Elasticsearch - Khái niệm và các câu truy vấn cơ bản
Bài đăng này đã không được cập nhật trong 8 năm
ElasticSearch là gì?
Elasticsearch là công cụ tìm kiếm dựa trên nền tảng Apache Lucene. Nó cung cấp API cho việc lưu trữ và tìm kiếm dữ liệu một cách nhanh chóng. Nó được xây dựng, phát triển bằng ngôn ngữ java dựa trên Lucene – phần mềm tìm kiếm và trả về thông tin (information retrieval software) với hơn 15 năm kinh nghiệm về full text indexing and searching. Elasticsearch được xây dựng để hoạt động như một server cloud theo cơ chế của RESTful. Điều này giúp nó có thể tương tác và sử dụng bới rất nhiều ngôn ngữ , cũng chính do đó cũng là điểm yếu của nó khi độ bảo mật không cao.
Ưu và nhược điểm của ElasticSearch, khi nào nên sử dụng?
- Ưu điểm
- Tìm kiếm dữ liệu rất nhanh chóng, mạnh mẽ dựa trên Apache Lucene. Tìm kiếm trong elasticsearch gần như là realtime hay còn gọi là near-realtime searching
- Có khả năng phân tích dữ liệu (Analysis data)
- Lưu trữ dữ liệu full-text
- Đánh index cho dữ liệu (near-realtime search/indexing, inverted index)
- Hỗ trợ tìm kiếm mờ (fuzzy), tức là từ khóa tìm kiếm có thể bị sai lỗi chính tả hay không đúng cú pháp thì vẫn có khả năng elasticsearch trả về kết quả tốt.
- Hỗ trợ nhiều Elasticsearch client phổ biến như Java, PhP, Javascript, Ruby, .NET, Python
- Nhược điểm
- Elasticsearch được thiết kế cho mục đích search, do vậy với những nhiệm vụ khác ngoài search như CRUD thì elastic kém thế hơn so với những database khác như Mongodb, Mysql …. Do vậy người ta ít khi dùng elasticsearch làm database chính, mà thường kết hợp nó với 1 database khác.
- Trong elasticsearch không có khái niệm database transaction , tức là nó sẽ không đảm bảo được toàn vẹn dữ liệu trong các hoạt động Write, Update, Delete.
- Elasticsearch không cung cấp bất kỳ tính năng nào cho việc xác thực và phân quyền (authentication or authorization) . Điều này làm cho ElasticSearch kém sự bảo mật với các hệ quản trị cơ sở dữ liệu hiện nay.
- Khi nào nên sử dụng ElasticSearch? 1.Tìm kiếm text thông thường – Searching for pure text (textual search). 2.Tìm kiếm text và dữ liệu có cấu trúc – Searching text and structured data (product search by name + properties). 3.Tổng hợp dữ liệu – Data aggregation. 4.Tìm kiếm theo tọa độ – Geo Search. 5.Lưu trữ dữ liệu theo dạng JSON – JSON document storage. 6.Phục vụ cho việc lưu trữ và phân tích dữ liệu lớn.
Ai đang sử dụng Elasticsearch?

