FGSM-Fast Gradient Sign Method : Adversarial Examples
Bài đăng này đã không được cập nhật trong 2 năm
Fast Gradient Sign Method
Khi dấn thân vào tìm hiểu Adversarial Attack, có thể bạn sẽ gặp những thuật ngữ như White-box attack và Black-box attack. Mình cũng vậy, và thuật toán đầu tiên mình được tiếp cận đến White-box Attack chính là Fast Gradient Sign Method (FGSM).
1. Bản chất
- FGSM bản chất là việc thực hiện tạo một pertubation (nhiễu) ví dụ như hình dưới, nhiễu này được thêm vào ảnh gốc nhằm khiến cho việc dự đoán của model bị sai lệch, dẫn đến outcome khác đi theo ý của thuật toán tấn công.
- Mục đích của thuật toán này là sao cho nhiễu hòa trộn cùng ảnh gốc để mắt người không thể nhận biết được sự khác biệt nhưng lại hoàn toàn phá hủy việc training model.
2. Algorithm
- Có lẽ bạn đã nhìn thấy ví dụ này nhiều lần, đây là ví dụ điển hình khi dùng thuật toán FGSM khiến model nhận diện gấu trúc thành con vượn (gibbon) với 99.3% confidence score.
- FGSM được tạo ra bằng cách: tạo ra một ảnh mới từ ảnh ban đầu cộng thêm hyper-parameter(epsilon) nhân với đạo hàm theo input image của hàm loss của model. Có thể khó hiểu, bạn theo dõi công thức sau đây:
 Ảnh từ: https://arxiv.org/abs/1412.6572
Ảnh từ: https://arxiv.org/abs/1412.6572 - adv_x chính là ảnh adversary được dùng để đánh lừa model, x là input image, e là epsilon, siêu tham số(hyper-parameter) được dùng để điều chỉnh cường độ của nhiễu (magnitude of perturbations), epsilon càng lớn thì nhiễu càng rõ, ảnh càng khác ảnh ban đầu và confident score của false label càng cao. Còn
Là phần đạo hàm của hàm loss theo x( theo input image). Có thể bạn còn nhớ với Gradient descent, ta đạo hàm hàm loss J theo tham số theta và cập nhật theta(weights). Nhưng với FGSM, chúng ta đạo hàm J theo x, và cập nhật trực tiếp x để có ảnh mới.
- Cuối cùng, sau khi lấy được đạo hàm, ta áp dụng thêm hàm sign() vào đạo hàm vừa tìm được. Tức nếu đạo hàm nhỏ hơn 0, epsilon sẽ nhân với -1, lớn hơn 0, epsilon nhân với 1, bằng 0 thì epsilon nhân với 0 (trường hợp bằng 0 chính là input image ban đầu chưa thêm nhiễu)
=> Sau khi tìm hiểu từng phần của công thức, bạn sẽ hiểu được tại sao lại có tên gọi Fast Gradient Sign Method : Fast vì nó nhanh  , Gradient chính là đạo hàm, Sign chính là hàm lấy dấu.
, Gradient chính là đạo hàm, Sign chính là hàm lấy dấu.
Chú ý: Bạn có thể thấy thêm công thức này trong paper Adversarial Examples in the Physical World
Tương tự như vậy, ta có X là input image, và các tham số, nhưng có thể bạn nhận ra điều khác biệt, khi biến của đạo hàm J theo X là y_true, tức truth label (ground truth) của bức ảnh. Nhưng khi code, bạn lại thấy ta dùng y_target, tức label mà ta muốn model dự đoán nhầm thành. Cả hai công thức đều đúng, nhưng lại có cách dùng khác nhau dựa trên 2 loại adversarial examples như sau:
- Targeted Attack: Tấn công có chủ đích, tức ta muốn model dự đoán sai trở thành label mà ta muốn, ví dụ bạn set target_label = con chuột thì dù hình ảnh là con voi thì model cũng sẽ ra label là con chuột, với một confident score nào đó. Cách tấn công này nguy hiểm hơn vì kẻ ác có thể khiến hệ thống xe lái tự động nhầm biển báo dừng thành tăng tốc chẳng hạn. => Nếu bạn muốn thuật toán của mình là targeted attack, tham số y của thành phần loss của bạn phải là target_label, label mà bạn muốn model nhầm thành.
- Untargeted Attack: Đối ngược với targeted_attack, untargeted attack chỉ với một mục đích khiến model phân loại nhầm, chứ không quan tâm sẽ phân loại nhầm thành cái gì. Trong trường hợp này, hàm loss của bạn sẽ được khởi tạo bằng y_true.
3. Code FGSM- Tensorflow
- Đến phần thú vị nhất rồi đây, mình sẽ dùng MobileNet pre-trained model cho phần code này. Mình tham khảo bài code từ Web TensorFlow
import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
Nhập pre-trained model nè. decode_predictions chính là để lấy phần label mà con người có thể đọc hiểu được (file label có 3 phần bạn có thể tìm hiểu thêm).
pretrained_model = tf.keras.applications.MobileNetV2(include_top=True,
weights='imagenet')
pretrained_model.trainable = False
# ImageNet labels
decode_predictions = tf.keras.applications.mobilenet_v2.decode_predictions
Viết hàm xử lý ảnh, phần này rất quan trọng vì xử lý khác đi là kết quả predict cũng khác ;<, mình cũng khá loay hoay ở phần này
def preprocess(image):
# chuyển giá trị pixel ảnh về float32 bằng tf.cast
image = tf.cast(image, tf.float32)
#input image của MobileNet là (224,224) nên ta resize lại nè
image = tf.image.resize(image, (224, 224))
# bước tiền xử lý ảnh để được pixel values về giá trị thích hợp với model
image = tf.keras.applications.mobilenet_v2.preprocess_input(image)
# Dòng này mở rộng thêm 1 chiều cho ảnh(vì các ảnh trong model đều được train theo batch, 1 ảnh nghĩa là batch_size =1
image = image[None, ...]
