Effective JavaScript - Chapter 1 - Accustoming Yourself to JavaScript (Part VI)
Bài đăng này đã không được cập nhật trong 4 năm
JavaScript được thiết kế để mang lại cảm giác quen thuộc. Với cú pháp (syntax) gợi nhớ về Java và hàm dựng vốn dĩ đã phổ biến ở rất nhiều ngôn ngữ scripting (function, array, dictionary và regular expression), JavaScript dường như là một cái gì đó dễ học với bất cứ ai đã có một chút kinh nghiệm về programming. Và với các programmer ít kinh nghiệm, họ có thể bắt đầu viết các chương trình mà không cần training quá nhiều tại vì lượng khái niệm core trong JavaScript là không quá nhiều.
Việc tiếp cận tuy dễ dàng, nếu muốn thuần thục (master) nó thì sẽ mất khá nhiều thời gian và đòi hỏi sự hiểu biết sâu hơn về ngữ nghĩa, các đặc tính và các idiom hữu hiệu nhất của nó. Mỗi chapter của cuốn sách này sẽ đề cập đến một phạm vi chủ đề khác nhau của effective JavaScript. Chương đầu tiên này bắt đầu với một vài topic cơ bản nhất.
Item 7: Think of Strings As Sequences of 16-Bit Code Units
Unicode nổi tiếng là phức tạp - mặc dù string xuất hiện ở khắp mọi nơi, đa số các lập trình viên tránh tìm hiểu về Unicode và hy vọng về những điều tốt nhất đến với họ. Nhưng ở mức khái niệm, chẳng có gì để phải lo lắng cả. Mục đích (basics) của Unicode đơn giản chỉ là: Mỗi đơn vị văn bản (unit of text) của tất cả các hệ thống chữ viết trên thế giới đều được quy về một số tự nhiên duy nhất trong khoảng 0 đến 1,114,111. Những giá trị này được gọi là điểm mã (code point) trong thuật ngữ Unicode. Unicode hầu như không có gì khác so với các cách mã hóa văn bản khác như là ASCII. Tuy nhiên, điểm khác biệt chính là trong ASCII map mỗi chỉ mục (index) với một biểu diễn nhị phân duy nhất, Unicode lại cho phép đa mã hóa nhị phân khác nhau cho các điểm mã. Các cách mã hóa khác đánh đổi giữa dung lượng bộ nhớ cần cho một string và tốc độ xử lý các thao tác trên string đó. Ngày nay, có nhiều chuẩn Unicode khác nhau. Tuy nhiên UTF-8, UTF-16 và UTF-32 được sử dụng phổ biến nhất.
Trong quá khứ, những người thiết kế ra Unicode đã tính toán nhầm ngân sách (budget) cho các điểm mã. Ban đầu thì họ nghĩ rằng Unicode không cần quá 2^16 điểm mã. Đây chính là UCS-2, bộ mã hóa 16-bit thuở sơ khai. Bởi vì mỗi điểm mã có thể gắn với một số 16-bit, sẽ có một mapping một - một giữa các điểm mã và các phần tử của bảng mã - hay còn gọi là đơn vị mã (code unit). Lợi ích chính của các mã hóa này chính là ở việc đánh chỉ mục cho một string: tốn ít thời gian và bất biến. Việc truy cập vào điểm mã thứ n của một string đơn thuần chỉ là lấy ra phần tử 16-bit thứ n của mảng. Hình 1.1 thể hiện một string mẫu, chỉ gồm các điểm mã trong dải 16-bit ban đầu. Như bạn có thể thấy, các chỉ mục ăn khớp giữa các phần tử của bảng mã và các điểm mã trong string.
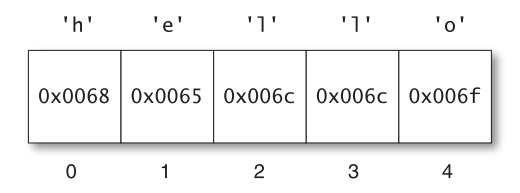
Hình 1.1 Một string JavaScript chứa các điểm mã từ mặt đa ngôn ngữ cơ bản (Basic Multilingual Plane - BMP)
Kết quả là một số nền tảng đã cam kết sử dụng chuẩn mã hóa 16-bit. Java và JavaScript là hai trong số đó. Hiện nay, nếu Unicode giữ nguyên như những năm đầu của thập niên 90, mỗi phần tử của một string JavaScript vẫn sẽ tương ứng với một điểm mã đơn.
Dải 16-bit này thực sự lớn, có thể bao hàm nhiều hơn rất nhiều các hệ thống văn bản so với ASCII. Mặc dù vậy, sau cùng thì Unicode đã phát triển vượt quá dải ban đầu của nó và hiện tại thì đã vượt ngưỡng 2^20 điểm mã. Dải mới này được chia thành 17 dải con gồm 2^16 điểm mã. Đầu tiên trong số này, mặt đa ngôn ngữ cơ bản (BMP), gồm 2^16 điểm mã thuở sơ khai. 16 dải mới thêm vào được gọi là các mặt bổ sung (supplementary plane).