Các khái niệm cơ bản
- Cluster: tập hợp các node chứa tất cả các dữ liệu. Mỗi cluster được định danh bằng một unique name. Mỗi cluster có một node chính (master) được lựa chọn tự động và có thể thay thế khi gặp sự cố.
- Node: nơi lưu trữ dữ liệu, tham gia vào việc đánh chỉ mục của cluster cũng như thực hiện việc tìm kiếm. Mỗi node được định danh bằng một unique name.
- Index: Là một tập hợp các document.
- Shard: Tập con các document của một index. Một index có thể có nhiều shard. Có hay loại shard được sử dụng là Primary Shard và Replica Shard.
- Document: một JSON object với một số dữ liệu. Đây là đơn vị dữ liệu cơ bản trong Elasticsearch.
Đối chiếu các khái niệm lưu trữ của Elasticsearch với một hệ quản trị cơ sở dữ liệu
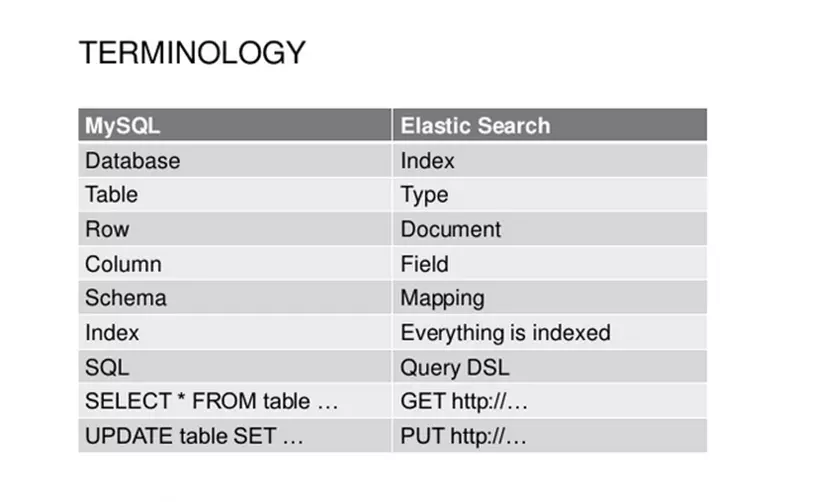 Cách lưu cấu trúc cơ bản của 1 cluster trong Elasticsearch
Cách lưu cấu trúc cơ bản của 1 cluster trong Elasticsearch
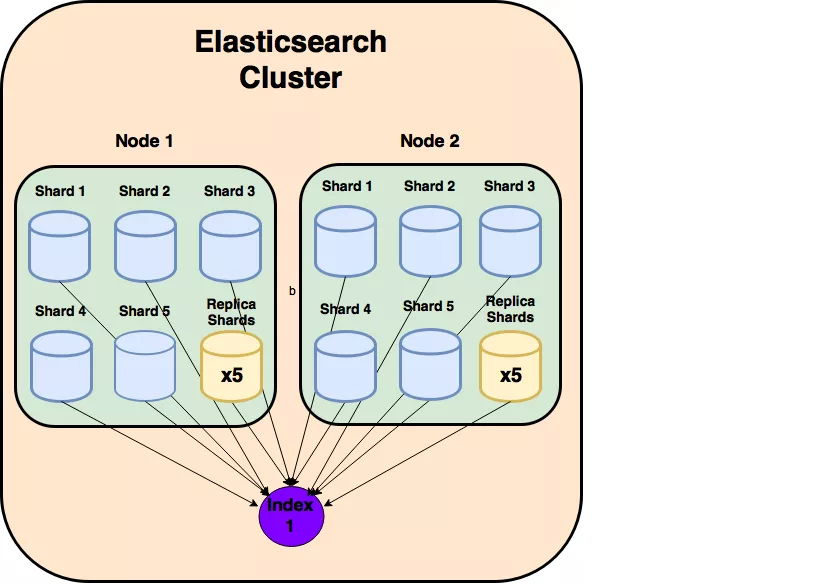
- Elasticsearch sử dụng inverted index để đánh chỉ mục cho các tài liệu. Inverted index là một cách đánh chỉ mục dựa trên trên đơn vị là từ nhằm mục đích tạo mối liên kết giữa các từ và các document chứa từ đó.
Cơ chế tìm kiếm
Giả sử có hai văn bản:
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
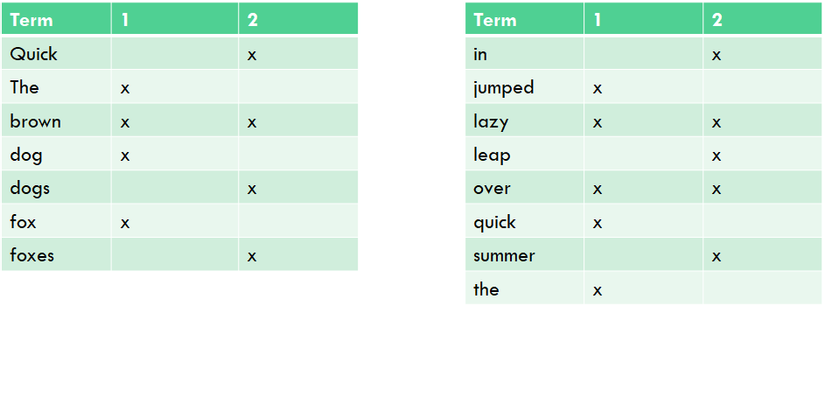 Khi tìm từ quick brown , ta chỉ cần tìm document mà các term xuất hiện:
Khi tìm từ quick brown , ta chỉ cần tìm document mà các term xuất hiện:
 Cả hai document đều khớp với kết quả tìm kiếm, nhưng có thể thấy document 1 có độ chính xác cao hơn so với document 2.
Cả hai document đều khớp với kết quả tìm kiếm, nhưng có thể thấy document 1 có độ chính xác cao hơn so với document 2.
Các câu truy vấn cơ bản
- Match query
Là truy vấn chuẩn để thực hiện full text query. Bao gồm truy vấn kết hợp và truy vấn cụm từ hoặc gần đúng. Match query chấp nhận văn bản, số, ngày tháng. Match query trả về các document chứa ít nhất 1 trong các từ trong truy vấn.

