EfficientNet: Cách tiếp cận mới về Model Scaling cho Convolutional Neural Networks
Bài đăng này đã không được cập nhật trong 5 năm
Kể từ khi AlexNet giành chiến thắng trong cuộc thi ImageNet năm 2012, CNNs (viết tắt của Mạng nơ ron tích chập) đã trở thành thuật toán de facto cho nhiều loại nhiệm vụ trong học sâu, đặc biệt là đối với thị giác máy tính. Từ năm 2012 đến nay, các nhà nghiên cứu đã thử nghiệm và cố gắng đưa ra các kiến trúc ngày càng tốt hơn để cải thiện độ chính xác của mô hình trong các nhiệm vụ khác nhau. Hôm nay, chúng ta sẽ đi sâu vào nghiên cứu mới nhất, EfficientNet, không chỉ tập trung vào việc cải thiện độ chính xác mà còn cả hiệu quả của các mô hình.
Giới thiệu chung
Mạng Nơ-ron tích chập (Convolutional Neural Networks - ConvNets) thường được phát triển với ngân sách tài nguyên cố định và sau đó được thu phóng để có độ chính xác tốt hơn nếu có nhiều tài nguyên hơn. (Nguyên văn: Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available.). Bởi vậy nên nhóm tác giả Mingxing Tan và Quoc V. Le đã nghiên cứu một cách có hệ thống và nhận thấy rằng việc cân bằng một cách có hệ thống độ sâu, chiều rộng và độ phân giải mạng (network depth, width, and resolution) có thể mang đến hiệu suất tốt hơn. Phần sau đây sẽ trình bày lại vấn đề cần giải quyết, các khái niệm có liên quan cũng như hướng xử lý của các tác giả.
Trong bài viết, mình thử tìm trong một số tài liệu thì có một số dịch scaling là mở rộng quy mô tuy nhiên bản thân mình cảm thấy dịch là thu phóng (thu nhỏ và phóng to) sẽ sát nghĩa hơn bởi vậy trong bài viết này từ thu phóng sẽ được dùng để thay cho từ scaling trong nguyên văn.
Thu phóng mô hình CNN
Trước khi thảo luận về “Việc thu phóng mô hình có nghĩa là gì?”, thì thường chúng ta hay tự hỏi rằng tại sao việc thu phóng mô hình lại quan trọng. Câu trả lời là, ta có thể nói rằng việc thu phóng thường được thực hiện để cải thiện độ chính xác của mô hình đối với một tác vụ nhất định, chẳng hạn như phân loại ImageNet. Việc thu phóng quy mô, nếu được thực hiện đúng cách, cũng có thể giúp cải thiện hiệu quả của một mô hình.
Thu phóng mô hình có nghĩa là gì trong bối cảnh của CNN?
Như ta đã biết, có ba kích thước tỷ lệ của CNN: depth, width, and resolution:
Depthlà độ sâu của mạng tương đương với số lớp trong đó.Widthlà độ rộng của mạng. Ví dụ: một thước đo chiều rộng là số kênh trong lớp ConvResolutionlà độ phân giải hình ảnh được chuyển đến CNN.
Hình bên dưới (từ chính bài báo) sẽ cho chúng ta ý tưởng rõ ràng về việc thu phóng mô hình có nghĩa là gì trên các kích thước khác nhau. Chúng ta cũng sẽ thảo luận chi tiết về những điều này ở ngay sau đây.
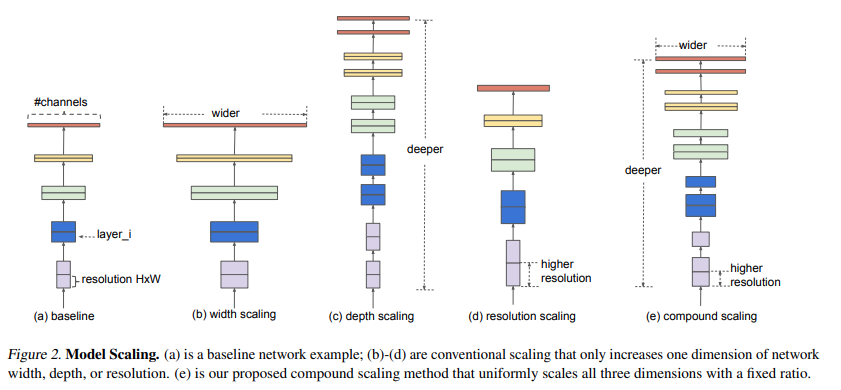
Thu phóng theo chiều sâu (Depth Scaling):
Thu phóng theo chiều sâu là một cách thông dụng nhất được sử dụng để thu phóng một mô hình CNN. Độ sâu có thể được thu phóng cũng như thu nhỏ bằng cách thêm hoặc bớt các lớp tương ứng. Ví dụ: ResNets có thể được mở rộng từ ResNet-50 đến ResNet-200 cũng như chúng có thể được thu nhỏ từ ResNet-50 thành ResNet-18. Tuy nhiên tại sao lại thu phóng quy mô độ sâu? Trực giác cho chúng ta ý nghĩ rằng một mạng lưới sâu hơn có thể nắm bắt các tính năng phong phú và phức tạp hơn, đồng thời khái quát tốt các tác vụ mới.
