Gemma 4 12B: Unified & Local AI
Gemma 4 12B là mô hình đa phương thức trong họ Gemma, nhắm vào bài toán cân bằng giữa hiệu năng và khả năng chạy được trên máy cá nhân. Điểm đáng chú ý nhất là kiến trúc: thay vì dùng encoder riêng cho từng loại đầu vào, mô hình ánh xạ tất cả - image, text, audio - vào cùng một không gian vector, rồi xử lý bằng một decoder-only duy nhất. Với 12 tỷ tham số, nó có thể chạy local trên workstation, đủ lớn cho các tác vụ như trợ lý AI hay phân tích tài liệu hỗn hợp.
1. Tổng quan về Gemma 4 12B
- Ở bài viết trước, mình đã viết bài về kiến trúc tổng quan của Gemma 4 - Hybrid Attention, Per-Layer Embeddings, và cách Google tối ưu mô hình cho các kịch bản chạy on-device (bạn có thể đọc ủng hộ bài viết của mình tại đây).
- Bài viết trước đã cung cấp các thông tin chi tiết về model Gemma 4, ở đây mình sẽ liệt kê nhanh một sổ điểm chính trong kiến trúc model:
- Decoder-only Transformer: Gemma 4 vẫn dựa trên kiến trúc decoder-only Transformer, phù hợp với các tác vụ sinh văn bản, hội thoại, reasoning và agentic workflow.
- Hybrid Attention: Mô hình kết hợp giữa Sliding Window Attention và Global Attention để cân bằng giữa khả năng xử lý ngữ cảnh dài và chi phí bộ nhớ trong quá trình inference.
- Long Context: Một số biến thể Gemma 4 hỗ trợ context length rất lớn, giúp mô hình phù hợp với các bài toán đọc tài liệu dài, phân tích mã nguồn hoặc xử lý nhiều thông tin trong một lần nhập.
- Per-Layer Embeddings: Thay vì chỉ phụ thuộc vào embedding đầu vào ban đầu, Gemma 4 bổ sung tín hiệu embedding ở từng lớp, giúp cải thiện khả năng biểu diễn thông tin trong quá trình xử lý.
- Shared KV Cache: Cơ chế chia sẻ Key/Value Cache giữa một số lớp giúp giảm lượng bộ nhớ cần lưu khi sinh văn bản, từ đó hỗ trợ tốt hơn cho triển khai on-device hoặc local.
- Tokenizer lớn: Với vocabulary size khoảng 262K, Gemma 4 có khả năng xử lý đa ngôn ngữ tốt hơn, giảm số token cần dùng cho nhiều ngôn ngữ và đoạn mã nguồn.
- Native Multimodal: Gemma 4 hướng tới xử lý text, image và audio trong cùng một pipeline, đưa các dạng dữ liệu khác nhau về dạng chuỗi vector để LLM có thể suy luận trên một không gian biểu diễn chung.
→ Nhìn chung, kiến trúc Gemma 4 không chỉ tập trung vào việc tăng quy mô mô hình, mà còn tối ưu mạnh cho hiệu quả suy luận, bộ nhớ và khả năng triển khai trên thiết bị cá nhân. Đây là nền tảng quan trọng để hiểu vì sao Gemma 4 12B Unified tiếp tục đi theo hướng hợp nhất kiến trúc và loại bỏ các encoder riêng biệt.
- Với quy mô 12 tỷ tham số, mô hình này hướng tới việc cân bằng giữa hiệu năng, khả năng xử lý đa phương thức và tính khả thi khi triển khai local trên các thiết bị biên.
