Đừng để Claude Code chạy "chay": Xây dựng quy trình phát triển hoàn toàn tự động với MCP và Skills (Phần 2)
Bạn không biết cách để AI đọc cơ sở dữ liệu cục bộ và các tài liệu mới nhất? Bài hướng dẫn Claude Code này sẽ đưa bạn đi sâu vào giao thức Model Context Protocol (MCP) và các kỹ năng tùy chỉnh (custom skills) thông qua
SKILL.md. Chúng tôi sẽ hướng dẫn bạn từng bước cách cấu hìnhmcp.json, tích hợp GitHub, Playwright và Context7, đồng thời xây dựng một quy trình Code Review tự động, không có "ảo giác" (zero-hallucination).
Trong bài viết trước, chúng ta đã giới thiệu về việc thiết lập môi trường cơ bản và quản lý ngữ cảnh cho Claude Code. Việc chạy Claude Code yêu cầu môi trường Node.js, và với ServBay, chúng ta có thể triển khai môi trường cục bộ chỉ với một cú nhấp chuột mà không cần cấu hình. Tuy nhiên, chỉ biết những điều cơ bản là chưa đủ; các lập trình viên chắc chắn sẽ gặp phải những nút thắt kỹ thuật mới trong quá trình sử dụng.
Nếu dự án của bạn cần tích hợp một API của bên thứ ba mới được phát hành, nhưng dữ liệu huấn luyện của chương trình chưa được cập nhật, điều gì sẽ xảy ra khi AI viết code dựa trên thông tin lỗi thời? Thông thường, nó sẽ gượng ép tạo ra mã dựa trên logic cũ. Vậy, làm thế nào để chúng ta giải quyết tình trạng AI bị "ảo giác"? Hơn nữa, một kỹ sư frontend có thể muốn máy móc kiểm tra xem các kiểu dáng (styles) của trang có bị lệch hay không, hoặc một kỹ sư backend có thể cần xác minh các trường trong cơ sở dữ liệu. Quyền truy cập đọc mã cục bộ đơn giản không thể đáp ứng được những nhu cầu này nữa.
Bài hướng dẫn Claude Code nâng cao này sẽ tập trung "mổ xẻ" hai tính năng cấp cao: Claude Skills để xây dựng các quy trình làm việc nội bộ, và giao thức Claude Code MCP để mở các kênh dữ liệu bên ngoài. Nắm vững hai công nghệ này có thể biến một trợ lý lập trình đơn thuần thành một cộng sự R&D (Nghiên cứu & Phát triển) toàn diện.

Điều kiện tiên quyết cho các thao tác nâng cao
Trước khi đi sâu vào cấu hình, vui lòng đảm bảo môi trường phát triển cục bộ của bạn đáp ứng các điều kiện sau:
-
Đã nắm vững cấu hình cơ bản: Khuyến nghị bạn nên đọc phần đầu tiên của loạt bài này trước để đảm bảo bạn đã hoàn tất việc khởi tạo môi trường cơ bản và quen thuộc với cách quản lý ngữ cảnh hội thoại.
-
Cấu hình môi trường Node.js 18+: Chạy các máy chủ MCP khác nhau yêu cầu một môi trường Node tương đối mới. Chúng tôi khuyên dùng ServBay, một công cụ quản lý môi trường phát triển web cục bộ. Thông qua bảng điều khiển trực quan của nó, bạn có thể cài đặt và chuyển đổi các phiên bản Node.js 18+ chỉ bằng một cú nhấp chuột, giúp bạn tiết kiệm các bước cấu hình biến môi trường hệ thống thủ công tẻ nhạt.
-
Chuẩn bị một dự án có UI: Chuẩn bị sẵn một dự án cục bộ chứa các trang frontend để sau này trải nghiệm khả năng kiểm thử giao diện trực quan của plugin Playwright.
-
Lấy quyền truy cập tài khoản GitHub: Chuẩn bị một tài khoản GitHub và một Personal Access Token có quyền truy cập kho lưu trữ (được sử dụng để trình diễn quy trình làm việc tự động của GitHub MCP).
Thiết lập các Tiêu chuẩn và Claude Skills
Nếu chỉ dựa vào việc gõ thủ công các câu prompt (lời nhắc) dài dòng mỗi lần để yêu cầu chương trình tự động hoàn thành các tác vụ cụ thể là cực kỳ kém hiệu quả. Claude Skills cung cấp một cơ chế để xác định các quy trình thao tác được tiêu chuẩn hóa.
