🗄️🧠 Execution Plan (EXPLAIN): Cách Đọc Query Plan Để Biết Query Có Dùng Index Hay Không - Database System Design P6
Execution Plan (EXPLAIN): Chiếc Kính Hiển Vi Của Kỹ Sư Backend Trong Thế Giới Dữ Liệu
1. Mở đầu: Câu chuyện từ "Hiện trường" Production
Hãy tưởng tượng một kịch bản "ác mộng" vào tối thứ Sáu: Hệ thống E-commerce của bạn vừa khởi động chiến dịch Mega Sale. Traffic tăng vọt, và đột nhiên dashboard monitoring chuyển sang màu đỏ rực—CPU Database chạm ngưỡng 100%.
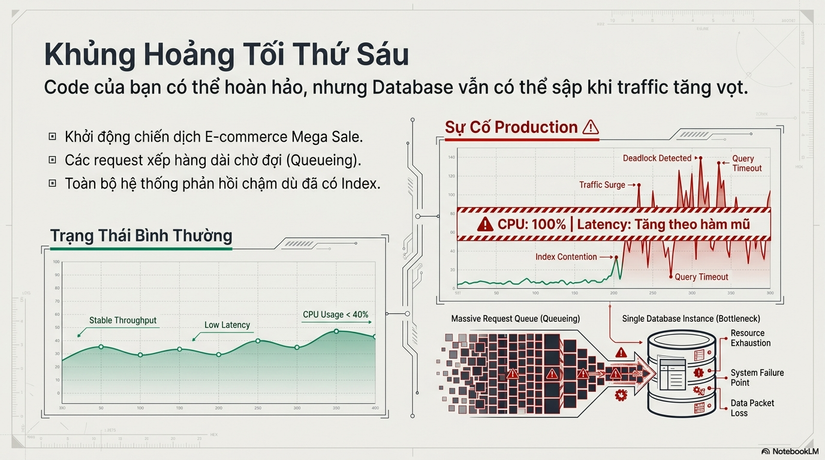
Một Junior Engineer nhanh chóng kiểm tra code và khẳng định: "Query tìm kiếm đơn hàng này không thể chậm được, em đã chạy CREATE INDEX trên cột customer_id từ tuần trước rồi!". Nhưng thực tế là các request vẫn đang xếp hàng chờ (queueing), và latency tăng theo hàm mũ.
Trong thế giới của TechCraft, sự khác biệt giữa một người viết code và một Senior Backend Engineer nằm ở điểm này: Người Junior tin vào những gì mình nghĩ (Index đã có), còn người Senior tin vào những gì Database làm. Thay vì vội vàng thêm bừa bãi các Index mới—một hành động thường chỉ làm trầm trọng thêm vấn đề—chúng ta cần một công cụ để soi rọi vào "hộp đen" của dữ liệu. Đó chính là Execution Plan.
Execution Plan không chỉ là một bảng thông số; nó là chiếc kính hiển vi giúp kỹ sư quan sát lộ trình thực tế mà dữ liệu đi qua, vạch trần những góc khuất nơi Optimizer (Bộ tối ưu hóa) đang đưa ra những quyết định sai lầm.
