Dockerize project crawl dữ liệu với Puppeteer
Bài đăng này đã không được cập nhật trong 2 năm
Xin chào các bạn, mình là Việt. Sau một thời gian sử dụng Viblo như một công cụ hỗ trợ đọc và tìm hiểu các Tech mới từ các anh chị, các bạn và cũng có cả các em nữa thì hôm nay đây sẽ là bài viết đầu tiên của mình trên diễn đàn này.
Giới thiệu project
Bài viết này sẽ về chủ đề Docker và Dockerize một ứng dụng crawl dữ liệu đơn giản sử dụng thư viện Puppeteer. Project chỉ đơn giản là có 1 endpoint API giúp lấy ld-json schema của 1 trang web dựa vào url được truyền vào làm tham số của API này.
Về ld-json schema thì các bạn có thể đọc ở đây.
Vì mới làm quen với chủ đề này nên việc triển khai code sẽ có nhiều thiếu sót nên nếu có vấn đề gì thì mong được mọi người góp ý để mình có thể cải thiện cho bài viết nha.
Okay, bây giờ chúng ta sẽ xem cấu trúc của project có gì?
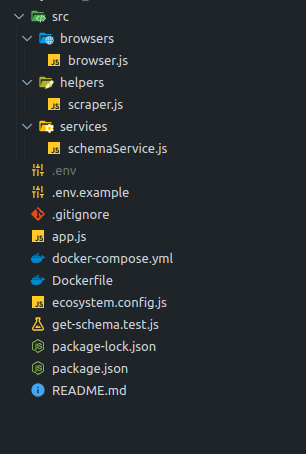
-
Đầu tiên chúng ta có file browser.js sẽ là nơi định nghĩa browser puppeteer bao gồm các giá trị config. Ở đây mình set một số giá trị đơn giản như no-sandbox và proxy-server nếu có:
async function startBrowser(proxyInfo) { let browser; let args = ["--no-sandbox"]; if (proxyInfo && proxyInfo.proxyIp && proxyInfo.proxyPort) { args.push(`--proxy-server=${proxyIp}:${proxyPort}`); } try { console.log("Opening the browser......"); browser = await puppeteer.launch({ headless: true, args, 'ignoreHTTPSErrors': true }); } catch (err) { console.log("Could not create a browser instance => : ", err); } return browser; } -
Tiếp theo chúng ta có 1 helper hỗ trợ crawl các dữ liệu json-schema
const scraper = async (browser, { url, proxyAuth }) => { let page = await browser.newPage(); if (proxyAuth && proxyAuth.username && proxyAuth.password) { await page.authenticate({ username: proxyAuth.username, password: proxyAuth.password }) } console.log(`Navigating to ${url}...`); await page.goto(url); let schemas = await page.$$eval('script[type="application/ld+json"]', links => { links = links.map(el => JSON.parse(el.textContent)); return links; }); return schemas; }Giải thích qua một chút về hàm scraper phía trên, nó sẽ thực hiện lấy tất cả các thẻ script có type là application/ld+json ( Các thẻ này chứa toàn bộ thông tin schema của trang đó). Sau đó chuyển về dạng array of json object và trả về chính chúng.
-
Tiếp theo là SchemaService.js. Service này sẽ thực hiện khởi tạo browser và thực hiện crawl trang web thông qua url được truyền vào. Ngoài ra nếu có thông tin về proxy thì cũng sẽ được xử lý ngay phía trên.