Các tệp kỹ năng (skill files) về bản chất là các đặc tả Markdown được lưu trữ trong các thư mục cụ thể. Khi lập trình viên đưa ra yêu cầu bằng ngôn ngữ tự nhiên, chương trình sẽ tự động khớp và kích hoạt kỹ năng tương ứng, qua đó thực thi tác vụ theo các bước chuyên môn đã được thiết lập sẵn.
Các lập trình viên có thể lưu các kỹ năng dành riêng cho dự án trong thư mục .claude/skills/ ở thư mục gốc của dự án, hoặc đặt các kỹ năng có thể áp dụng chung vào thư mục cấp hệ thống ~/.claude/skills/.
Cách viết SKILL.md

Nền tảng của việc tạo ra một kỹ năng thực tế là viết một tệp cấu hình rõ ràng. Ở đây, chúng tôi sử dụng một kỹ năng đánh giá bảo mật (security review) tự động làm ví dụ để minh họa cấu trúc cơ bản của tệp cấu hình.
---
name: Đánh giá Bảo mật và Tuân thủ
description: Tiến hành quét lỗ hổng bảo mật toàn diện và xác thực định dạng trên code được gửi
triggers:
- Đánh giá code thay đổi
- Thực thi quét bảo mật
- Kiểm tra tuân thủ code
allowed-tools:
- Read
- Glob
- Bash(git diff HEAD)
---
# Hướng dẫn Thực thi Đánh giá
## Chi tiết từng bước
1. Chạy `git diff HEAD` để lấy các khác biệt của code chưa được commit hiện tại
2. Lọc ra các tệp đã thay đổi và phân loại chúng theo ngôn ngữ
3. Thực hiện so sánh từng dòng dựa trên các tiêu chuẩn bảo mật bên dưới
4. Tổng hợp các kết luận đánh giá rõ ràng
## Các kiểm tra Bảo mật Bắt buộc
- Đảm bảo không có chuỗi kết nối cơ sở dữ liệu hoặc key nào được hardcode trong các tệp
- Xác minh rằng tất cả các tham số đầu vào bên ngoài đã trải qua quá trình xác thực kiểu dữ liệu
- Kiểm tra xem tất cả các request bất đồng bộ có bao gồm cơ chế xử lý ngoại lệ hay không
## Yêu cầu định dạng đầu ra
- 🔴 Rủi ro nghiêm trọng [Chỉ ra vị trí cụ thể và cung cấp code khắc phục]
- 🟡 Mối nguy tiềm ẩn [Giải thích các vấn đề tiềm ẩn mà nó có thể gây ra]
- 🟢 Thực hành tốt [Ghi nhận các đoạn code được viết tốt]
Phần đầu của cấu hình này sử dụng định dạng YAML để xác định các thuộc tính cơ bản. triggers xác định các từ khóa để "đánh thức" kỹ năng này. allowed-tools thiết lập các ranh giới bảo mật, giới hạn kỹ năng chỉ được đọc tệp và thực thi một phạm vi lệnh Git cụ thể, ngăn chặn việc vô tình sửa đổi hoặc xóa tệp trong quá trình đánh giá.
Để tiết kiệm bộ nhớ hội thoại, các hướng dẫn kỹ năng phức tạp không nên bị nhồi nhét vào một tệp duy nhất. Bạn có thể áp dụng phương pháp mô-đun hóa, sử dụng @reference.md trong tệp chính để tham chiếu đến các sổ tay quy tắc chi tiết bên ngoài, đạt được khả năng tải theo nhu cầu (on-demand loading).
Cây cầu nối với Thế giới bên ngoài
Với các tiêu chuẩn thực thi nội bộ đã sẵn sàng, bước tiếp theo là giải quyết vấn đề thu thập dữ liệu bên ngoài. Điều này dẫn đến một công nghệ mới hiện đang nhận được rất nhiều sự chú ý trong cộng đồng lập trình viên.
Giao thức MCP là gì?
