Dùng word2vec + LSTM trong bài toán classify thực tế, version example code (ít lý thuyết) :)
Bài đăng này đã không được cập nhật trong 3 năm
Load data
import pandas as pd
import numpy as np
# Import confusion_matrix and classification_report from the sklearn.metrics module
from sklearn.metrics import confusion_matrix, classification_report
df = pd.read_csv('./Restaurant_Reviews.tsv', sep='\t')
print(df)
Load model word2vec pretrained
import pandas as pd
from datetime import date, timedelta
import re
from nltk.tokenize import word_tokenize
from gensim import corpora, models
from gensim.models import KeyedVectors
from gensim.matutils import corpus2dense
import gensim
#Loading the word vectors from Google trained word2Vec model
GoogleModel = KeyedVectors.load_word2vec_format('./model/GoogleNews-vectors-negative300.bin', binary=True)
Test model
word = 'apple'
vector = GoogleModel[word]
print(vector.shape)
similar_words = GoogleModel.most_similar(word)
print(similar_words)
[('apples', 0.720359742641449), ('pear', 0.6450697183609009), ('fruit', 0.6410146355628967), ('berry', 0.6302294731140137),
Convert sang list token theo vocabulary
from keras_preprocessing.text import Tokenizer
from keras_preprocessing import sequence
tokenizer = Tokenizer()
tokenizer.fit_on_texts(df['Review'])
sequences = tokenizer.texts_to_sequences(df['Review'])
maxlen = 100
X = sequence.pad_sequences(sequences, maxlen=maxlen)
print('X:\n', X[:10])
Tạo ember maxtrix
import numpy as np
embedding_dim = 300
word_index = tokenizer.word_index
num_words = min(len(word_index) + 1, len(GoogleModel.index_to_key))
embedding_matrix = np.zeros((num_words, embedding_dim))
print('num_words:', num_words)
for word, i in word_index.items():
if i >= num_words:
continue
if word in GoogleModel.index_to_key:
embedding_matrix[i] = GoogleModel.word_vec(word)
Tạo model train
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense, LSTM, Bidirectional
model = Sequential()
model.add(Embedding(num_words, embedding_dim, input_length=maxlen, weights=[embedding_matrix], trainable=False))
model.add(Bidirectional(LSTM(64, return_sequences=True, input_shape=(maxlen, ))))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc'])
model.summary()
Model: "sequential_26"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_26 (Embedding) (None, 100, 300) 621600
bidirectional_8 (Bidirectio (None, 100, 128) 186880
nal)
flatten_14 (Flatten) (None, 12800) 0
dense_17 (Dense) (None, 1) 12801
=================================================================
Total params: 821,281
Trainable params: 199,681
Non-trainable params: 621,600
_________________________________________________________________
Tạo data test
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, df['Liked'], test_size=0.3, random_state=101)
Train thôi.
model.fit(X_train, y_train, epochs=10, batch_size=32)

Test độ chính xác nồ
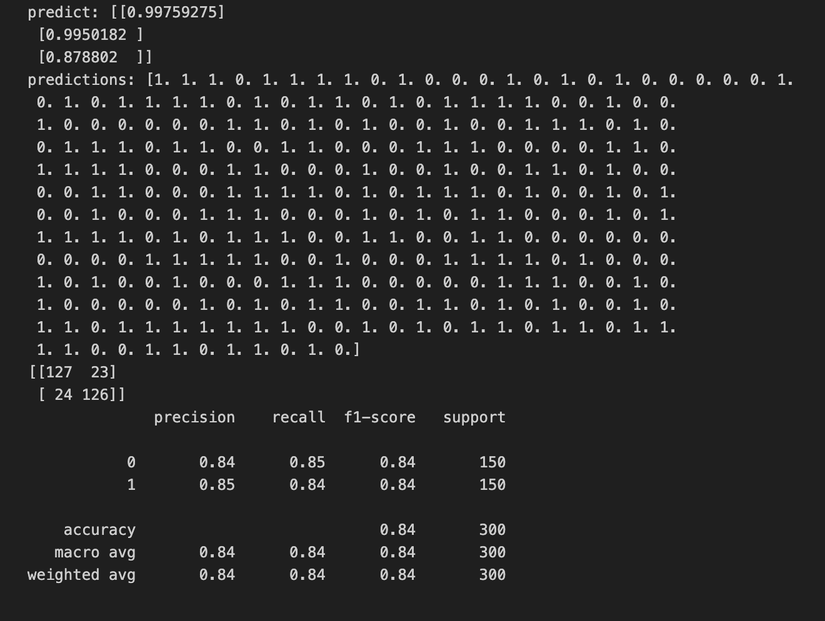
predictions = model.predict(X_test)
print('predict:', predictions[:3])
predictions = np.round(predictions)
print('predictions:', predictions.flatten())
print(confusion_matrix(y_test, predictions))
print(classification_report(y_test, predictions))
Done, code cứ thế mà run thôi , hy vọng sẽ giúp ích được cho mọi người  . Thank for reading
. Thank for reading  ,
,
All rights reserved