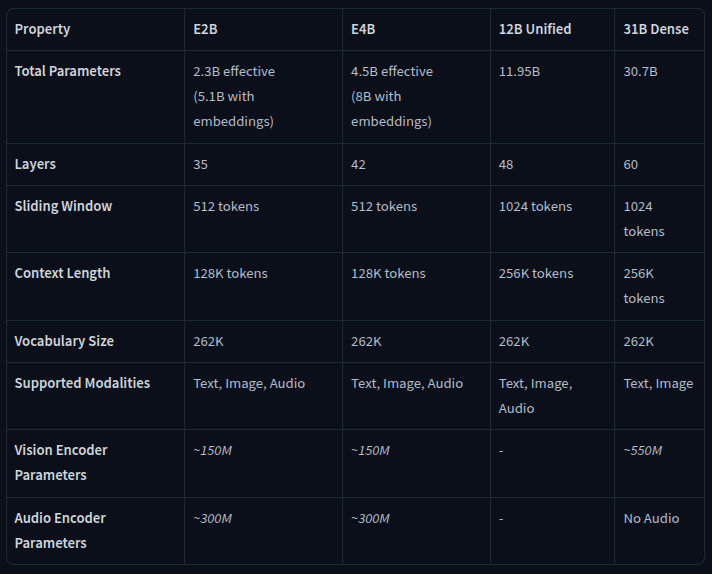
- So với E2B/E4B: Gemma 4 12B Unified có quy mô lớn hơn, nhiều layer hơn và sliding window rộng hơn, nên phù hợp hơn với các tác vụ reasoning và xử lý ngữ cảnh dài.
- So với 31B Dense: 12B Unified nhỏ gọn hơn đáng kể nhưng vẫn giữ context length 256K tokens, giúp việc triển khai local thực tế hơn và nó hỗ trợ cả text, image và audio, trong khi 31B Dense không hỗ trợ audio.
- Đặc biệt, khi so sánh với 26B MoE, model 12B chỉ cần chưa đến một nửa tổng memory footprint nhưng vẫn giữ hiệu năng tiệm cận trên các benchmark tiêu chuẩn.
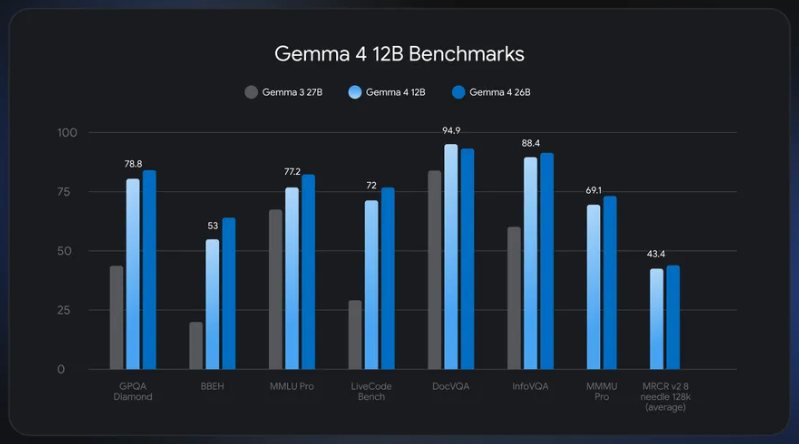
2. Cải tiến chính: Unified, Encoder-Free Architecture
2.1. Từ pipeline encoder riêng sang kiến trúc hợp nhất
Thay đổi đáng chú ý nhất của Gemma 4 12B là cách Google xử lý đa phương thức. Các mô hình multimodal trước thường cần vision encoder hoặc audio encoder riêng để tiền xử lý hình ảnh, âm thanh trước khi đưa sang LLM. Gemma 4 12B bỏ hẳn bước đó — dữ liệu được chiếu thẳng vào không gian vector n chiều qua các lớp ánh xạ nhẹ.
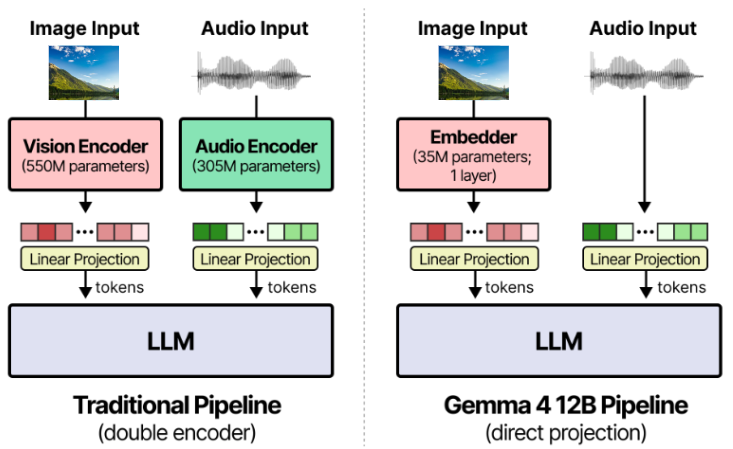
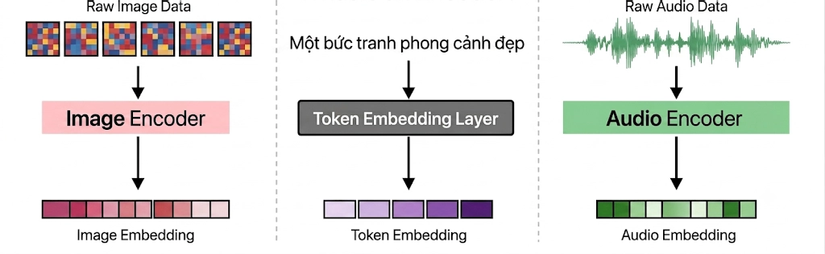
- Ở nhiều mô hình multimodal truyền thống, mỗi loại dữ liệu thường cần một encoder riêng trước khi được đưa vào LLM:
- Vision encoder: dùng để xử lý hình ảnh và trích xuất đặc trưng thị giác.
