Delta Lake Cơ Bản Với PySpark
Source (en): https://karlchris.github.io/data-engineering/projects/delta-spark/
Lời mở đầu
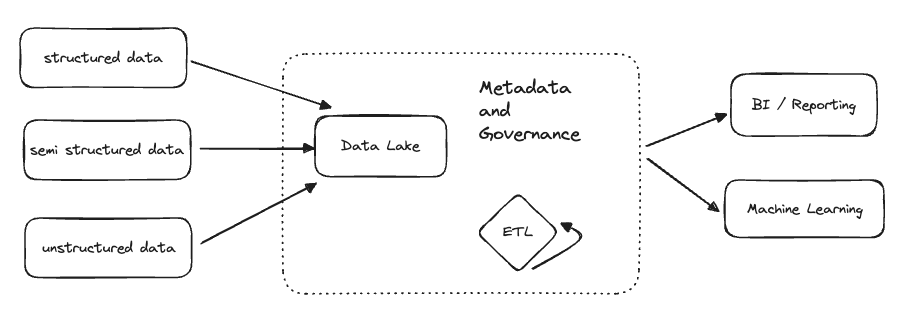
Sau khoảng thời gian dài trong việc quản lý dữ liệu, Data Warehouse vào khả năng lưu trữ data có cấu trúc (structured data) cũng như hỗ trợ truy vấn (query), từ đó data có thể được sử dụng với nhiều mục đích khác như BI, Machine Learning, Data Mining, ...
Cùng với sự gia tăng không ngừng của dữ liệu và nhu cầu sử dụng đống dữ liệu đó, data warehouse dần trở nên "struggled" khi gặp phải dữ liệu bán cấu trúc (semi-structured data) và phi cấu trúc (structured data), dần bộc lộ ra nhiều hạn chế. Từ đó, Data Lake ra đời, cung cấp giải pháp để lưu trữ gần như mọi loại dữ liệu từ có cấu trúc đến phi cấu trúc. Tuy nhiên Data Lake lại thiếu đi khả năng xử lý và truy các dữ liệu có cấu trúc như Data Warehouse.
Gần đây, với sự kết hợp điểm mạnh của cả Data Warehouse và cả Data Lake, cấu trúc Data LakeHouse được ra đời, cung cấp giải pháp lưu trữ linh hoạt như của data lake và hỗ trợ lưu trữ và truy vấn dữ liệu có cấu trúc như của data warehouse.
Giới thiệu về Delta Lake
Delta Lake là một open-source software, hỗ trợ một định dạng table tối ưu cho các data storage. Delta lake tối ưu hiều mặt của các data storage với nhiều tính năng mới và vượt trội như ACID, Time travel, Unified Batch & Streaming, Schema Enforcement & Evolution, ...
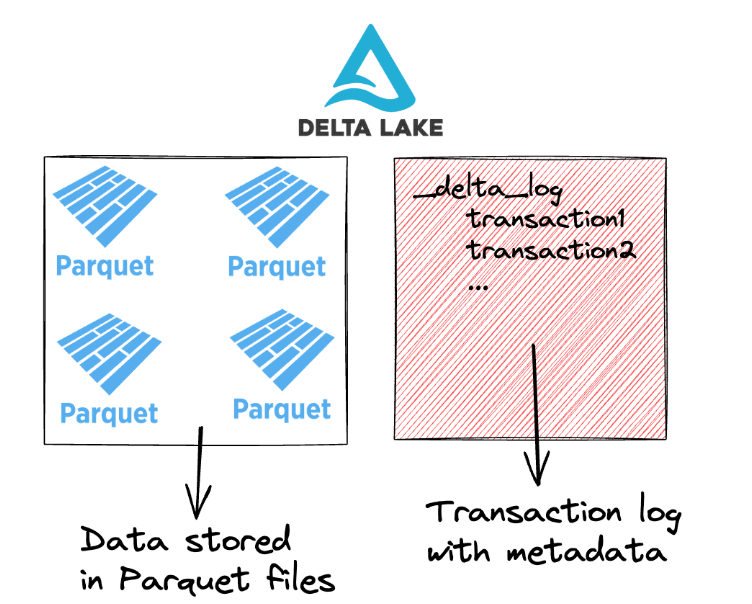
Delta lake sử dụng định dạng .parquet để lưu trữ các file dữ liệu của delta table. Một delta table bao gồm 2 thành phần chính:
- Parquet files chứa các file dữ liệu dưới định dạng
.parquet - Transaction log lưu trữ metadata về các transaction với dữ liệu trong
Delta lake đồng hỗ trợ cả ETL và ETL workloads, tuy nhiên ETL sẽ thích hợp hơn đối với delta lake bởi hiệu năng (Performance) và độ tin cậy (Reliability).