2. Phá vỡ lầm tưởng: "Chỉ cần có Index là Query sẽ nhanh"
Để tư duy như một kiến trúc sư dữ liệu, chúng ta cần gạt bỏ 3 lầm tưởng phổ biến thường bóp nghẹt hiệu năng hệ thống:
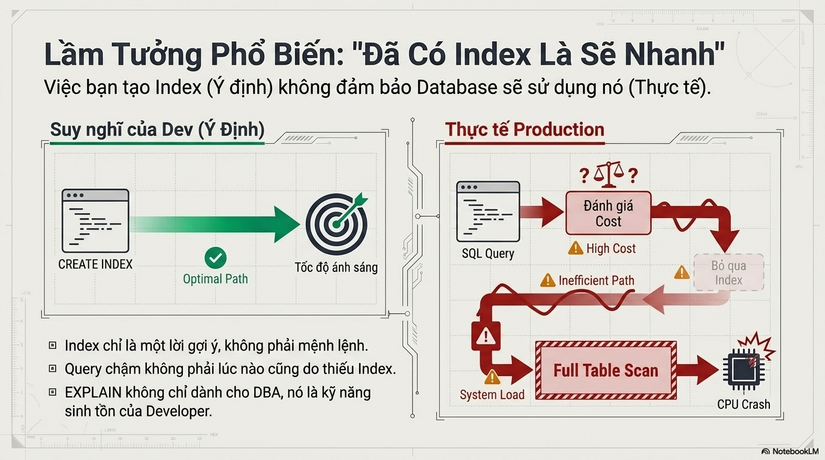
- EXPLAIN là công việc của DBA, không phải của Developer: Sai. Developer là người tạo ra Query Pattern và nắm giữ Business Context. Việc không biết đọc Query Plan giống như một bác sĩ kê đơn mà từ chối nhìn vào phim X-quang.
- Database luôn chọn con đường nhanh nhất: Database thực tế sử dụng một bộ óc gọi là Cost-Based Optimizer (CBO). Nó chọn con đường mà nó ước tính là rẻ nhất dựa trên số liệu thống kê (statistics). Nếu statistics bị cũ hoặc sai lệch, Optimizer sẽ dắt bạn đi vào ngõ cụt.
- Có Index là Database sẽ tự động dùng: Đây là niềm tin ngây thơ nhất. Database có quyền "từ chối" Index nếu chi phí sử dụng Index đó cao hơn việc quét toàn bộ bảng. Index là một gợi ý, không phải một mệnh lệnh.
Tại TechCraft, chúng tôi dạy bạn: Đừng đoán, hãy quan sát. Mọi giả định về hiệu năng đều vô nghĩa cho đến khi được chứng minh qua Execution Plan.
3. Tại sao chúng ta cần Execution Plan? (The "Why" before "What")
Tại sao cùng một câu lệnh SELECT, Database lại có thể có hàng chục cách "lấy hàng" khác nhau?
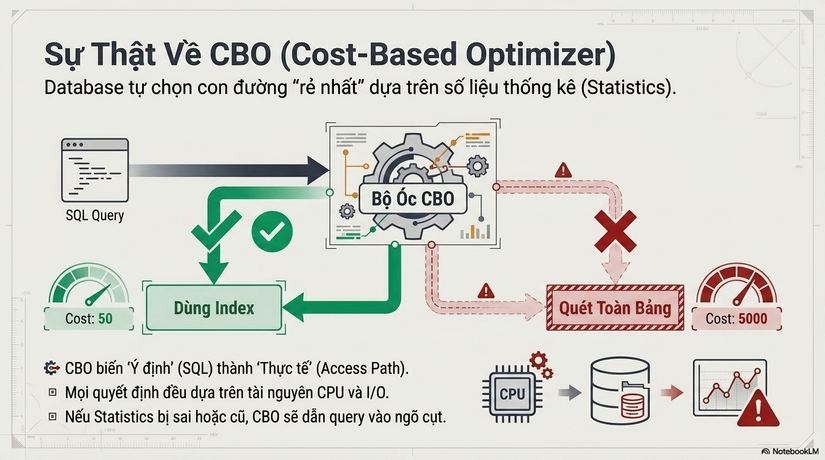
Bản chất của Database hiện đại là một thực thể thông minh. Khi nhận một câu SQL (Intent - Ý định của bạn), nó sẽ chuyển hóa thành các Access Path (Reality - Thực thi thực tế). CBO sẽ tính toán chi phí (Cost) cho mỗi Access Path dựa trên tài nguyên CPU và I/O.
