DataFrames trong Apache Spark
Bài đăng này đã không được cập nhật trong 2 năm
DataFrames là một khái niệm quan trọng trong Apache Spark, cung cấp một cách linh hoạt và hiệu quả để làm việc với dữ liệu dưới dạng bảng có cấu trúc, tương tự như trong cơ sở dữ liệu quan hệ.
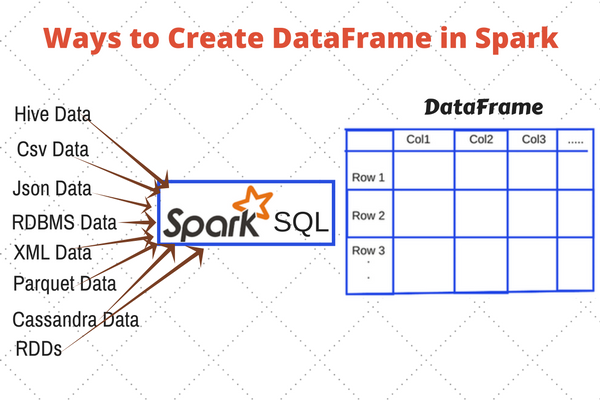
Dưới đây là một số điểm cần hiểu rõ về DataFrames:
1. Bảng dữ liệu có cấu trúc:
DataFrames được tổ chức dưới dạng các hàng và cột, tương tự như các bảng trong cơ sở dữ liệu quan hệ. Mỗi cột trong DataFrame có một tên và một kiểu dữ liệu, giúp cho việc thực hiện các thao tác truy vấn và biến đổi dữ liệu dễ dàng hơn.

2. API dễ sử dụng:
Apache Spark cung cấp một API dễ sử dụng cho việc làm việc với DataFrames. API này hỗ trợ nhiều ngôn ngữ lập trình như Scala, Java, Python và R, giúp cho các nhà phát triển có thể làm việc với DataFrames trong môi trường phát triển mà họ thoải mái nhất.
Dưới đây là một ví dụ cụ thể về cách sử dụng API dễ sử dụng của DataFrames trong Apache Spark bằng Python:
# Import thư viện và modules cần thiết
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
# Khởi tạo một phiên SparkSession
spark = SparkSession.builder \
.appName("Example DataFrame API") \
.getOrCreate()
# Đọc dữ liệu từ một tệp CSV vào DataFrame
df = spark.read.csv("data.csv", header=True, inferSchema=True)
# Hiển thị cấu trúc của DataFrame
df.printSchema()
# Hiển thị 5 hàng đầu tiên của DataFrame
df.show(5)
# Thực hiện một số phép biến đổi và truy vấn trên DataFrame
# Ví dụ: Lọc các hàng có giá trị 'age' lớn hơn 30
filtered_df = df.filter(col("age") > 30)
# Hiển thị 5 hàng đầu tiên của DataFrame sau khi lọc
filtered_df.show(5)
# Tính tổng của cột 'salary'
total_salary = df.selectExpr("sum(salary)").collect()[0][0]
print("Tổng lương của tất cả nhân viên:", total_salary)
# Ghi DataFrame vào một tệp Parquet
df.write.parquet("output.parquet")
# Đóng phiên SparkSession
spark.stop()
Trong ví dụ này, chúng ta sử dụng API của DataFrames trong Apache Spark để thực hiện các thao tác sau:
- Đọc dữ liệu từ một tệp CSV vào DataFrame.
- In ra cấu trúc của DataFrame và hiển thị 5 hàng đầu tiên.
- Lọc các hàng có giá trị cột 'age' lớn hơn 30.
- Tính tổng của cột 'salary'.
- Ghi DataFrame vào một tệp Parquet.
- Đóng phiên SparkSession.
Các hàm và phương thức trong API của DataFrames như filter, selectExpr, collect, write,... cho phép bạn thực hiện các thao tác truy vấn và biến đổi dữ liệu một cách dễ dàng và linh hoạt. Điều này làm cho việc làm việc với DataFrames trong Apache Spark trở nên đơn giản và hiệu quả.
3. Tối ưu hóa hiệu suất:
DataFrames được tối ưu hóa để tận dụng các tính năng in-memory của Apache Spark, giảm thiểu việc truy cập dữ liệu từ đĩa và tối ưu hóa việc chuyển đổi dữ liệu giữa các phần của DataFrame trên cụm. Điều này giúp tăng tốc độ xử lý dữ liệu và cải thiện hiệu suất của ứng dụng của bạn.