- Performance: các truy vấn được tối ưu nhờ vào
- Lưu trữ file paths và metadata trong Transaction log
- Thực hiện partial read thông qua file-skipping
- Co-locatinng các dữ liệu tương đồng để thực hiện skipping nếu có thể.
Tips: Co-locating similar data: Delta lake lưu các dữ liệu tương đồng ở gần nhau nhằm cải thiện performance thông qua các phương pháp như
Z-OrderinghoặcLiquid Clustering.
- Reliability: Delta lake tối ưu quy trình ETL thông qua việc áp dụng ACID transactions.
Liquid Clustering, Z-ordering and Hive-style partitioning
Cơ bản là đưa các dữ liệu giống nhau lại gần nhau hơn. Liquid Clustering là mới nhất, cũng như tối ưu nhất. ETL workload sẽ được tối ưu từ việc clustering nếu:
- Thường xuyên
filtercác cột - Dữ liệu bị skew nặng
- Dữ liệu gia tăng quá nhanh, cần maintenance và tuning
- Access patternns thay đổi qua thời gian
Query Engine Supported
Delta lake chủ yếu hỗ trợ Apache Spark đặc biệt là trên Databricks, tuy nhiên cũng hỗ trợ một số các loại query engine khác như polars.
Schema evolution & enforcement
Delta hỗ trợ Schema evolution nhằm tránh data bị corruption. Tức là bạn không thể thực hiện write data mới vào một delta table nếu data mới và delta table cũ khác schema. Khi thực hiện write sẽ xảy ra lỗi AnalysisException.
Ví dụ
df = spark.createDataFrame(
[("bob", 47), ("li", 23), ("leonard", 51)])
.toDF("first_name", "age"
)
df.write.format("delta").save("data/toy_data")
Nếu thực hiện write data mới vào với schema khác schema ban đầu:
df = spark.createDataFrame([("frank", 68, "usa"), ("jordana", 26, "brasil")]).toDF(
"first_name", "age", "country"
)
df.write.format("delta").mode("append").save("data/toy_data")
Thì lỗi =))
AnalysisException: [_LEGACY_ERROR_TEMP_DELTA_0007] A schema mismatch detected when writing to the Delta table
Table schema:
root
-- first_name: string (nullable = true)
-- age: long (nullable = true)
Data schema:
root
-- first_name: string (nullable = true)
-- age: long (nullable = true)
-- country: string (nullable = true)
Schema evolution
Tuy nhiên, ETL workload luôn thay đổi theo thời gian, schema của data đương nhiên cũng thay đổi (không có j tồn tại vĩnh viễn), do đó sinh ra Schema evolution. Các định dạng lakehouse hiện đại đều hỗ trợ tính năng này (đặc biệt thằng Iceberg hỗ trợ rẩt mạnh).
Để update schema của delta table cũ theo schema của data mới, khi thực hiện write hãy thêm option mergeSchema thành true
df.write \
.option("mergeSchema", "true") \
.mode("append") \
.format("delta") \
.save("data/toy_data")
Nếu trong ví dụ trên, kết quả thu được kiểu:
spark.read.format("delta").load("data/toy_data").show()
+----------+---+-------+
|first_name|age|country|
+----------+---+-------+
| jordana| 26| brasil| # new
| frank| 68| usa| # new
| leonard| 51| null|
| bob| 47| null|
| li| 23| null|
+----------+---+-------+
Time travel
Du hành thời gian =)), kiểu khi bạn làm cái gì đó lỗi, bạn có thể Ctrl + Z hay rollback lại lúc chưa lỗi. Delta lake có hỗ trợ các delta table tính năng này. Khi lưu data của delta table, trong folder chứa các data file sẽ có một folder tên _delta_log. Folder này lưu lại các transaction log từ các hành động của bạn lên delta table. Từ đó có thể travel lại các trạng thái của delta table.
Tối ưu?
Các file nhỏ khiến việc read trở năng chậm ("the small file problem").