return image
# Helper function to extract labels from probability vector
def get_imagenet_label(probs):
return decode_predictions(probs, top=1)[0][0]
Tiếp tục xử lý ảnh...
image_path = 'your_image_path.jpg'
image_raw = tf.io.read_file(image_path)
image = tf.image.decode_image(image_raw)
image = preprocess(image)
image_probs = pretrained_model.predict(image)
Xem kết quả nè:
plt.figure()
plt.imshow(image[0] * 0.5 + 0.5) # To change [-1, 1] to [0,1]
_, image_class, class_confidence = get_imagenet_label(image_probs)
plt.title('{} : {:.2f}% Confidence'.format(image_class, class_confidence*100))
plt.show()
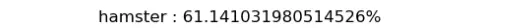
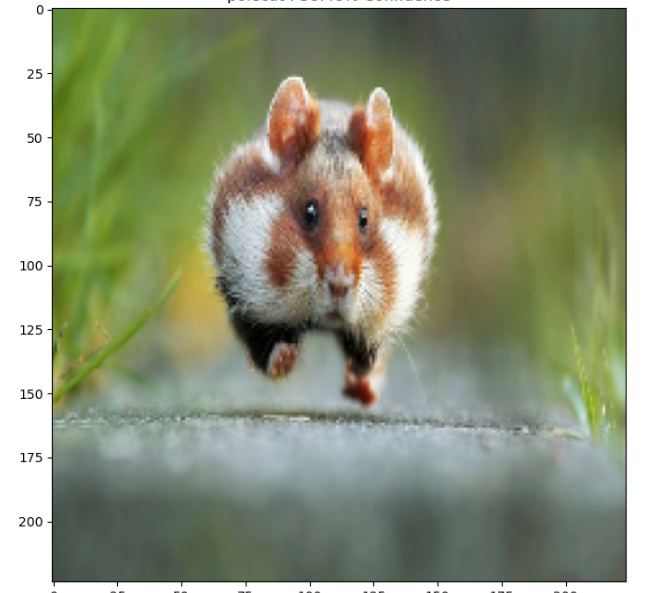 Model của mình đoán được Hamster 61% Confident! Cũng được ha.
Model của mình đoán được Hamster 61% Confident! Cũng được ha.
- Sau đó thì chúng mình viết hàm tạo pertubation theo phương pháp FGSM:
loss_object = tf.keras.losses.CategoricalCrossentropy()
def create_adversarial_pattern(input_image, input_label):
with tf.GradientTape() as tape:
tape.watch(input_image)
prediction = pretrained_model(input_image)
# hàm loss có 2 tham số nè
loss = loss_object(input_label, prediction)
#tính đạo hàm nè
gradient = tape.gradient(loss, input_image)
# Get the sign of the gradients to create the perturbation
signed_grad = tf.sign(gradient)
return signed_grad
Sau đây mình sẽ đi chọn xem model của mình sẽ dự đoán nhầm thành con gì nha. Bộ label của MobileNet có 1000 label, vậy nên bạn sẽ chọn 1 index từ 0 đến 999 để chọn lấy 1 label. Ví dụ mình chọn 2, nghĩa là chỉ số của label wombat - con gấu túi mũi trần! Sau khi in perturbations, ta sẽ được 1 ảnh nhiễu như lúc đầu bạn nhìn thấy.
target_label = 2
label = tf.one_hot(labrador_retriever_index, image_probs.shape[-1])
label = tf.reshape(label, (1, image_probs.shape[-1]))
perturbations = create_adversarial_pattern(image, label)
plt.figure(figsize=(4,4))
plt.imshow(perturbations[0] * 0.5 + 0.5); # To change [-1, 1] to [0,1]
Cuối cùnggg, ta lựa chọn nhiều epsilons để xem ảnh và confident score thay đổi như nào, cùng với xem cái độ đo như PSNR, L1, L2 thay đổi như nào. Mình sẽ có 1 bài tìm hiểu về độ đo nha!
epsilons = [0,0.001, 0.01, 0.1, 0.15,0.3]
descriptions = [('Epsilon = {:0.3f}'.format(eps) if eps else 'Input')
for eps in epsilons]
for i, eps in enumerate(epsilons):
adv_x = image + eps*perturbations
adv_x = tf.clip_by_value(adv_x, -1, 1)
image_gray = color.rgb2gray(image)
adv_gray = color.rgb2gray(adv_x)
mse = np.mean((image_gray - adv_gray)**2)
psnr = 10* np.log10((255**2)/mse)
print("PSNR:{:.2f} ".format(psnr))
L1 = 1/(tf.size(image).numpy())*np.sum(abs(image-adv_x))
L2 = 1/(tf.size(image).numpy())*np.sum((image-adv_x)**2)
print("L1 loss:{:.2f}".format(L1))
print("L2 loss:{:.2f}".format(L2))
display_images(adv_x, descriptions[i])
Thử chạy code và điều chỉnh nhiều kiểu khác nhau để hiểu hơn. Mình vừa học vừa ghi chú lại những gì mình lĩnh hội được, có thể còn nhiều thiếu xót rất rất rất mong mọi người nói cho mình để mình biết được nhiều hơn.
4. Tài liệu mình đã tham khảo
- Paper: https://arxiv.org/abs/1607.02533, https://arxiv.org/abs/1412.6572
- Code: https://www.tensorflow.org/tutorials/generative/adversarial_fgsm Nếu bạn có thêm tài liệu hay về phần này, hãy chia sẽ với mình nhe.
All rights reserved