- Audio encoder: dùng để xử lý tín hiệu âm thanh.
- Connector: dùng để chuyển đầu ra của encoder về không gian biểu diễn phù hợp với LLM.
- Trong họ Gemma 4, các encoder này có quy mô không nhỏ:
- Các bản edge-size sử dụng vision encoder khoảng 150M tham số.
- Các bản medium-size sử dụng vision encoder khoảng 550M tham số.
- Gemma 4 E2B và E4B sử dụng audio encoder khoảng 300M tham số.
- Cách thiết kế này giúp mô hình xử lý tốt từng modality, nhưng cũng tạo ra một số hạn chế:
- Pipeline trở nên phức tạp hơn vì phải duy trì nhiều module riêng biệt.
- Độ trễ tăng do dữ liệu phải đi qua encoder trước khi đến LLM.
- Memory footprint bị phân mảnh giữa vision encoder, audio encoder và LLM backbone.
- Gemma 4 12B Unified giải quyết vấn đề này bằng cách đặt decoder-only Transformer làm trung tâm, image patches và audio frames được đưa trực tiếp vào không gian embedding của LLM thông qua các lớp ánh xạ nhẹ. Sau bước này, text, image và audio đều trở thành các token embedding có cùng định dạng và được xử lý trong cùng một decoder-only Transformer..
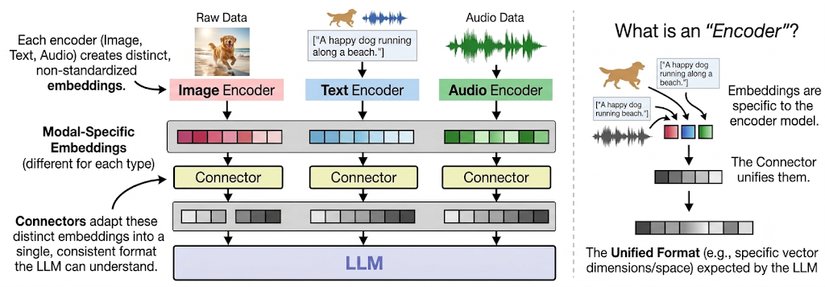
- Mô hình sử dụng cấu trúc decoder tiên tiến tương tự Gemma 4 31B Dense, nhưng loại bỏ các encoder riêng cho vision và audio.
2.2. Chuyển từ Vision Encoder sang Vision Embedder
Với phần xử lý hình ảnh, Gemma 4 12B Unified thay vision encoder nhiều lớp bằng một vision embedder nhẹ hơn đáng kể:
- Quy mô nhỏ hơn: Vision embedder của Gemma 4 12B chỉ khoảng 35M tham số, nhỏ hơn nhiều so với các vision encoder truyền thống trong họ Gemma 4. Điều này giảm số tham số tổng thể của của mô hình giúp giảm kích cỡ và nhẹ hơn để có thể chạy trên các thiết bị thông thường.
