DBT là gì? Mấy thứ nhỏ nhặt mình lụm lặt về DBT
Bài đăng này đã không được cập nhật trong 3 năm
Mọi thông tin chỉ mang tính chất tham khảo , tại em mới tập tành làm thôi ạ  ((
((
DBT LÀ GÌ ?
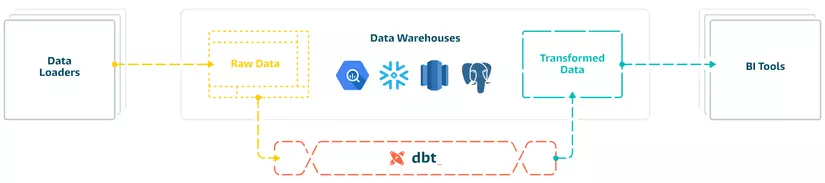
DBT là viết tắt cho Data Build Tool , là công cụ hỗ trợ quá trình transform data trở nên nhanh và trở nên dễ dàng hơn .
Tại sao lại là DBT?
Một vài câu hỏi mà chúng ta thường gặp là
- Vì sao lại phải sử dụng DBT, tụi teo đang xài SQL ngon lành phở mà ?
- hay là Ủa? sao kỳ dị? đang quen thuộc với SQL tự dưng cái phải học thêm DBT ha?
Thì dị nè , nhìn cái tên mình cũng thấy sương sương đó , DBT được thiết kế để giải quyết phần T trong ELT , nó sẽ làm với raw data trong quá trình Transform. DBT cung cấp ít chức năng trong quá trình transform hơn các cái OSS(open-source) ETL tool khác như Airflow, Luigi,... Bù lại nó được cái là dễ hỉu, dễ xài cho mấy má non-engineer.
Nguồn: copy
Mấy năm gần đây thì DW nó mạnh mẽ và linh hoạt, nó có thể tách biệt phần lưu trữ và phần xử lý, elastic scale (kiểu linh hoạt trong việc scale ) và áp dụng Machine Learning. Xong cái nhiều công ty xài , mà nhiều công ty xài dẫn tới nhu cầu , càng dễ xài càng tốt
Nói chung về lợi ích thì kha khá, chủ yếu là dễ học, dễ xài, dễ dàng sử dụng lại (dễ dàng chuyển đổi giữa các loại sql với nhau , dí dụ đang xài SQL , cái muốn đổi sang bigquery thì cũng k mất nhiều công sức), đơn giản hóa cái việc coding của mình( dí dụ như sql cần create table , insert data into table đó thì dbt chỉ cần viết select là nó tự tạo model, tự insert )
Mấy cái xịn xò hơn thì như dependency( kiểu sắp xếp table nào chạy rùi tới table nào chạy chẳng hạn ) hay là tự tạo document , xài jinja template , version control hay cho phép kiểm tra chất lượng dữ liệu đầu vào( đại khái là kiểm tra xem raw đúng chưa , raw như nào, test data đó ) gòi hỗ trợ vài automation test case...
Cấu trúc của DBT
Chời má, mỗi lần ngồi đọc mấy cái document là mệt xỉu , còn không hình dung được nó như nào nên phải take note ra nè mấy má
Thì tùy mấy má tổ chức folder như nào thui , cơ mà trên cơ bản nó dị:

Nguồn: copy
Cấu trúc nó sẽ là :
-
1 folder (tên qq dì cũng được , tên project mình chẳng hạn)
-
- folder analyses: folder này chứa mấy script sql mà analytic cần á, cơ mà nó chỉ compile chứ k có excute
Theo như mìn thì tác dụng lớn nhất của nó là ò , teo có cái model sql đó , cơ mà nó xài jinja template ( mấy cái {{ table.name}} dị nè) rùi sao teo biết là code teo viết ra sql như naò chẳng hạn , thì bỏ cái script đó dô folder này nó sẽ generate ra format sql vào 1 cái folder gọi là target-> analyse 9 (dô đó check code chạy). Rùi đó thỉnh thoảng m cần phân tích khác chút xíu so với model , thêm cột , hay sửa metric dì chẳng hạn , script chạy 1 ,2 lần mà cái sửa model thì k được, viết lại thì mắc công , bỏ dô đây, bỏ dô đây generate code cho lẹ nha má
- folder analyses: folder này chứa mấy script sql mà analytic cần á, cơ mà nó chỉ compile chứ k có excute
-
- folder macro: này quan trọng ,này quan trọng , này quan trọng, điều quan trọng nhắc lại 3 lần
Thì nãy có nói đó , ưu điểm nó là dễ sử dụng lại , dị sử dụng lại sao , thì chỗ này nó làm nè