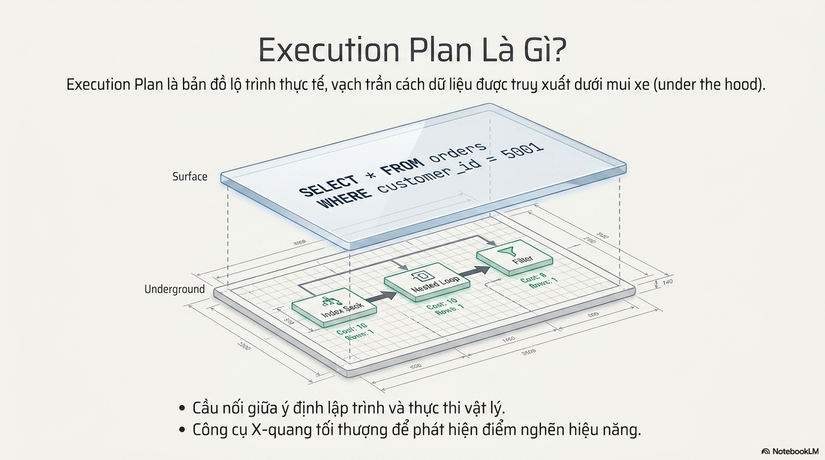
Execution Plan chính là chiếc cầu nối giữa ý định của lập trình viên và thực tế của Database. Nó tiết lộ cách hệ thống giải quyết bài toán truy cập dữ liệu: Nó sẽ nhảy vào cây Index để tìm ngay vị trí (Seek), hay nó sẽ ngậm ngùi quét qua hàng triệu bản ghi (Scan)? Hiệu năng thực sự không nằm ở cú pháp SQL đẹp đẽ, mà nằm ở tính hiệu quả của lộ trình này.
4. Giải mã Execution Plan: Đọc hiểu "Bản đồ" dữ liệu
Khi thực thi lệnh EXPLAIN (hoặc EXPLAIN ANALYZE), bạn sẽ đối mặt với một "bản đồ" dữ liệu. Đừng để những con số làm bạn bối rối, hãy tập trung vào 3 trọng điểm sau:
4.1. Scan Type (Phương thức truy cập)
Đây là thước đo đầu tiên về hiệu năng I/O.
| Loại Scan | Bản chất kỹ thuật | Chi phí (Cost) | Đánh giá |
|---|---|---|---|
| Full Table Scan (ALL) | Đọc mọi block dữ liệu của bảng từ ổ đĩa. | Cực cao | Thảm họa khi bảng lớn. |
| Index Scan | Quét toàn bộ các node của cây Index. | Trung bình | Tốt, nhưng vẫn là quét diện rộng. |
| Index Seek / Range Scan | Nhảy trực tiếp đến vị trí hoặc vùng dữ liệu qua Index. | Thấp | Gold Standard - Mục tiêu của tối ưu hóa. |
4.2. Join Strategy (Chiến lược kết hợp)
Cách Database kết hợp các bảng là nơi "đốt" CPU nhiều nhất.
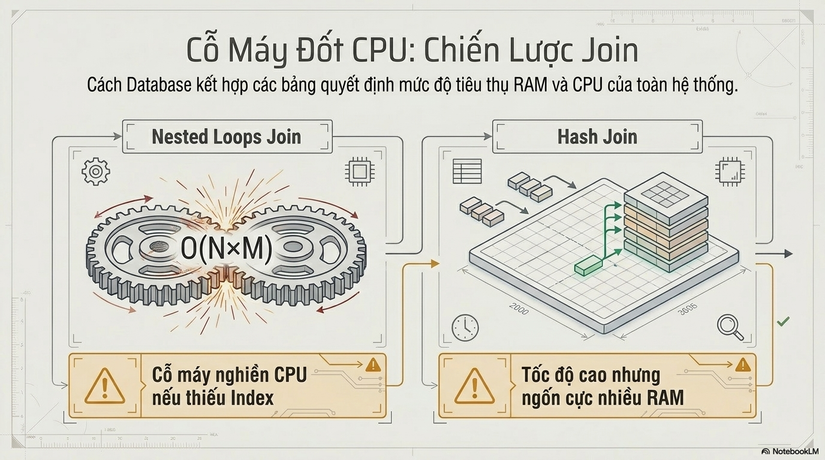
- Nested Loops Join: Database lấy từng dòng bảng A để tìm trong bảng B. Chi phí là O(N×M). Nếu bảng B không có Index trên cột Join, đây là một "cỗ máy nghiền" CPU thực sự.