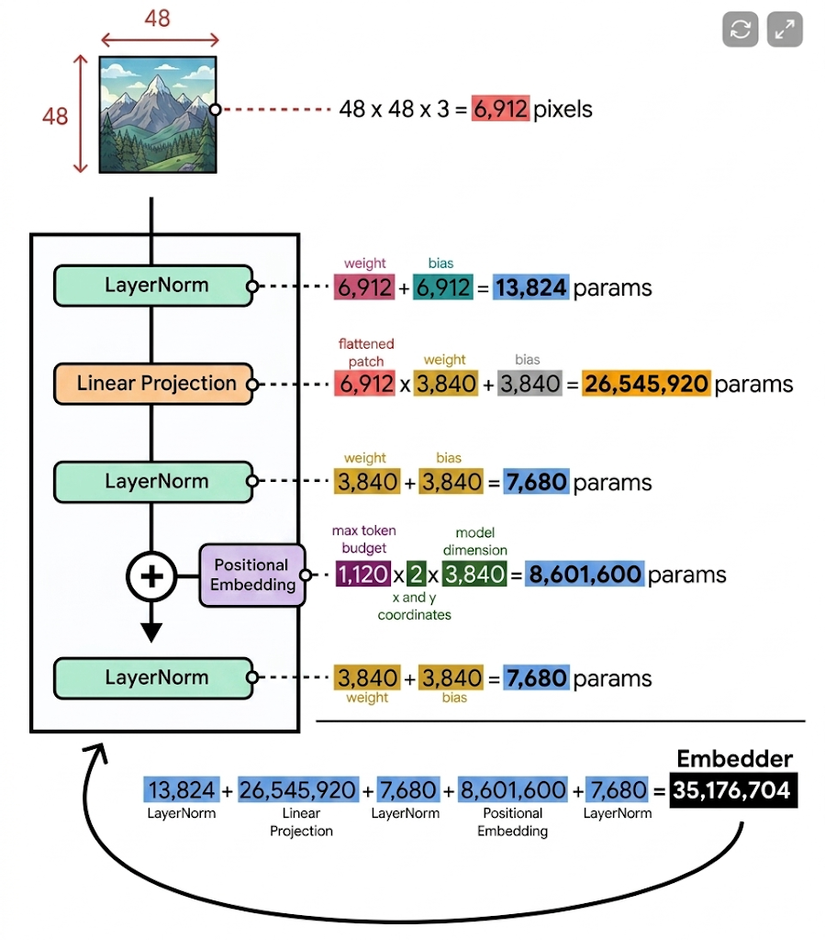
- Không dùng Transformer encoder cho ảnh: Ở các mô hình encoder-based, ảnh thường được đưa qua nhiều lớp Transformer encoder để học quan hệ giữa các vùng ảnh trước khi chuyển sang LLM. Thay vào đó, mô hình 12B xử lý ảnh trực tiếp ở tầng embedding.
- Chia ảnh thành patch cố định: Ảnh đầu vào được chia thành các patch kích thước 48 × 48 pixel. Ở đây, có thể hiểu mỗi patch là một vùng nhỏ của ảnh, tương tự như cách một văn bản được chia thành các token trước khi đưa vào LLM.
- Biến patch ảnh thành vector đầu vào: Với ảnh RGB, mỗi patch 48×48 pixel có 2.304 pixel, tương ứng 48 × 48 × 3 = 6.912 giá trị trên ba kênh R, G, B. Vision embedder lấy vector này và ánh xạ nó sang hidden dimension của LLM, khoảng 3.840 chiều.
- Chiếu tuyến tính vào embedding space của LLM:
- Phép ánh xạ này là một lớp linear projection: từ vector ảnh kích thước 6.912 chiều sang vector embedding kích thước 3.840 chiều. Sau bước này, mỗi patch ảnh trở thành một ‘visual token embedding’ có cùng định dạng với token văn bản thông thường.
- Riêng phép chiếu từ patch ảnh sang embedding space của LLM đã chiếm khoảng 26M tham số. Phần còn lại của vision embedder chủ yếu đến từ embedding vị trí và một số thành phần phụ trợ khác.
- Thông tin vị trí token:
- Vì vision embedder không dùng attention giữa các patch như vision encoder truyền thống, Gemma 4 12B bổ sung thông tin vị trí bằng hai bảng embedding tọa độ X và Y.