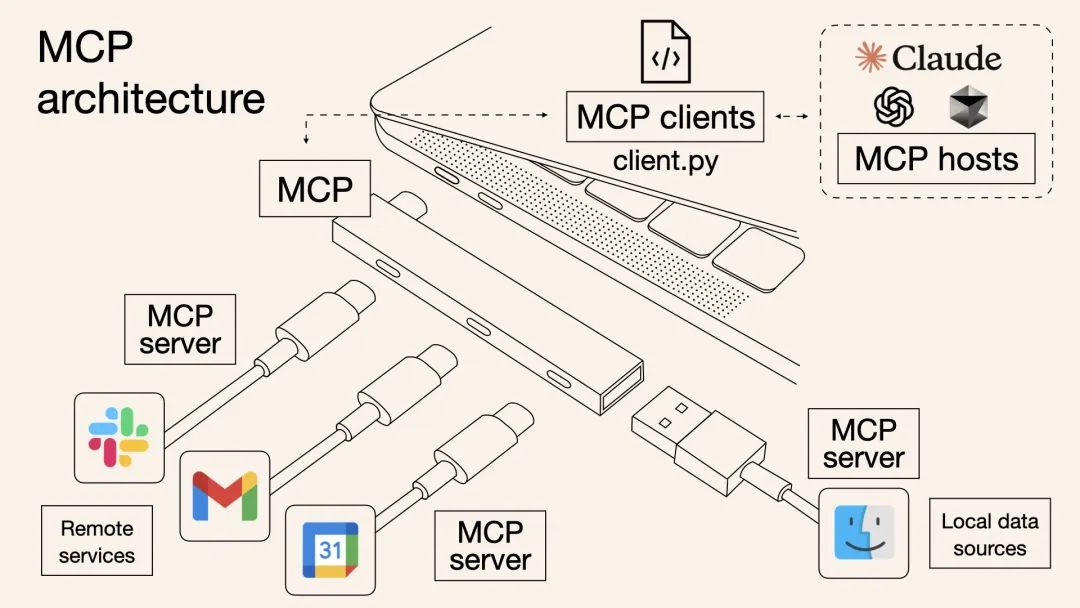
Model Context Protocol (MCP) là một tiêu chuẩn giao tiếp mở. Mục đích của nó là cung cấp một bộ giao diện phổ quát cho các mô hình AI, cho phép chúng kết nối an toàn với các công cụ và nguồn dữ liệu bên ngoài. Nếu Skills là phương pháp luận hướng dẫn công việc, thì Claude Code MCP chính là hộp công cụ thực tế cần thiết để thực thi công việc đó.
Bằng cách chạy các chương trình máy chủ MCP nhỏ ở local, các lập trình viên có thể mở ra các khả năng như cào dữ liệu web (web scraping), truy vấn cơ sở dữ liệu và quản lý phiên bản (version control) để các mô hình ngôn ngữ lớn có thể gọi đến.
Hướng dẫn Cấu hình mcp.json
Tất cả các kết nối máy chủ bên ngoài cần được đăng ký trong tệp .claude/mcp.json. Dưới đây là một mẫu cấu hình chứa các dịch vụ phổ biến, cho thấy cách cấu hình các tham số môi trường và lệnh khởi động.
{
"mcpServers": {
"github_connect": {
"command": "npx",
"args": ["-y", "@anthropic-ai/mcp-server-github"],
"env": {
"GITHUB_TOKEN": "${GITHUB_TOKEN}"
}
},
"doc_fetcher": {
"command": "npx",
"args": ["-y", "@anthropic-ai/mcp-server-context7"]
},
"ui_tester": {
"command": "npx",
"args": ["-y", "@anthropic-ai/mcp-server-playwright"]
}
}
}
Đặt tệp này trong thư mục cấu hình cấp dự án hoặc cấp hệ thống của bạn, và chương trình sẽ tự động gắn kết (mount) các khả năng này khi khởi động. Nếu việc gắn kết thất bại, bạn có thể thêm tham số --mcp-debug trong terminal để xem các log lỗi cụ thể.
Bốn Kịch bản Thực tế Tần suất cao
Sau khi cấu hình xong, trải nghiệm phát triển của bạn sẽ được nâng cao đáng kể. Dưới đây là một số kịch bản ứng dụng điển hình giúp giải quyết các "nỗi đau" (pain points) thực tế.
Lấy Tài liệu Mới nhất để Giải quyết Độ trễ Thông tin
Đối mặt với các bản cập nhật framework frontend thường xuyên, việc sử dụng Context7 MCP có thể tránh hoàn toàn sự can thiệp từ dữ liệu lỗi thời. Khi một lập trình viên yêu cầu viết một component sử dụng các tính năng mới nhất của React, chương trình sẽ tự động gọi dịch vụ này để thu thập tài liệu thời gian thực chính thức và xuất ra code theo các thông số API mới nhất, loại bỏ triệt để tình trạng "ảo giác" kỹ thuật.