- Hash Join: Thường dùng cho các bảng lớn không có Index phù hợp. Database xây dựng một Hash Table trong bộ nhớ. Nó nhanh hơn Nested Loops trên dữ liệu lớn nhưng cực kỳ tốn RAM.
4.3. Rows & Cost: Chiếc la bàn, không phải GPS
- Rows: Số lượng dòng dự kiến xử lý.
- Cost: Đơn vị đo lường trừu tượng của Optimizer.

Tư duy Senior: Hãy coi những con số này là một chiếc la bàn chỉ hướng, đừng coi nó là GPS chính xác từng mét. Chúng chỉ đáng tin khi statistics của Database được cập nhật thường xuyên. Nếu bạn thấy Rows ước tính là 10 nhưng thực tế trả về 1 triệu dòng, đó là dấu hiệu statistics đã hỏng.
4.4. Ví dụ thực tế
Giả sử bạn chạy Query tìm đơn hàng của khách hàng 5001:
EXPLAIN SELECT * FROM orders WHERE customer_id = 5001;
Kết quả trả về:
-> Index lookup on orders using idx_customer_id (customer_id=5001)
(cost=1.20 rows=5)
Ở đây, Index lookup cho thấy Database đang dùng Index Seek. Cost cực thấp (1.20) và chỉ phải xử lý 5 dòng. Đây là một plan lành mạnh. Nếu bạn thấy type: ALL thay vì lookup, dù Index đã tồn tại, đó là lúc "kính hiển vi" bắt đầu phát hiện bất thường.
5. Khi "Kính hiển vi" phát hiện bất thường: Tại sao Index có nhưng không dùng?
Trong production, có những tình huống trớ trêu khiến "đường tắt" Index bị bỏ qua. EXPLAIN sẽ giúp bạn vạch trần những sai lầm này:

- Lệch kiểu dữ liệu (Implicit Casting): Bạn truyền chuỗi
'12345'vào cột kiểuBIGINT. Để so sánh, Database buộc phải chạy một hàm ép kiểu ngầm định trên từng dòng của bảng. Hệ quả: Index bị vô hiệu hóa hoàn toàn, quay về Full Table Scan. - Độ chọn lọc thấp (Low Selectivity): Bạn có Index trên cột
trạng_thái(chỉ có 2 giá trị). Nếu Query của bạn lấy ra 30% dữ liệu của bảng, Optimizer sẽ tính toán: "Việc đọc Index rồi nhảy vào ổ đĩa lấy dữ liệu (Random I/O) còn đắt hơn việc quét một mạch cả bảng (Sequential I/O)". Nó sẽ chọn quét toàn bảng. - Hàm số trên cột (SARGability):
WHERE YEAR(created_at) = 2024. Database không thể dùng Index trêncreated_atvì nó phải tính toán giá trịYEAR()cho mọi dòng trước khi so sánh.
Engineering Thinking: Đừng bao giờ release một Query quan trọng mà chưa kiểm tra "giả định" của mình bằng EXPLAIN.