Ví dụ: query từ một delta table với 2m dòng, data được partitioned theo cột education. Ví dụ đầu thì có 1440 files mỗi partition và ví dụ sau chi có 1 per partition.
%%time
df = spark.read.format("delta").load("test/delta_table_1440")
res = df.where(df.education == "10th").collect()
CPU times: user 175 ms, sys: 20.1 ms, total: 195 ms
Wall time: 16.1 s
%%time
df = spark.read.format("delta").load("test/delta_table_1")
res = df.where(df.education == "10th").collect()
CPU times: user 156 ms, sys: 16 ms, total: 172 ms
Wall time: 4.62 s
Khác bọt vcl!
Offline optimize
Giả sử có một luồng ETL stream data vào một delta table đã partitioned và update mỗi phút => 1440 files mỗi partiton at the end of every day.
Có thể manually chạy OPTIMIZE command để optimize số lượng file. Lệnh này sẽ compact các file nhỏ thành file lớn hơn. Default file size trong mỗi partitionn sau khi chạy lệnh này là 1GB.
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, "test/delta_table")
deltaTable.optimize().executeCompaction()
Downstream queries sẽ được tối ưu hơn =))
Optimized Write
Không cần chạy manually, có thể config để chạy automatically.
Optimized Write sẽ combine các file nhỏ trong cùng 1 partition thành cùng 1 file.
Có thể viết option khi lưu như này:
df.write.format("delta").option("optimizeWrite", "True").save("path/to/delta")
Hoặc setting.
- Cho toàn bộ delta table sử dụng table property: delta.autoOptimize.optimizeWrite
- Cho cả Spark session: spark.databricks.delta.optimizeWrite.enabled
Warning: cái này lâu do bị shuffle => không được enables by default.
Auto Compaction
Giải quyết điểm yếu của Optimized Write. Cái này sẽ tối ưu bằng cách tự động chạy một small command optimize sau mỗi lệnh write
Setting:
- Cho toàn bộ delta table sử dụng table property: delta.autoOptimize.autoCompact
- Cho cả Spark session: spark.databricks.delta.autoCompact.enabled
Vacuum
Vì Auto Compaction tối ưu sau mỗi write operation, các file nhỏ có thể vẫn tồn tại
> # get n files per partition
> !ls delta/census_table_compact/education\=10th/*.parquet | wc -l
1441
1440 files nhỏ (cũ) và 1 file to (mới - sau Auto Compatio) trong 1 partition. Tuy không ảnh hưởng đến hiệu năng của việc read, tuy nhiên nếu muốn loại bỏ thì dùng VACUUM với parameter là thời gian (giờ) preserve.
deltaTable.vacuum(0)
Lệnh này sẽ remove các files mà không còn được actively reference trong Transaction log. Lệnh VACUUM mặc định sẽ chỉ ảnh hưởng đến các file đã tồn tại lâu hơn retention duration (mặc định là 7 ngày). Setting về retention duration có thể overide bằng cácc
spark.sql("SET spark.databricks.delta.retentionDurationCheck.enabled=false")
Change Data Feed - Change Data Capture (CDC)
Cơ bản là Change Data Capture, on top of Delta lake, create by Databricks
CDF cho phép Databricks track row-level channge giữa các versionn của Delta table. Khi được enable trong một Delta table, runtime sẽ record sự thay đổi của mọi data được write vào table. Nó bao gồm record mới được insert / update / delete cùng với metadata biểu thị rằng cái record đó được insert, update hay delete.
CREATE TABLE <table_name> ()
USING DELTA
PARTITION BY (col)
TBLPROPERTIES (delta.enableChangeDataFeed = true)
LOCATION 'path/to/table'
Databricks khuyến khích nên sử dụng CDF với Structured Streaming để incrementally process thay đổi từ các Delta table.
def read_cdc_by_table_name(starting_version):
return spark.read.format("delta") \
.option("readChangeFeed", "true") \
.option("startingVersion", str(starting_version)) \
.table("<table_name>") \
.orderBy("_change_type", "id")
def stream_cdc_by_table_name(starting_version):
return spark.readStream.format("delta") \
.option("readChangeFeed", "true") \
.option("startingVersion", str(starting_version)) \
.table("<table_name>") \
.writeStream \
.format("console") \
.option("numRows", 1000) \
.start()
Lời kết
Ngoài thằng này ra còn các định dạng Lakehouse khác như Hudi, Iceberg, XTable (thằng này đang phát triển)...
Reference
All rights reserved