Đưa ra Phản hồi Trực quan để Hoàn thiện Vòng lặp Frontend
Thông thường, logic code UI được tạo ra là chính xác, nhưng kiểu dáng (styling) lại hơi chệch choạc. Với plugin Playwright, việc AI kiểm thử các trang frontend trở nên cực kỳ trực quan. Chương trình có thể khởi chạy một trình duyệt headless (không giao diện) ở chế độ nền, truy cập vào máy chủ phát triển cục bộ và thực hiện phân tích ảnh chụp màn hình trên trang được render. Nó có thể phát hiện các vấn đề như các nút bị che khuất hoặc lề không nhất quán giống như một kỹ sư con người, và sửa đổi code CSS cho phù hợp.
Nắm bắt Cấu trúc Lưu trữ Cơ sở
Khi viết các logic nghiệp vụ phức tạp, việc cho phép AI đọc cấu trúc cơ sở dữ liệu cục bộ là chìa khóa để cải thiện độ chính xác. Sau khi cấu hình các plugin kết nối cho PostgreSQL hoặc SQLite, chương trình có thể trực tiếp truy vấn các cấu trúc bảng thực tế, kiểu trường và các ràng buộc quan hệ. Sau đó, khi bạn yêu cầu nó viết các script di chuyển dữ liệu (data migration) hoặc các câu lệnh truy vấn JOIN, nó có thể khớp hoàn hảo với mô hình dữ liệu nghiệp vụ hiện tại của bạn.
Tích hợp Liền mạch với các Nền tảng Lưu trữ Code
Sau khi cấu hình token truy cập GitHub, chương trình có thể kéo chi tiết các pull request từ xa (remote) trực tiếp ngay trong terminal. Nếu phát hiện sự cố, nó thậm chí có thể gọi API trực tiếp để tạo Issue hoặc thêm các bình luận đánh giá (review comments) trên nền tảng lưu trữ code, tất cả mà không cần phải mở trình duyệt.
Sự Cộng hưởng giữa Skills và các Thiết bị ngoại vi (Peripherals)
Kết hợp các tiêu chuẩn với các nguồn dữ liệu sẽ giải phóng những khả năng tự động hóa cực kỳ mạnh mẽ.
Hãy tưởng tượng một quy trình phát triển hàng ngày: Lập trình viên nhập một lệnh trong terminal, yêu cầu xác minh commit mới nhất và xác nhận rằng hiển thị frontend là chính xác.
Khi nhận được lệnh, plugin GitHub chịu trách nhiệm kéo các khác biệt (diffs) của code, kỹ năng code review cung cấp các tiêu chí đánh giá, Context7 xác minh xem các thư viện của bên thứ ba có được sử dụng chính xác hay không, và cuối cùng, Playwright truy cập URL xem trước (preview) để xác thực qua ảnh chụp màn hình. Khi mọi thứ được xác minh không có lỗi, báo cáo đánh giá sẽ tự động được đồng bộ hóa với kho lưu trữ từ xa.
Thú vị hơn nữa, các lập trình viên có thể yêu cầu chương trình tự viết các đặc tả kỹ năng. Hãy lưu một tài liệu API thanh toán của bên thứ ba hoàn toàn mới ở local, và ra lệnh cho chương trình đọc tài liệu đó rồi tạo ra một kỹ năng tích hợp cho dự án hiện tại. Nó sẽ tự động trích xuất các phương thức xác thực và các quy tắc xử lý lỗi, tạo ra một tệp SKILL.md hoàn chỉnh để lưu trữ trong thư viện kỹ năng cho việc tái sử dụng trong tương lai.
Khi các lập trình viên đã thành thạo trong việc cấu hình các mô-đun nâng cao này, một môi trường R&D hiệu quả cao, chính xác và hiểu rõ nghiệp vụ sẽ được xây dựng thành công. Trong loạt bài hướng dẫn sắp tới, chúng ta sẽ khám phá các thực tiễn kiến trúc vĩ mô hơn, thảo luận về cách tận dụng việc phát triển song song đa phiên bản (multi-instance) và tích hợp luồng xử lý (pipeline) tự động để xử lý các dự án kỹ thuật quy mô lớn.
All rights reserved