Tuy nhiên việc lạm dụng thu phóng theo chiều sâu có thể không cải thiện hiệu quả của mô hình, thậm chí có thể làm mô hình kém hiệu quả hơn so với mô hình ban đầu. Đúng là có một số lý do mà việc thêm nhiều lớp ẩn hơn sẽ cung cấp mức độ chính xác hơn cho mô hình. Tuy nhiên, điều này chỉ đúng với các tập dữ liệu lớn hơn, vì càng nhiều lớp với hệ số bước ngắn hơn sẽ trích xuất nhiều tính năng hơn cho dữ liệu đầu vào của bạn. Việc sử dụng một mô hình quá phức tạp với lượng dữ liệu không tương xứng, như ta đã biết, có thể gây ra hiện tượng Overfiiting. Thêm nữa, các mạng sâu hơn có xu hướng bị vanishing gradients và trở nên khó đào tạo. Vậy nên không phải lúc nào, thu phóng theo chiều sâu cũng là sự lựa chọn thích hợp để cải thiện mô hình CNN.
Thu phóng theo chiều rộng (Width Scaling):
Việc thu phóng theo chiều rộng của mạng (theo như trong hình minh họa ta có thể hiểu là thêm dữ liệu đầu vào) cho phép các lớp tìm hiểu các tính năng chi tiết hơn. Khái niệm này đã được sử dụng rộng rãi trong nhiều công trình như Wide ResNet và Mobile Net. Tuy nhiên, cũng như trường hợp tăng chiều sâu, tăng chiều rộng ngăn cản mạng học các tính năng phức tạp, dẫn đến giảm độ chính xác.
Thu phóng theo độ phân giải (Resolution Scaling)
Theo một cách trực quan, chúng ta có thể nói rằng trong một hình ảnh có độ phân giải cao, các đặc trưng sẽ có độ chi tiết cao hơn và do đó hình ảnh có độ phân giải cao sẽ hoạt động tốt hơn. Độ phân giải đầu vào cao hơn cung cấp hình ảnh chi tiết hơn và do đó nâng cao khả năng suy luận của mô hình về các đối tượng nhỏ hơn và trích xuất các mẫu mịn hơn. Tuy nhiên cũng như các cách thu phóng trên, việc chỉ thu phóng theo độ phân giải không hề luôn luôn hiệu quả trong mọi trường hợp mà thậm chí nó còn có thể giảm độ chính xác của mô hình đi một cách nhanh chóng.
Kết luận: Thu phóng quy mô bất kỳ kích thước nào về chiều rộng, chiều sâu hoặc độ phân giải của mạng sẽ cải thiện độ chính xác, nhưng độ chính xác sẽ giảm đối với các mô hình lớn hơn.