const getSchemas = async ({ url, proxyData }) => { try { let browser; const data = { url } if (proxyData) { const { ip = '', port = '', username = '', password = '' } = await proxyData; browser = await browserObject.startBrowser({ proxyIp: ip, proxyPort: port }); if (username && password) { data['proxyAuth'] = { username, password } } } else { browser = await browserObject.startBrowser(); } const schemas = await scraper(browser, data); await browser.close(); return schemas; } catch (err) { console.log("Error: ", err); } } -
Cuối cùng là file app.js. Để xem chúng ta có gì nhé
require('dotenv').config() const express = require('express'); const schemaService = require('./src/services/schemaService'); const app = express(); const validateApiKey = (req, res, next) => { const apiKey = req.query.api_key; if (!apiKey) { return res.status(400).json({ error: 'api_key parameter is required' }); } const isValidApiKey = apiKey === process.env.API_KEY; if (isValidApiKey) { next(); } else { return res.status(401).json({ error: 'Invalid API key' }); } }; app.get('/extract-schema', validateApiKey, async function (req, res) { const query = req.query const { url, proxy } = query; const schemas = await schemaService.getSchemas({ url, proxyData: proxy }); res.send(schemas); }) app.get('/', async function (req, res) { res.send('Hello this is api server that crawl json-ld schema'); }) const port = process.env.PORT; app.listen(port, () => { console.log("Server Listening on PORT:", port); });
Trông cũng khá đơn giản phải không nào? Okay vậy chúng ta sẽ tiếp tục đi đến phần tiếp theo là Dockerize ứng dụng này nhé.
Dockerize project
- Build image với Node18
- Cùng nhìn qua Dockerfile của mình xem có những gì nào.
FROM node:18 # Install Google Chrome Stable and fonts RUN apt-get update && apt-get install gnupg wget -y && \ wget --quiet --output-document=- https://dl-ssl.google.com/linux/linux_signing_key.pub | gpg --dearmor > /etc/apt/trusted.gpg.d/google-archive.gpg && \ sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list' && \ apt-get update && \ apt-get install google-chrome-stable -y --no-install-recommends && \ rm -rf /var/lib/apt/lists/* WORKDIR /app COPY . . RUN npm install && \ cd ./node_modules/puppeteer && \ npm install CMD ["npm", "start"]- Ở đây chúng ta sẽ xuất phát từ node:18, sau đó cài đặt các libraries cần thiết để chạy được Puppeteer, và cuối cùng là chạy
npm installđể cài các dependencies khác nhé
- Docker Compose
- File docker-compose.yml của mình thì khá đơn giản với chỉ 1 service thôi nên cũng không có gì để giải thích cả 😅. Các bạn chú ý ở đây mình đã dùng 1 biến PORT từ file .env nhé. Các bạn có thể tự định nghĩa giá trị này tùy ý.
version: "3.7" services: app: build: . image: autocrawl/jsonschema ports: - "${PORT}:${PORT}" restart: unless-stopped
Okayyyyy, vậy là tạm xong rồi đấy. Chúng ta bắt đầu thử nghiệm web api của mình nào.
Kết quả
-
Trước khi chạy dự án, các bạn cần định nghĩa 2 giá trị trong file .env là PORT và API_KEY để hệ thống còn biết mà chạy nhé. Ở đây mình sử dụng cổng 8080 và API_KEY random từ trang này nhé.
-
Khởi động dự án
docker compose up -d -
Cùng test thử bằng cách truy cập vào đường dẫn: http://localhost:8080/extract-schema?url=https://us.bebee.com/job/20231023-4984b73f0394f3a333c589ecbf15da25&&api_key=Xo1ROCSbLBGJUf0vLlJuuhxSEbX0pQ9A2ZrS0o2dIskQvL7A3ztn54kUAjjhnqpr. Lưu ý là port và api_key là do các bạn định nghĩa trong file .env nhé.
-
Và đây là kết quả của mình.

- Các bạn có thể tùy ý thay đổi đường link của website cần crawl nhé.
Kết luận
Okay vậy là cuối cùng chúng ta đã hoàn thành 1 ứng dụng crawl đơn giản, cũng khá nhanh phải không nào?
Nếu các bạn có câu hỏi và góp ý gì thì có thể comment trực tiếp dưới bài viết, chúng ta sẽ cùng nhau thảo luận nhé.
Cảm ơn các bạn đã dành thời gian để đọc bài viết của mình. Cheerse 🥂🥂
All rights reserved
