Embedding Model – Chuyển văn bản thành vector bằng Sentence-Transformers
Trong các hệ thống AI hiện đại, đặc biệt là AI Agent, RAG hay công cụ phân tích ngữ nghĩa, Embedding Model là tầng xử lý cốt lõi giúp “dịch” dữ liệu thô thành dạng vector số học mà máy có thể thao tác. Nhờ cơ chế này, mô hình có thể đo tương đồng, so khớp ngữ nghĩa và trích xuất thông tin nhanh theo thời gian thực.
Embedding là gì
Vấn đề
Máy tính chỉ nhìn thấy chuỗi ký tự, không hiểu được ý nghĩa hay ngữ cảnh. Hai câu:
- “Tôi thích học AI”
- “Tôi yêu trí tuệ nhân tạo”
…về mặt string hoàn toàn khác nhau, nhưng về mặt ngữ nghĩa thì gần như tương đương. Nếu không có cách biểu diễn thống nhất, mô hình không thể xác định mức độ liên quan giữa các câu.
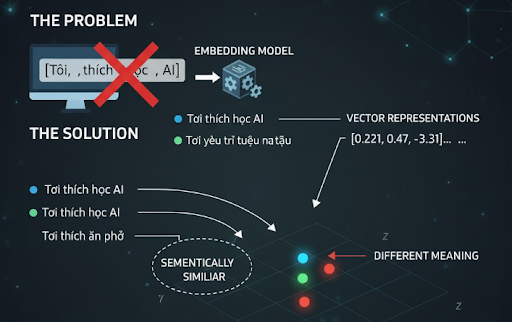
Giải pháp của Embedding
Embedding Model chuyển mỗi câu thành một vector thực nhiều chiều. Các câu mang nghĩa gần nhau sẽ nằm gần nhau trong không gian vector:
| Câu | Vector (rút gọn) |
|---|---|
| Tôi thích học AI | [0.21, 0.45, -0.32, …] |
| Tôi yêu trí tuệ nhân tạo | [0.22, 0.47, -0.31, …] |
| Tôi thích ăn phở | [-0.88, 0.13, 0.75, …] |
→ Hai câu đầu nằm gần nhau → tương đồng ngữ nghĩa → Câu “ăn phở” lệch hẳn → khác nội dung
Embedding Model vận hành như thế nào?
Các mô hình phổ biến như BERT, MPNet, T5, GPT… hoạt động theo pipeline đơn giản:
- Nhận input: câu, đoạn văn, hình ảnh…
- Tokenization: tách dữ liệu thành token.
- Embedding Layer: mỗi token được ánh xạ thành vector.
- Tính toán positional + attention: mô hình “học” quan hệ ngữ nghĩa.
- Xuất vector cuối: đại diện cho câu hoặc đoạn văn.
Vector cuối cùng này là cơ sở cho semantic search, RAG, clustering, recommendation,…
Tạo embedding bằng thư viện Sentence-Transformers
Dưới đây là phần quan trọng nhất dành cho dev: cách triển khai thực tế.
Cài đặt
pip install sentence-transformers
Khởi tạo mô hình
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
all-MiniLM-L6-v2 → vector 384 chiều, tốc độ nhanh, phù hợp môi trường sản phẩm.
Encode câu thành vector
sentences = [
"Bizfly Chatbot giúp doanh nghiệp tự động hóa CSKH",
"Bizfly CRM quản lý dữ liệu và khách hàng hiệu quả"
]
embeddings = model.encode(sentences)
print(embeddings.shape)
Output: (2, 384) → tức là 2 câu, mỗi câu thành vector 384 chiều.
Xem giá trị vector
print(embeddings[0][:10])
Đo độ tương đồng bằng Cosine Similarity
from sklearn.metrics.pairwise import cosine_similarity
score = cosine_similarity([embeddings[0]], [embeddings[1]])[0][0]
print("Similarity:", round(score, 3))
Model đa ngôn ngữ (phù hợp tiếng Việt)
model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
Ứng dụng thực tế của Embedding trong hệ thống AI
| Bài toán | Vai trò của Embedding |
|---|---|
| Semantic Search | So sánh vector truy vấn + tài liệu |
| Chatbot AI (RAG) | Tìm đoạn nội dung liên quan trước khi gửi cho LLM |
| Recommendation engine | Tìm sản phẩm có vector gần với vector hành vi người dùng |
| Clustering | Gom nhóm văn bản bằng KMeans trên vector |
| Sentiment Analysis | Vector hóa câu → input cho classifier |
Tích hợp Embedding vào RAG Pipeline
Một hệ thống RAG điển hình gồm:
-
Chuẩn hóa dữ liệu → chunking nội dung
-
Sinh embedding cho từng chunk
-
Lưu vector vào vector DB (FAISS, ChromaDB, Pinecone…)
-
Khi có truy vấn:
- Encode câu hỏi
- Tìm top-k vector gần nhất
- Gửi + context vào LLM để tạo câu trả lời chính xác
Pseudo-flow:
Query → Encode → Semantic Search → Retrieve top-k → LLM → Output
Tích hợp với LangChain
from langchain.embeddings import HuggingFaceEmbeddings
emb = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
Danh sách các mô hình Embedding phổ biến
| Model | Dim | Ghi chú |
|---|---|---|
| all-MiniLM-L6-v2 | 384 | Nhanh, nhẹ, hiệu quả |
| multi-qa-MiniLM-L6-cos-v1 | 384 | Tối ưu cho QA |
| paraphrase-multilingual-MiniLM-L12-v2 | 384 | Hỗ trợ tiếng Việt |
| sentence-t5-base | 768 | Chất lượng cao |
| e5-large-v2 | 1024 | Chuẩn cho semantic search quy mô lớn |
Kết luận
Embedding Model là nền tảng của hầu hết các hệ thống AI có hiểu ngữ nghĩa hiện nay. Bằng việc chuyển dữ liệu thành vector, developer có thể triển khai các bài toán như semantic search, RAG, phân loại và gợi ý nội dung với độ chính xác cao. Sentence-Transformers là lựa chọn đơn giản, mạnh mẽ và dễ tích hợp trong mọi pipeline.
Nguồn tham khảo: https://bizfly.vn/techblog/huong-dan-tich-hop-chunking-vao-pipeline-huan-luyen-ai.html
All rights reserved