Từ khi dải điểm mã phồng ra, UCS-2 đã trở nên lỗi thời: Nó cần được mở rộng để biểu diễn các điểm mã mới. Người kế nhiệm của nó, UTF-16, cũng gần giống như vậy, trừ sự xuất hiện của surrogate pair (cặp thay thế): Các cặp đơn vị mã 16-bit cùng nhau mã hóa một điểm mã đơn 2^16 hoặc lớn hơn. Ví dụ, khóa Sol (music symbol G-clef) 𝄞, tương ứng với điểm mã U+1D11E - mã hexa của 119,070, được biểu diễn trong UTF-16 bởi một cặp đơn vị mã 0xd834 và 0xdd1e. Điểm mã có thể được giải mã bằng cách kết hợp các bit được lựa chọn từ hai đơn vị mã. (Một cách khôn ngoan, việc mã hóa đảm bảo các surrogate không bị nhầm lẫn với điểm mã BMP). Bạn có thể thấy một ví dụ về một string với một surrogate pair trong Hình 1.2. Điểm mã đầu tiên của string cần một surrogate pair, làm cho các chỉ mục của các đơn vị mã khác với chỉ mục của các điểm mã.
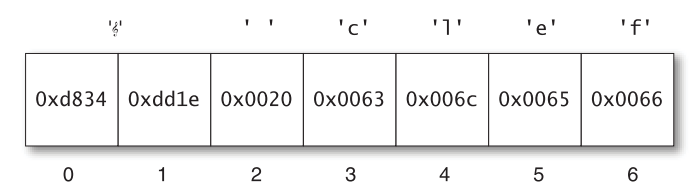
Hình 1.2 Một string JavaScript chứa một điểm mã từ mặt bổ sung
Bởi vì mỗi điểm mã trong mã hóa UTF-16 có thể cần một hoặc hai đơn vị mã 16-bit, UTF-16 là một cách mã hóa có độ dài biến thiên (variable-length): Kích thước trong bộ nhớ của một string có độ dài n biến thiên dựa vào các điểm mã đặc biệt trong string. Hơn nữa, tìm điểm mã thứ n của một string cũng không còn là một toán tử với thời gian hằng số nữa: Nó thường sẽ cần phải tìm kiếm từ đầu string.
Nhưng khi Unicode phồng lên về kích cỡ, JavaScript đã sử dụng string 16-bit sẵn rồi. Các property và method của string như là length, charAt, charCodeAt đều hoạt động ở mức các đơn vị mã thay vì các điểm mã. Vậy nên bất cứ khi nào một string chứa các điểm mã từ các mặt phẳng bổ sung, JavaScript biểu diễn mỗi điểm mã như là hai phần tử - surrogate pair của điểm mã - thay vì một. Đơn giản:
An element of a JavaScript string is a 16-bit code unit (Mỗi phần tử của một string JavaScript là một đơn vị mã 16-bit)
Bản thân các JavaScript engine có thể tối ưu việc lưu các nội dung string (string content). Nhưng nếu nói về propery và method, string hoạt động giống như các chuỗi đơn vị mã UTF-16. Xét string ở Hình 1.2. Mặc dù string đó chứa 6 điểm mã, JavaScript lại nói chiều dài của nó là 7:
"𝄞 clef".length; // 7
"G clef".length; // 6
Trích rút các phần tử của string sẽ sinh ra các đơn vị mã thay vì các điểm mã:
"𝄞 clef".charCodeAt(0); // 55348 (0xd834)
"𝄞 clef".charCodeAt(1); // 56606 (0xdd1e)
"𝄞 clef".charAt(1) === " "; // false
"𝄞 clef".charAt(2) === " "; // true
Tương tự, các regular expression hoạt động ở mức đơn vị mã. Pattern ký tự đơn (single-character pattern) - . - match với một đơn vị mã đơn:
/^.$/.test("𝄞"); // false
/^..$/.test("𝄞"); // true
Những ví dụ này cho thấy rằng các ứng dụng làm việc với dải Unicode đầy đủ phải làm việc khó khăn hơn: Chúng không thể dựa vào các string method, length value, indexed lookup hay regular expression pattern. Nếu bạn đang làm việc không chỉ với BMP, bạn nên tìm kiếm sự giúp đỡ từ các thư viện nhận dạng điểm mã. Việc tự implement các đoạn code mã hóa và giải mã một cách đúng đắn thực sự rất phức tạp. Vậy nên tốt nhất là bạn nên sử dụng một thư viện có sẵn.
Chừng nào kiểu dữ liệu string được xây dựng sẵn của JavaScript còn hoạt động ở mức các đơn vị mã, nó sẽ không ngăn cản các API nhận ra các điểm mã và các surrogate pair. Trong thực tế, có một vài thư viện ECMAScript chuẩn xử lý các surrogate pair một cách chính xác như là: các hàm xử lý URI encodeURI, decodeURI, encodeURIComponent và decodeURIComponent. Bất cứ khi nào một môi trường JavaScript cung cấp một thư viện xử lý string - ví dụ, thay đổi content của một trang web hoặc thực hiện các thao I/O với string - bạn nên tham khảo tài liệu hướng dẫn của thư viện để thấy cách nó xử lý dải các điểm mã Unicode đầy đủ.
Things to Remember:
-
Các string JavaScript gồm các đơn vị mã 16-bit, chứ không phải các điểm mã Unicode
-
Các điểm mã Unicode 2^16 và lớn hơn được biểu diễn trong JavaScript bởi hai đơn vị mã - một surrogate pair
-
Các surrogate pair loại bỏ việc đếm các string element - điều này ảnh hưởng đến các method
length,charAt,charCodeAtvà các regular expression pattern như. -
Sử dụng các third-party library để viết các đoạn code xử lý string nhận dạng điểm mã
-
Bất cứ khi nào bạn sử dụng một library làm việc với string, hãy tham khảo tài liệu hướng dẫn để xem cách nó xử lý dải các điểm mã đầy đủ
Trên đây là phần dịch cho Item 7 trong 68 item được đề cập đến trong cuốn sách Effective JavaScript của tác giả David Herman.
Homepage: http://effectivejs.com/
All rights reserved