Để minh họa về tối ưu hóa hiệu suất của DataFrames trong Apache Spark, hãy xem xét một ví dụ cụ thể:
Giả sử bạn có một tập dữ liệu lớn chứa thông tin về các đơn đặt hàng từ một trang web thương mại điện tử. Tập dữ liệu này có hàng triệu hàng đơn với các trường như ID đơn hàng, ID khách hàng, ngày đặt hàng, tổng số tiền, v.v.
Bạn muốn tính toán tổng số tiền mà mỗi khách hàng đã chi tiêu trong một khoảng thời gian nhất định. Bạn có thể sử dụng DataFrames của Apache Spark để thực hiện phân tích này một cách dễ dàng và hiệu quả.
Dưới đây là một ví dụ về cách bạn có thể sử dụng DataFrame để thực hiện tính toán này và cách Apache Spark tối ưu hóa hiệu suất:
from pyspark.sql import SparkSession
from pyspark.sql.functions import sum
# Khởi tạo SparkSession
spark = SparkSession.builder \
.appName("CalculateTotalSpent") \
.getOrCreate()
# Đọc dữ liệu từ tập tin CSV thành DataFrame
orders_df = spark.read.csv("orders.csv", header=True, inferSchema=True)
# Lọc các đơn đặt hàng trong khoảng thời gian nhất định
filtered_orders_df = orders_df.filter((orders_df.order_date >= '2024-01-01') & (orders_df.order_date <= '2024-06-01'))
# Tính tổng số tiền chi tiêu của mỗi khách hàng
total_spent_per_customer = filtered_orders_df.groupBy("customer_id").agg(sum("total_amount").alias("total_spent"))
# Hiển thị kết quả
total_spent_per_customer.show()
# Dừng SparkSession
spark.stop()
Trong ví dụ này:
Đầu tiên, chúng ta khởi tạo một
SparkSession, là một điểm nhập cho việc làm việc với dữ liệu của chúng ta trong Apache Spark.Tiếp theo, chúng ta đọc dữ liệu từ tập tin CSV vào DataFrame sử dụng phương thức
read.csv().Sau đó, chúng ta lọc các đơn đặt hàng trong khoảng thời gian nhất định bằng cách sử dụng phương thức
filter().Chúng ta sử dụng phương thức
groupBy()để nhóm các đơn đặt hàng theocustomer_idvà sử dụng hàm tổngsum()để tính tổng số tiền chi tiêu của mỗi khách hàng.Cuối cùng, chúng ta hiển thị kết quả bằng phương thức
show()và dừngSparkSession.
Apache Spark tối ưu hóa hiệu suất bằng cách thực hiện các phép tính một cách song song trên các partition của dữ liệu và tận dụng tính năng in-memory của nó. Điều này giúp cho việc xử lý dữ liệu lớn trở nên nhanh chóng và hiệu quả.
4. Hỗ trợ đa ngôn ngữ:
DataFrames hỗ trợ làm việc với dữ liệu bằng nhiều ngôn ngữ lập trình khác nhau, cho phép bạn sử dụng ngôn ngữ phù hợp nhất với nhu cầu của mình. Điều này làm cho việc phát triển và triển khai các ứng dụng Spark trở nên dễ dàng và linh hoạt hơn.
Dưới đây là một ví dụ cụ thể về cách Apache Spark hỗ trợ đa ngôn ngữ:
Giả sử bạn đang làm việc trên một dự án phân tích dữ liệu sử dụng Apache Spark và bạn đã chọn Python làm ngôn ngữ chính để phát triển ứng dụng của mình.
- Đọc dữ liệu từ tệp CSV và xử lý dữ liệu bằng Python:
# Import SparkSession từ gói pyspark.sql
from pyspark.sql import SparkSession
# Khởi tạo SparkSession
spark = SparkSession.builder \
.appName("example") \
.getOrCreate()
# Đọc dữ liệu từ tệp CSV vào DataFrame
df = spark.read.csv("data.csv", header=True, inferSchema=True)
# Hiển thị 10 hàng đầu tiên của DataFrame
df.show(10)
# Thực hiện xử lý dữ liệu bằng Python
result_df = df.filter(df['age'] > 30).select(df['name'], df['age'])
# Hiển thị kết quả
result_df.show()
- Sử dụng SQL trong Python để truy vấn dữ liệu:
# Tạo view tạm thời từ DataFrame
df.createOrReplaceTempView("people")
# Thực hiện truy vấn SQL trên DataFrame
result_sql = spark.sql("SELECT name, age FROM people WHERE age > 30")
# Hiển thị kết quả
result_sql.show()
- Làm việc với RDDs bằng Scala:
// Import SparkSession từ gói org.apache.spark.sql
import org.apache.spark.sql.SparkSession
// Khởi tạo SparkSession
val spark = SparkSession.builder
.appName("example")
.getOrCreate()
// Đọc dữ liệu từ tệp CSV vào RDD
val rdd = spark.sparkContext.textFile("data.csv")
// Xử lý RDD bằng Scala
val filteredRdd = rdd.filter(line => line.split(",")(1).toInt > 30)
// Hiển thị kết quả
filteredRdd.take(10).foreach(println)
Như bạn có thể thấy, Apache Spark cho phép bạn làm việc với dữ liệu sử dụng nhiều ngôn ngữ lập trình khác nhau như Python và Scala trong một dự án. Điều này làm cho việc phát triển và triển khai ứng dụng Spark trở nên linh hoạt và thuận tiện hơn, đồng thời tận dụng được sức mạnh của các ngôn ngữ lập trình phổ biến.