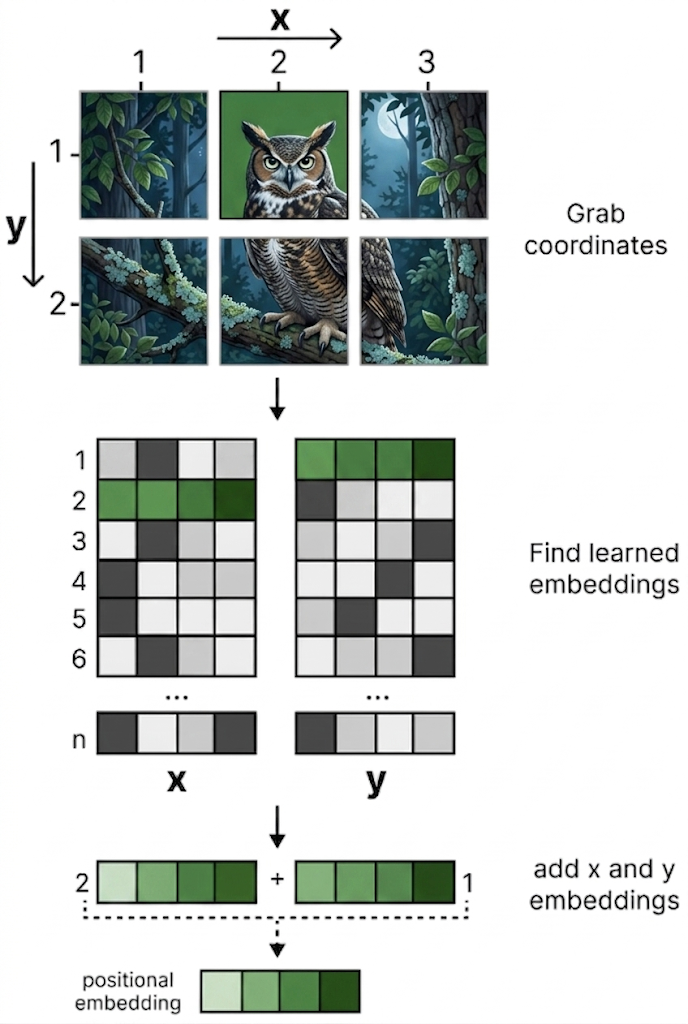
- Kích thước positional embedding: Mỗi bảng tọa độ có kích thước khoảng 1120 × 3840, tương ứng với số lượng patch tối đa và hidden dimension của mô hình.
- Sau positional embedding, mô hình chạy thêm một lớp LayerNorm để ổn định phân phối vector biểu diễn (cùng số chiều). Bước này chuẩn hóa embedding của từng patch trước khi chiếu sang hidden dimension mà LLM mong đợi — để visual token vào decoder không bị lệch phân phối so với token văn bản.
- Ý nghĩa: Nhờ vậy, mỗi visual token mang theo hai thứ trước khi vào LLM: nội dung vùng ảnh và vị trí của nó trong ảnh gốc. Gemma 4 12B giữ được thông tin không gian mà không cần vision encoder nhiều lớp.
2.3. Thay Audio Encoder bằng Audio Projection (phép chiếu)
Với phần xử lý âm thanh, Gemma 4 12B Unified cũng đi theo cùng triết lý encoder-free như phần hình ảnh. Thay vì sử dụng một Audio Encoder riêng để trích xuất đặc trưng từ tín hiệu âm thanh, mô hình đưa audio về dạng token embedding thông qua một phép chiếu nhẹ hơn.
- Xử lý trực tiếp tín hiệu audio thô: Gemma 4 12B bỏ audio encoder riêng và làm việc thẳng với ‘raw audio’:
- Audio được lấy mẫu ở 16 kHz, tức mỗi giây âm thanh cho ra 16.000 giá trị số. Đây là tần số lấy mẫu phổ biến cho giọng nói — đủ để giữ lại thông tin ngôn ngữ mà không cần băng thông cao như audio nhạc.
- Chia audio thành các frame nhỏ: Tín hiệu âm thanh được chia thành các đoạn ngắn có độ dài 40ms. Với tần số lấy mẫu 16 kHz, mỗi frame 40ms tương ứng với khoảng 640 giá trị mẫu.