Hướng xử lý của các tác giả
Công thức hóa vấn đề
Lớp ConvNet thứ i có thể được định nghĩa là một hàm: , trong đó là toán tử, là tensor đầu ra, là tensor đầu vào, với kích thước tensor sẽ là: , trong đó và là spatial dimension và là channel dimension. Một ConvNet N có thể được biểu diễn bằng danh sách các layer gồm:
Trong thực tế, các lớp ConvNet thường được phân chia thành nhiều stage và tất cả các lớp trong mỗi stage đều có chung một kiến trúc: ví dụ: ResNet (He et al., 2016) có năm stage và tất cả các lớp trong mỗi stage có cùng một kiểu phức hợp ngoại trừ lớp đầu tiên thực hiện down sampling Do đó, chúng ta có thể định nghĩa Mạng Conv là:
trong đó biểu thị lớp được lặp lại lần trong stage biểu thị kích thước của tensor đầu vào X của lớp i
Không giống như các thiết kế ConvNet thông thường chủ yếu tập trung vào việc tìm kiếm kiến trúc lớp tốt nhất , việc thu phóng mô hình cố gắng thu phóng chiều dài mạng (), chiều rộng () và / hoặc độ phân giải () mà không thay đổi được xác định trước trong mạng cơ sở. Bằng cách giữ nguyên hàm , việc thu phóng mô hình đơn giản hóa vấn đề về thiết kế đối với tài nguyên hạn chế. Tuy nhiên vẫn có rất nhiều khả năng có thế xảy ra bởi chúng ta có thể thay đổi cả 3 chiều của mỗi lớp với mỗi mức độ khác nhau. Nhằm thu hẹp không gian tìm kiếm, nhóm tác giả đã hạn chế rằng tất cả các lớp phải được thu phóng đồng nhất với tỷ lệ không đổi. Mục tiêu của họ là tối đa hóa độ chính xác của mô hình cho bất kỳ lượng hạn chế tài nguyên nhất định nào, vấn đề này có thể được xem như một vấn đề tối ưu hóa.
Trong đó với là các hệ số để chia tỷ lệ chiều rộng, chiều sâu và độ phân giải của mạng; là các tham số được xác định trước trong mạng cơ sở.
Compound Scaling
Theo nhóm tác giả quan sát các chiều của các mô hình thường không thu nhỏ/thu phóng đọc lập với nhau. Bởi vậy nên, theo trực giác của bản thân, nhóm tác giả cho rằng chúng ta cần phối hợp và cân bằng các kích thước tỷ lệ khác nhau hơn là chia tỷ lệ một chiều thông thường.
Để xác thực trực giác của mình, nhóm tác giả so sánh việc thu phóng theo chiều rộng và theo các độ sâu cũng như độ phân giải mạng ở các mức độ khác nhau.
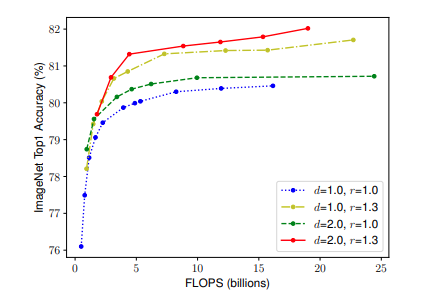
Từ kết quả được thể hiện trong hình trên, nhóm tác giả kết luận rằng:
Để đạt được độ chính xác và hiệu quả tốt hơn, điều quan trọng là phải cân bằng tất cả các kích thước của chiều rộng, chiều sâu và độ phân giải mạng trong quá trình thu phóng quy mô ConvNet
Trong bài báo này, nhóm tác giả đề xuất một phương pháp thu phóng phức hợp mới, sử dụng hệ số kép φ để thu phóng đồng nhất chiều rộng, độ sâu và độ phân giải của mạng theo cách có nguyên tắc:
Trrong đó :
- d, w, r lần lượt là độ rộng, độ sâu và độ phân giải của mạng
- α, β, γ là các hằng số có thể được xác định bằng small grid search.
Theo trực giác, φ là hệ số do người dùng chỉ định để kiểm soát số lượng tài nguyên khác có sẵn để thu phóng mô hình, trong khi α, β, γ chỉ định cách gán các tài nguyên bổ sung này cho độ rộng, độ sâu và độ phân giải của mạng tương ứng. Đáng chú ý, FLOPS của một op tích hợp thông thường tỷ lệ với , tức là, độ sâu mạng tăng gấp đôi sẽ tăng gấp đôi FLOPS, nhưng tăng gấp đôi độ rộng hoặc độ phân giải của mạng sẽ tăng FLOPS lên bốn lần. Vì các hoạt động tích phân thường chiếm ưu thế trong chi phí tính toán trong ConvNets, nên việc thu phóng Mạng Conv với phương trình 3 sẽ làm tăng tổng FLOPS khoảng . Trong bài báo này, chúng tôi ràng buộc sao cho với bất kỳ new mới nào, tổng FLOPS sẽ tăng xấp xỉ lên
Kiến trúc mạng EfficientNet
Để chứng minh tốt hơn hiệu quả của phương pháp thu phóng quy mô của mình, nhóm tác giả cũng đã phát triển một mạng cơ sở kích thước di động, được gọi là EfficientNet.