5. Tích hợp với các công cụ phân tích dữ liệu:
DataFrames được tích hợp chặt chẽ với các công cụ phân tích dữ liệu khác trong hệ sinh thái Spark như Spark SQL, MLlib và GraphX. Điều này cho phép bạn thực hiện các công việc phức tạp như truy vấn dữ liệu, xây dựng và huấn luyện các mô hình machine learning trên dữ liệu của mình một cách dễ dàng và linh hoạt.
Dưới đây là một ví dụ cụ thể về cách DataFrames được tích hợp với các công cụ phân tích dữ liệu khác trong hệ sinh thái Apache Spark:
Ví dụ: Xử lý dữ liệu bán lẻ với DataFrames và Spark SQL
Giả sử bạn có một tập dữ liệu lớn về bán lẻ chứa thông tin về các giao dịch mua sắm, bao gồm thông tin về sản phẩm, khách hàng, và doanh số bán hàng. Bạn muốn phân tích dữ liệu này để hiểu rõ hơn về hành vi mua sắm của khách hàng và các xu hướng bán hàng.
Đầu tiên, bạn có thể sử dụng Apache Spark để nạp dữ liệu từ tệp CSV hoặc cơ sở dữ liệu vào một DataFrame:
from pyspark.sql import SparkSession
# Khởi tạo SparkSession
spark = SparkSession.builder \
.appName("Retail Analysis") \
.getOrCreate()
# Nạp dữ liệu từ tệp CSV vào DataFrame
df = spark.read.csv("path/to/retail_data.csv", header=True, inferSchema=True)
Sau đó, bạn có thể sử dụng Spark SQL để thực hiện các truy vấn phức tạp trên DataFrame để trả lời các câu hỏi phân tích dữ liệu:
# Tạo view tạm thời từ DataFrame
df.createOrReplaceTempView("retail_data")
# Truy vấn thông tin về doanh số bán hàng theo sản phẩm
sales_by_product = spark.sql("""
SELECT product_id, SUM(sales_amount) AS total_sales
FROM retail_data
GROUP BY product_id
ORDER BY total_sales DESC
""")
sales_by_product.show()
Ngoài ra, bạn có thể sử dụng DataFrames để chuẩn bị dữ liệu cho việc xây dựng mô hình machine learning, ví dụ như dự đoán doanh số bán hàng trong tương lai dựa trên các yếu tố như giá cả, quảng cáo, và thời gian:
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression
# Tạo một VectorAssembler để biến đổi các đặc trưng thành một vector
assembler = VectorAssembler(inputCols=["price", "advertising", "time"], outputCol="features")
data = assembler.transform(df)
# Chia dữ liệu thành tập huấn luyện và tập kiểm tra
train_data, test_data = data.randomSplit([0.8, 0.2])
# Xây dựng mô hình hồi quy tuyến tính
lr = LinearRegression(featuresCol="features", labelCol="sales_amount")
model = lr.fit(train_data)
# Đánh giá mô hình trên tập kiểm tra
predictions = model.transform(test_data)
Trong ví dụ này, chúng ta sử dụng DataFrames và Spark SQL để thực hiện phân tích dữ liệu và sử dụng dữ liệu được xử lý để xây dựng một mô hình hồi quy tuyến tính để dự đoán doanh số bán hàng. Điều này thể hiện cách DataFrames được tích hợp chặt chẽ với các công cụ phân tích dữ liệu khác trong hệ sinh thái Apache Spark để giúp bạn thực hiện các tác vụ phức tạp trong lĩnh vực Big Data.
Tóm lại, DataFrames là một khái niệm quan trọng trong Apache Spark, cung cấp một cách linh hoạt và hiệu quả để làm việc với dữ liệu dưới dạng bảng có cấu trúc, giúp cho việc xử lý và phân tích dữ liệu trở nên dễ dàng hơn trong lĩnh vực Big Data.
All rights reserved
