ bảng để hoàn thành truy vấn. Trong một số trường hợp, nếu dữ liệu bị phân tán trong các block của bảng, việc bỏ qua index và thực hiện quét toàn bộ bảng có thể mang lại hiệu quả tốt hơn. Khi thực hiện quét toàn bộ bảng, Oracle sử dụng chế độ đọc multiblock, giúp quét bảng nhanh chóng. Trong khi đó, việc đọc dựa trên index sẽ là đọc từng block một, vì vậy mục tiêu khi sử dụng index là giảm số lượng block cần phải đọc để giải quyết truy vấn.
Với một số tùy chọn có sẵn trong Oracle, như partition, DML song song, các thao tác truy vấn song song, và việc sử dụng I/O lớn hơn nhờ DB_FILE_MULTIBLOCK_READ_COUNT, điểm cân bằng giữa quét toàn bộ bảng và tìm kiếm index đang dần thay đổi. Phần cứng nhanh hơn, đĩa cứng có bộ nhớ đệm lớn hơn, và chi phí ngày càng rẻ. Cùng lúc đó, Oracle cải thiện tính năng index với các index skip-scan và các thao tác nội bộ khác giúp giảm thời gian truy xuất dữ liệu.
TIP
Khi nâng cấp phiên bản Oracle, nhớ kiểm tra truy vấn của ứng dụng để xem execution paths có còn dùng các index như trước khi nâng cấp không. Kiểm tra xem execution plan có thay đổi không và nếu thay đổi thì tốt hơn hay tệ hơn.
Index thường sẽ cải thiện hiệu suất cho các truy vấn. Câu lệnh SELECT, các mệnh đề WHERE của lệnh UPDATE, và các mệnh đề WHERE của câu lệnh DELETE (khi chỉ truy cập một số ít hàng) đều có thể hưởng lợi từ index. Nhìn chung, việc thêm index sẽ làm giảm hiệu suất cho các câu lệnh INSERT (vì cần thực hiện INSERT vào cả bảng và index). Việc UPDATE các cột có index sẽ chậm hơn so với khi các cột không được index, vì cơ sở dữ liệu phải quản lý sự thay đổi cho cả bảng và index. Thêm vào đó, việc DELETE một số lượng lớn hàng sẽ bị chậm lại khi bảng có index.
Để liệt kê tất cả các index trên một bảng, hãy truy vấn DBA_INDEXES view. Ngoài ra, chúng ta có thể lấy các index cho schema của mình bằng cách truy cập vào USER_INDEXES view. Để xem các index trên tất cả các bảng mà chúng ta có quyền truy cập, hãy truy vấn ALL_INDEXES view.
Ví dụ dưới đây minh họa việc tạo các index trên bảng EMP thuộc sở hữu của user SCOTT:

Khi chúng ta thực thi các lệnh đó, cơ sở dữ liệu sẽ tạo hai index riêng biệt trên bảng EMP. Mỗi index sẽ chứa các giá trị được chỉ định từ bảng EMP cùng với các giá trị ROWID cho các hàng khớp với chúng. Nếu chúng ta muốn tìm một bản ghi trong bảng EMP có giá trị SAL là 1000, trình tối ưu hóa (optimizer) có thể sử dụng chỉ mục EMP_ID2 để tìm giá trị đó, sau đó tìm ROWID liên quan trong index và sử dụng ROWID này để tìm đúng hàng trong bảng.
Truy vấn sau đây từ USER_INDEXES view (chúng ta cũng có thể kiểm tra trong DBA_INDEXES view) hiển thị các index mới trên bảng EMP:

Kết quả hiển thị hai index, nhưng không hiển thị các cột trong từng index. Để lấy các cột cụ thể được lập index cho một bảng nhất định của người dùng hiện tại, hãy truy cập vào USER_IND_COLUMNS view. Ngoài ra, các DBA có thể lấy các cột được lập index cho tất cả các schema bằng cách truy cập vào DBA_IND_COLUMNS view. Chúng ta cũng có thể xem các cột được lập index cho tất cả các bảng mà chúng ta có quyền truy cập thông qua ALL_IND_COLUMNS view. Để lấy các cột cụ thể được lập index cho một bảng nhất định, hãy truy cập vào bảng USER_IND_COLUMNS như trong ví dụ sau.
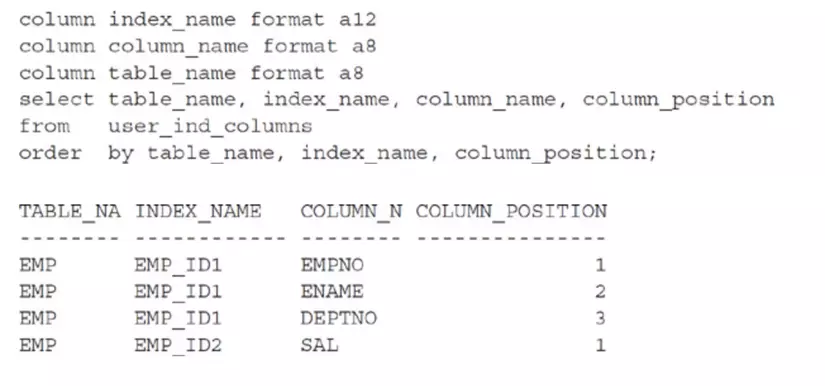
Bảng EMP có hai index. Index đầu tiên, EMP_ID1, là concatenated index, lập index cho các cột EMPNO, ENAME và DEPTNO. Index thứ hai, EMP_ID2, chỉ lập index cho cột SAL. Thứ tự cột (COLUMN_POSITION) hiển thị trong danh sách cho biết thứ tự của các cột trong concatenated index — trong trường hợp này là EMPNO, sau đó là ENAME, rồi đến DEPTNO.
TIP
Truy vấn DBA_INDEXES và DBA_IND_COLUMNS để lấy danh sách các index trên một bảng cụ thể. Sử dụng USER_INDEXES và USER_IND_COLUMNS để lấy thông tin chỉ cho schema của chúng ta.
3. Thông tin kết nối
Nếu anh em muốn trao đổi thêm về bài viết, hãy kết nối với mình qua LinkedIn và Facebook:
- LinkedIn: https://www.linkedin.com/in/nguyentrungnam/
- Facebook: https://www.facebook.com/trungnam.nguyen.395/
Rất mong được kết nối và cùng thảo luận!
All rights reserved