Lấy cảm hứng từ các nghiên cứu trước, nhóm tác giả phát triển mạng cơ sở của mình bằng cách tận dụng tìm kiếm kiến trúc no-ron đa mục tiêu để tối ưu hóa cả độ chính xác và FLOPS. Cụ thể, nhóm tác giả sử dụng cùng một không gian với phương pháp được mô tả trong MnasNet: Platform-aware neural architecture search for mobile và sử dụng làm mục tiêu tối ưu hóa, trong đó $ACC (m) $ và biểu thị độ chính xác và FLOPS của mô hình m, là mức FLOPS mục tiêu và là siêu tham số để kiểm soát sự cân bằng giữa độ chính xác và FLOPS. Tuy nhiên không giống nghiên cứu trên, ở đây nhóm tác giả tối ưu hóa FLOPS thay vì độ trễ vì họ không nhắm mục tiêu bất kỳ thiết bị phần cứng cụ thể nào. Từ đó nhóm tác giả tạo ra một mạng hiệu quả, thứ được đặt tên đặt tên là EfficientNet-B0.
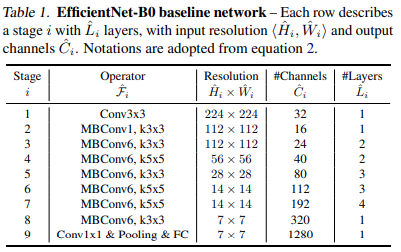
Bắt đầu từ mô hình cơ sở EfficientNet-B0, nhóm tác giả áp dụng phương pháp thu phóng phức hợp của mình để thu phóng quy mô với hai bước bao gồm:
- Đặt cố định giá trị của φ bằng 1, nhóm tác giả thu được bộ giá trị tối ưu theo ràng buộc của
- Cố định α, β, γ dưới dạng các hằng số và thu phóng mạng cơ sở với các φ khác nhau từ đó thu được để thu được từ EfficientNet-B1 đến EfficientNet-B1
Thực nghiệm
Hai phần sau đây liệt kê kết quả một số thí nghiệm được nhóm tác giả thực hiện. Để tìm hiểu rõ hơn về toàn bộ các thí nghiệm bao gồm các thức tiến hành, kết quả, nhận định, .... mọi người có thể tìm hiểu thêm ở trong bài báo.
Thu phóng quy mô MobileNets và ResNet
Để kiểm chứng tính hiệu quả của mô hình, trước tiên nhóm tác giả áp dụng phương pháp thu phóng quy mô của mình cho MobileNets và ResNet được sử dụng rộng rãi. Bảng sau đây hiển thị kết quả ImageNet của việc thu phóng chúng theo các cách khác nhau. So với các phương pháp chia tỷ lệ đơn chiều khác, phương pháp thu phóng phức hợp của nhóm tác giả cải thiện độ chính xác trên tất cả các mô hình này.
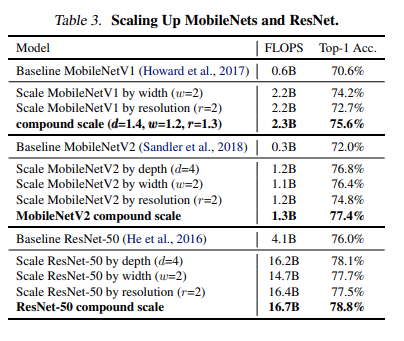
Kết quả thu được khi sử dụng trên ImageNet
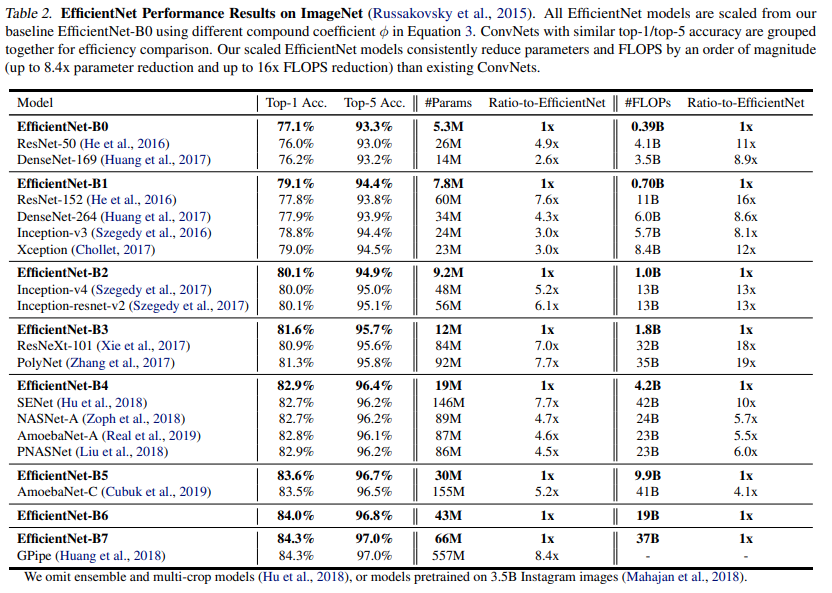
Bảng sau cho thấy hiệu suất của tất cả các mô hình EfficientNet được thu phóng từ cùng một mô hình EfficientNet-B0 khi huấn luyện trên ImageNet. Các mô hình EfficientNet của nhóm tác giả thường sử dụng thứ tự các tham số và FLOPS ít hơn so với các ConvNets khác với độ chính xác tương tự. Đặc biệt, EfficientNet-B7 của chúng tôi đạt độ chính xác top1 84,3% với thông số 66M và 37B FLOPS, chính xác hơn nhưng nhỏ hơn 8,4 lần so với GPipe tốt nhất trước đây. Những lợi ích này đến từ cả kiến trúc tốt hơn, thu phóng quy mô tốt hơn và cài đặt đào tạo tốt hơn được tùy chỉnh cho EfficientNet.