6. Tư duy Senior: Đánh đổi (Trade-offs) và Ra quyết định
Một Senior Engineer không tối ưu hóa trong chân không. Mọi quyết định về Index và Query Plan đều là một sự đánh đổi:
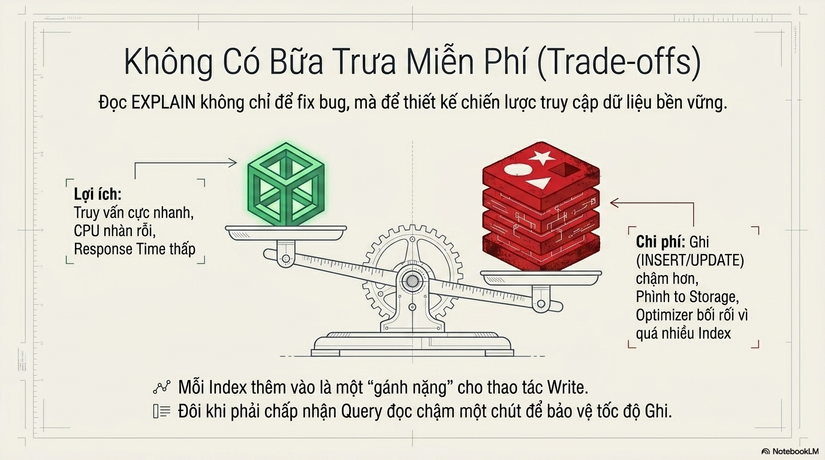
- Lợi ích: Truy vấn nhanh, bảo vệ CPU/IO, hệ thống phản hồi tức thì.
- Chi phí: Mỗi Index thêm vào là một gánh nặng cho thao tác Write. Mỗi khi
INSERT/UPDATE, Database phải bảo trì thêm một cây B-Tree. Index càng nhiều, Write càng chậm và dung lượng lưu trữ càng phình to. - Rủi ro: Quá nhiều Index có thể khiến Optimizer bị "bối rối" (Planner Overhead) và đôi khi chọn sai Plan do có quá nhiều lựa chọn tương đồng.
Đọc EXPLAIN không chỉ để "fix" một câu lệnh chậm. Nó là để thiết kế một Chiến lược truy cập dữ liệu bền vững: Khi nào cần Index, khi nào cần Denormalization, và khi nào chấp nhận để Query chậm một chút nhằm bảo vệ tốc độ Ghi của hệ thống.
7. Tổng kết và Bài học từ TechCraft
Làm chủ Database System Design là hành trình đi từ bóng tối của sự đoán mò ra ánh sáng của sự quan sát có phương pháp. 3 giá trị cốt lõi bạn cần nhớ:
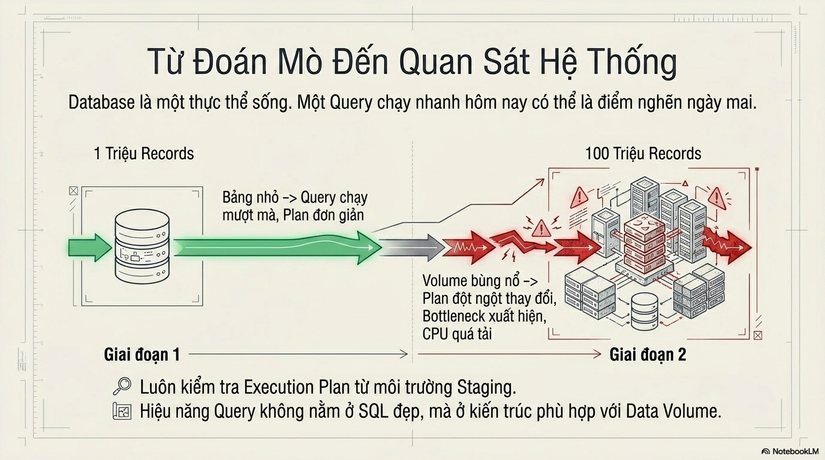
- Ngừng đoán, hãy quan sát: EXPLAIN là kỹ năng sinh tồn, không phải tùy chọn. Hãy hình thành thói quen kiểm tra Query Plan ngay từ môi trường Staging.