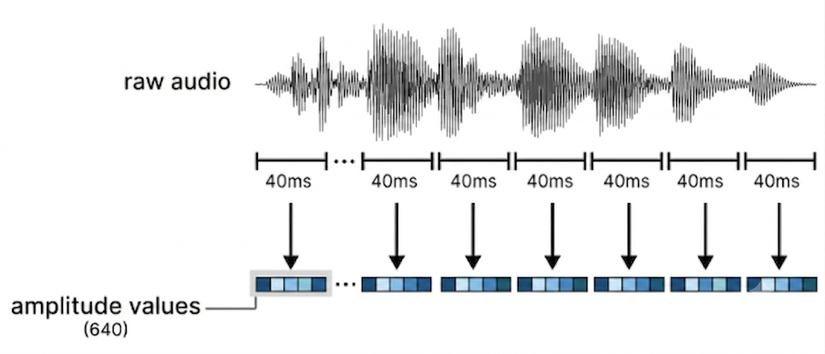
- Chiếu audio frame vào embedding space của LLM: Mỗi frame âm thanh gồm 640 giá trị đầu vào sẽ được ánh xạ tuyến tính sang hidden dimension mà LLM có thể xử lý, khoảng 3.840 chiều. Sau bước này, mỗi frame audio trở thành một audio token embedding.
- Đưa audio vào cùng decoder-only Transformer: Sau khi được chiếu vào không gian embedding, audio token sẽ được xử lý cùng với text token và visual token trong cùng một decoder-only Transformer. Điều này giúp Gemma 4 12B xử lý audio như một phần của chuỗi multimodal thống nhất, thay vì phải duy trì một pipeline âm thanh riêng biệt.
- Ý nghĩa:
- Nhìn vào cách tạo audio token, sự khác biệt giữa Gemma 4 E4B và Gemma 4 12B khá rõ. E4B cần token hóa audio rồi đưa qua encoder riêng trước khi sang LLM. 12B rút ngắn hẳn: audio được chia thành các frame nhỏ rồi chiếu thẳng vào không gian vector n (3840) chiều của LLM
- Gemma 4 12B không chỉ là bản nằm giữa E4B và 26B A4B về quy mô. Nó thay đổi cách xử lý đa phương thức — thay encoder riêng bằng cơ chế split-and-project nhẹ hơn, phù hợp hơn với mục tiêu chạy local.
3. Triển khai Gemma 4 12B: từ LiteRT-LM đến local serving
Kiến trúc unified và encoder-free không chỉ làm mô hình gọn hơn về mặt kỹ thuật — nó còn định hướng rõ mục tiêu triển khai. Gemma 4 12B không được thiết kế cho cloud hay GPU server lớn. Thay vào đó, Google nhắm thẳng vào các kịch bản chạy local: laptop, desktop, hoặc workstation cá nhân — những thiết bị mà phần lớn developer thực sự đang dùng hàng ngày.
3.1. LiteRT-LM: runtime cho on-device và desktop AI
- LiteRT-LM là runtime trong hệ sinh thái Google AI Edge, cho phép chạy LLM trực tiếp trên thiết bị mà không cần gọi API cloud. Với Gemma 4 12B, nó là lớp triển khai chính cho các kịch bản local.
- Gemma 4 12B được định vị đủ nhỏ để chạy trên laptop khoảng 16GB VRAM, trong khi hiệu năng trên một số benchmark vẫn tiệm cận Gemma 4 26B MoE. Memory footprint thấp hơn đáng kể khiến nó phù hợp cho trợ lý AI local, coding assistant, phân tích tài liệu hay workflow agentic chạy trên máy cá nhân.
3.2. Định dạng .litertlm và cách chạy local
-
Để phục vụ triển khai với LiteRT-LM, Gemma 4 12B có bản được đóng gói dưới định dạng
.litertlm. Đây là định dạng giúp việc import, quản lý và chạy mô hình trên máy local trở nên thuận tiện hơn so với việc tự xử lý checkpoint thủ công. -
Một quy trình triển khai cơ bản có thể hiểu như sau:
- Tải hoặc import mô hình Gemma 4 12B ở định dạng LiteRT-LM.
- Đăng ký mô hình vào LiteRT-LM CLI (Source).
- Khởi chạy local server bằng lệnh:
# Cài đặt thư viện với pip pip install litert-lm-api # Start the OpenAI-compatible server litert-lm import --from-huggingface-repo=litert-community/gemma-4-12B-it-litert-lm gemma-4-12B-it.litertlm gemma4-12b litert-lm serve- Kết nối ứng dụng bên ngoài vào endpoint local.
Ví dụ, mô hình có thể được import từ Hugging Face repo litert-community/gemma-4-12B-it-litert-lm, sau đó chạy bằng LiteRT-LM trên máy local. Cách làm này giúp developer nhanh chóng thử nghiệm mô hình mà không cần tự xây dựng toàn bộ inference pipeline từ đầu.