- Match Phrase Query
Trả về các document chứa cụm từ trong truy vấn.

- Match Phrase Prefix Query
Trả về các document khớp với tiền tố trong truy vấn.

- Multi Match Query
Tương tự match query nhưng cho phép tìm kiếm trên nhiều trường.

- Controlling percision
Sẽ làm gì khi người dung đưa ra 1 truy vấn có 4 từ và cần lấy có các document chứa ít nhất 3 từ trong đó. Elastic hỗ chợ minimum_should_match parameter, cho phép chỉ ra số terms sẽ so sánh trong tài liệu chứa các kết quả thích hợp .

- Combining Queries
Combining queries cho phép thực hiện nhiều điều kiện trong tìm kiếm.

- Controlling Analysis
Để nâng cao hiệu quả tìm kiếm cần sử dụng các Analyzer phù hợp. Analyzer là thành phần được sử dụng để chuẩn hóa các document trong Elasticsearch. Các Analyzer thực hiện một số công việc như: Character filters: Tiền xử lý chuỗi đầu vào như việc loại bỏ các thẻ html_tag hay chuyền ký hiệu & thành thành chữ "and". Tokenizer: Chuỗi sau khi được làm "sạch" bởi Chracter filters thì sẽ được tách từ bởi một bộ tách từ tokenizer do mình lựa chọn hoặc định nghĩa, đơn giản nhất là tách từ theo khoảng trắng hay dấu chấm câu, các từ được tách ra này gọi là term. Token filters Cuối cùng, mỗi term được qua Token filters (bộ lọc thẻ) để "làm mượt" thêm, ví dụ như việc chuyển các ký tự hoa về ký tự thường (lowercase) hay loại bỏ các từ dừng (từ xuất hiện nhiều nhưng gần như không ảnh hưởng tới kết quả tìm kiếm).
Query được phân tích bởi analyzer.

Fuzzy Search
Fuzzy Seach (tìm kiếm "mờ"), hay còn hay được gọi là Approximate Search (tìm kiếm "xấp xỉ") là khái niệm để chỉ kỹ thuật để tìm kiếm một xâu "gần giống" (thay vì "giống hệt") so với một xâu cho trước.
Việc áp dụng kỹ thuật Fuzzy Search giúp cho người dùng dễ dàng tiếp cận được với nội dung hơn, khi mà họ có thể tìm thấy được những thứ cần thiết, ngay cả khi họ không nhớ được chính xác nội dung mình muốn tìm kiếm là gì.
Fuzzy Seach trong Elasticsearch sử dụng nền tảng dựa trên khoảng cách Levenstein. Khoảng cách Levenshtein giữa chuỗi S1 và chuỗi S2 là số bước ít nhất biến chuỗi S1 thành chuỗi S2 thông qua 3 phép biến đổi là:
- xoá 1 ký tự.
- thêm 1 ký tự.
- thay ký tự này bằng ký tự khác.
Ví dụ: Khoảng cách Levenshtein giữa 2 chuỗi "kitten" và "sitting" là 3, vì phải dùng ít nhất 3 lần biến đổi.
kitten -> sitten (thay "k" bằng "s")
sitten -> sittin (thay "e" bằng "i")
sittin -> sitting (thêm ký tự "g")
Fuzzy search trong Elasticsearch sử dụng khoảng cách Levenshtein và cho phép ta config tham số fuzziness để cho kết quả phù hợp nhất với nhu cầu:
- 0, 1, 2: Là khoảng cách Levenshtein lớn nhất được chấp thuận. Nghĩa là trong ví dụ trên nếu bạn đặt fuzziness=3 thì "cân đường" sẽ không được tìm thấy với từ khoá "con đường"
- AUTO: Sẽ tự động điều chỉnh kết quả dựa trên độ dài của term. Cụ thể:
0..2: bắt buộc match chính xác (khoảng cách Levenshtein lớn nhất là 0)
3..5: khoảng cách Levenshtein lớn nhất là 1
5 trở lên: khoảng cách Levenshtein lớn nhất là 2
Đoạn truy vấn ví dụ cho tìm kiếm mờ

Kết luận
Như vậy ở trên đã hướng dẫn những vẫn đề cơ bản nhất về elasticsearch, hi vọng qua bài viết này sẽ giúp người đọc hiểu thêm hoặc biết thêm một công cụ hỗ trợ việc tìm kiếm kết quả một cách nhanh chóng mà nhiều người cũng như doanh nghiệp tin dùng, mong rằng người đọc sẽ có thể dử dụng tốt nó trong các dự án cũng như công việc của mình. Cảm ơn sự theo dõi của mọi người.
All rights reserved