- Database là một hệ thống sống: Dữ liệu lớn lên, Plan sẽ thay đổi. Một Query chạy nhanh hôm nay có thể trở thành điểm nghẽn ngày mai khi volume tăng từ 1 triệu lên 100 triệu bản ghi.
- Tư duy hệ thống: Hiệu năng Query chỉ là một mặt của đồng xu. Mặt còn lại là tính đúng đắn và khả năng chịu tải.
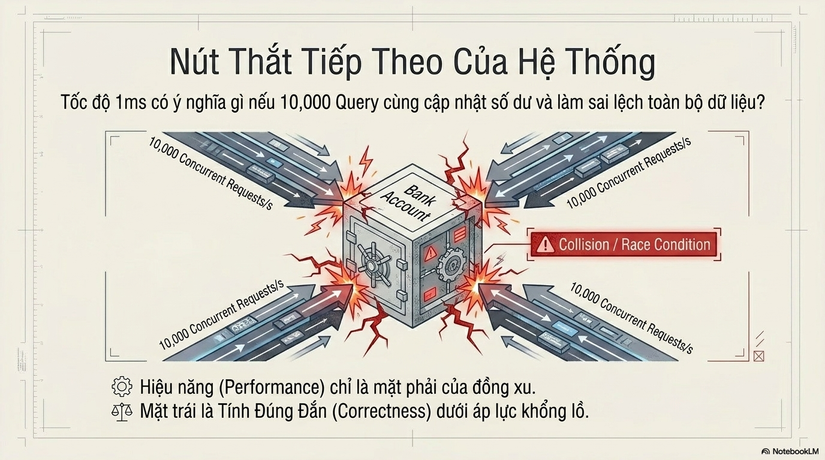
Mở nút thắt cho phần tiếp theo: Chúng ta đã biết cách khiến một Query chạy trong 1ms. Nhưng chuyện gì xảy ra nếu 10,000 Query đó cùng muốn cập nhật số dư của một tài khoản ngân hàng tại cùng một thời điểm? Tốc độ có còn ý nghĩa gì nếu dữ liệu cuối cùng bị sai lệch?

Chúng ta sẽ cùng giải mã bài toán sống còn này tại Episode 07: Transaction & ACID - Vì sao Database gần như không bao giờ lưu sai dữ liệu?
Kết nối cùng TechCraft
Bài viết này là một mảnh ghép trong lộ trình nâng tầm từ một Developer biết dùng database thành một Engineer biết thiết kế tầng dữ liệu. Tại TechCraft, chúng tôi tin rằng Database không chỉ là nơi lưu trữ, nó là "hệ thống hợp đồng" (System Contract) giữ cho toàn bộ kiến trúc của bạn đứng vững dưới áp lực production.
🚀 Tiếp tục hành trình cùng TechCraft
Nếu bài viết này mang lại cho bạn một góc nhìn mới, thì đây mới chỉ là một phần trong hành trình khám phá Backend Engineering, System Design và Production Systems tại TechCraft.
Ngoài các nội dung miễn phí, TechCraft còn phát triển Dev Insider — chương trình học chuyên sâu dành cho những Developer muốn hiểu hệ thống từ bên trong, thay vì chỉ biết cách sử dụng chúng.
Hiện Dev Insider đang phát triển các series như:
- 🔒 Backend Internals
- 🔒 Database Internals
- 🔒 Database World Case Studies
- 🔒 Interview
- ... và nhiều series mới được cập nhật mỗi tuần.
🚀 Dev Insider
https://www.patreon.com/techcraft_official/posts/vi-sao-dev-ra-161163881?collection=2220113
📘 Facebook
https://www.facebook.com/techcraft.official
🎥 YouTube
https://www.youtube.com/@techcraft.official
🎵 TikTok
https://www.tiktok.com/@techcraft.official
Không chỉ học cách build. Học cách build đúng.
All rights reserved