3.3. Local endpoint cho agentic workflow
- Một điểm rất thực tế của LiteRT-LM là khả năng biến máy cá nhân thành một local LLM server. Khi server chạy, các ứng dụng bên ngoài có thể gọi mô hình thông qua endpoint local, tương tự cách gọi một API model thông thường.
- Luồng triển khai có thể hình dung như sau:
- Gemma 4 12B chạy trực tiếp trên máy cá nhân.
- LiteRT-LM đóng vai trò runtime và local server.
- Ứng dụng bên ngoài như IDE, coding assistant hoặc agent framework gọi mô hình qua API local.
- Dữ liệu đầu vào được xử lý ngay trên thiết bị, hạn chế phụ thuộc vào cloud.
from openai import OpenAI
# Kết nối tới endpoint local port
client = OpenAI(
base_url="http://localhost:8080/v1",
api_key="EMPTY",
)
response = client.chat.completions.create(
model="gemma-4-12b",
messages=[
{
"role": "user",
"content": "Summarize this document in Vietnamese.",
}
],
max_tokens=4096,
temperature=0.7,
)
print(response.choices[0].message.content)
Cách triển khai này đặc biệt phù hợp với các workflow agentic, nơi mô hình cần tương tác nhiều lần với file, code, terminal hoặc dữ liệu cá nhân. Thay vì gửi dữ liệu lên server bên ngoài, toàn bộ quá trình có thể được thực hiện trong môi trường local, giúp tăng tính riêng tư và giảm độ trễ trong các tác vụ lặp lại.
3.4.Triển khai với vLLM
- Bên cạnh LiteRT-LM, một hướng triển khai khác đáng cân nhắc là vLLM. Nếu LiteRT-LM phù hợp hơn với on-device và desktop local serving, thì vLLM lại mạnh ở các kịch bản phục vụ mô hình trên GPU, workstation hoặc server nội bộ.
- Tuy nhiên, Gemma 4 12B là biến thể encoder-free mới, cần sử dụng bản vllm nightly. Câu lệnh chạy như sau:
# Hỗ trợ tất cả các dạng input
vllm serve google/gemma-4-12B-it \
--max-model-len 16384 \
--gpu-memory-utilization 0.90 \
--enable-auto-tool-choice \
--reasoning-parser gemma4 \
--tool-call-parser gemma4 \
--chat-template examples/tool_chat_template_gemma4.jinja \
--limit-mm-per-prompt '{"image": 4, "audio": 1}' \
--async-scheduling \
--host 0.0.0.0 \
--port 8000
# Client Usage:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
response = client.chat.completions.create(
model="google/gemma-4-12B-it",
messages=[{"role": "user", "content": "Write a poem about the ocean."}],
max_tokens=512, temperature=0.7,
)
print(response.choices[0].message.content)
Do đó, trong bài viết này, vLLM nên được xem như một hướng triển khai mở rộng cho môi trường GPU/server (tham khảo thêm tại đây), còn LiteRT-LM vẫn là trọng tâm khi nói về on-device và desktop local deployment.
Kết luận
- Ưu điểm: Gemma 4 12B Unified có kiến trúc gọn hơn nhờ loại bỏ vision/audio encoder riêng, đưa text, image và audio về cùng không gian embedding để xử lý trong một decoder-only Transformer.
- Hạn chế: Dù tối ưu hơn cho local deployment, mô hình vẫn có quy mô 12B tham số nên cần tài nguyên phần cứng tương đối tốt; khả năng multimodal thực tế còn phụ thuộc vào runtime triển khai như LiteRT-LM hoặc vLLM.
- Tổng kết: Gemma 4 12B không đơn giản là bản nằm giữa E4B và 26B MoE. Nó là một hướng thiết kế khác: unified, encoder-free, nhắm vào các tác vụ AI chạy trực tiếp trên máy cá nhân.
💡 Tài liệu tham khảo:
- https://developers.googleblog.com/gemma-4-12b-the-developer-guide/
- https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-gemma-4-12b
- https://developers.googleblog.com/bringing-gemma-4-12b-to-your-laptop-unlocking-local-agentic-workflows-with-google-ai-edge/
- https://huggingface.co/litert-community/gemma-4-12B-it-litert-lm
All rights reserved