Folder này sẽ chứa toàn bộ macro của project , macro thì như sql hiểu là mấy cái store procedure hay là mấy cái function á. Viết lần gọi chục lần. Macro thì nó nhiều tính năng lắm, mình thấy team mình dùng macro để tiện convert giữa các SQL khác nhau thấy cũng hay ho( chủ yếu là do mình k nắm được Jinja nhiều, ai hứng thú thì tìm hiểu thêm nhe
- folder macro: này quan trọng ,này quan trọng , này quan trọng, điều quan trọng nhắc lại 3 lần
-
- folder models: macro quan trọng thì naỳ đặc biệt quan trọng, 1 project có thể thiếu tất cả folder khác nhưng k thể thiếu folder này
Dì sao ư? dì cái này tạo model chớ sao nữa, hong có model, hong có data rùi lấy cái dì xử lý . Trong này chứa mấy file .sql mà 1 file là 1 models( có thể là bảng, bảng tạm ,..) chạy cái này thì nó generate model + insert data cho mình nè.
- folder models: macro quan trọng thì naỳ đặc biệt quan trọng, 1 project có thể thiếu tất cả folder khác nhưng k thể thiếu folder này
-
- folder seeds: folder này chứa mấy file csv. mỗi file csv khi chạy thì tạo thành 1 table á. Này để mình import data từ file dô table đỡ lằng nhằng hơn nè
- folder seeds: folder này chứa mấy file csv. mỗi file csv khi chạy thì tạo thành 1 table á. Này để mình import data từ file dô table đỡ lằng nhằng hơn nè
-
- folder snapshots: nghe đồn nó để snapshot data của một table tại 1 thời điểm nào đó , này chưa xài chưa biết ạ.
-
- folder tests: chòi má, tác dụng y như tên, viết test cái dì thì quăng dô đây, chạy nó sẽ test hộ cho, thường thì mình viết unit test mấy cái hàm nè , fake data test cho mấy table nè
-
- gitignore: ai xài git thì biết he , cái dì k muốn push lên git thì quăng đây
-
- dbt_project.yml : này quan trọng nè , má nói hồi cái dì cũng quan trọng chơn, cơ mà này k phải là folder, này là file =))
Thì tại bất cứ cái dbt project nào cũng có nó mới chạy được. Trong này chứ mấy cái mô tả về project như là tên , version , xài những biến nào ( global variable : kiểu dị á ) , xong chứa những folder dì , config các kiểu ...
- dbt_project.yml : này quan trọng nè , má nói hồi cái dì cũng quan trọng chơn, cơ mà này k phải là folder, này là file =))
-
- readme.md : này thì chỗ viết doc, chỗ đầu tiên phải đọc khi đọc source nào, biết đâu dễ hỉu hơn .
DBT hoạt động như nào ?
Mấy cái ở trên chỉ là khái niệm về dbt thôi, để mà trong 1 dự án nó chạy được thì làm như nào .
Demo thì mình thấy kha khá trang có viết rồi , kiểu , test như nào , tạo model như nào, macro như nào...
Tới khúc này thì mình chỉ giải thích một xíu thui, tại lười viết , mấy bạn mà tìm hiểu DBT có thể đọc link này : https://www.startdataengineering.com/post/dbt-data-build-tool-tutorial/#2-dbt-the-t-in-elt
Bình thường cái luồng của mình là dị đúng khum : Mình có data source => tranform => đổ vào destination , thì DBT nó làm cái transform đó, vậy nó lấy source từ đâu , lấy như nào , thì nó cần connect tới 1 cái database để nó lấy .
Mọi thứ sẽ được định nghĩa trong files profile.yml, file này nó tạo cái connection để mình connect tới DW , lấy data và import data .
Còn mà để DBT nó chạy được thì mình có thể dùng airflow hay mấy cái tool trigger nó chạy hoy .
Gòi có sample không ?
Có nhưng mà mình lười viết nên để bài sau dị
All rights reserved