Cài đặt EfficientNet
Là kiến trúc mạng state-of-the-art accuracy with an order of magnitude fewer parameters and FLOPS, EfficientNet đã được cài đặt cho nhiều thư viện/framework khác nhau mà trong đó là Keras (và TensorFlow Keras) tại repo https://github.com/qubvel/efficientnet.
Bằng cài đặt thư viện này, chúng ta có thể thử sử dụng mà không cần hiểu sâu về EfficientNet. Do điều kiện không cho phép, phần sau sẽ giới thiệu một ví dụ nhỏ được chính tác giả của repo giới thiệu:
Đầu tiên import các thư viện cần thiết bằng đoạn mã sau:
import os
import sys
import numpy as np
from skimage.io import imread
import matplotlib.pyplot as plt
sys.path.append('..')
from keras.applications.imagenet_utils import decode_predictions
from efficientnet.keras import EfficientNetB0
from efficientnet.keras import center_crop_and_resize, preprocess_input
Tiếp đến chúng sẽ cùng sử dụng mô hình EfficientNetB0 để nhận dạng hình sau:

Để làm được điều đó, sau khi đọc ảnh vào, chúng ta có thể dễ dàng sử dụng mô hình mô hình pretrained bằng đoạn mã ngắn sau:
image = imread('../misc/panda.jpg')
# loading pretrained model
model = EfficientNetB0(weights='imagenet')
image_size = model.input_shape[1]
x = center_crop_and_resize(image, image_size=image_size)
x = preprocess_input(x)
x = np.expand_dims(x, 0)
# make prediction and decode
y = model.predict(x)
decode_predictions(y)
Kết quả thu được sẽ như sau:
[[('n02510455', 'giant_panda', 0.83479345),
('n02134084', 'ice_bear', 0.015601922),
('n02509815', 'lesser_panda', 0.004553494),
('n02133161', 'American_black_bear', 0.002471902),
('n02132136', 'brown_bear', 0.0020707482)]]
Tổng kết
Bài viết này trình bày lại bài báo về EfficientNet và các kiến thức liên quan dựa trên cơ sở tự tìm hiểu thêm cũng như giới thiệu một ví dụ nhỏ sử dụng phần cài đặt sẵn của kiến trúc mạng này. Có thể thấy rằng các kiến trúc mạng mới nhận được rất nhiều sự quan tâm và đã được cài đặt trên các framework Machine learining phổ biến hiện nay. Tuy nhiên để có khả năng tự đánh giá và sửa đổi cũng như cải tiến để phù hợp với bài toán của bản thân, người dùng vẫn cần tìm hiểu kĩ về bản chất và cách hoạt động của các phương pháp này. Bài viết đến đây là kết thúc cảm ơn mọi người đã giành thời gian đọc.
Tài liệu tham khảo
All rights reserved
