Data Encoding & Decoding
I. Mở đầu
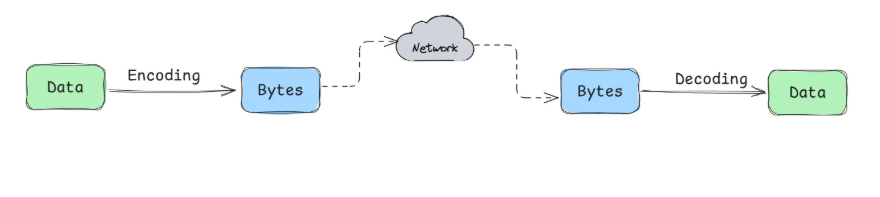
Các chương trình hoặc ứng dụng máy tính thường làm việc với dữ liệu ở (ít nhất) 2 hình thức khác nhau:
- Trong bộ nhớ (in-memory), dữ liệu được lưu trữ dưới các cấu trúc dữ liệu như objects, structs, array, hash tables, trees,… Các loại cấu trúc dữ liệu này được CPU tối ưu cho việc truy cập và sửa đổi.
- Khi truyền tải dữ liệu, ví dụ như client-server hoặc service-to-service, các thao tác sẽ được thực thi qua network-call. Khi đó, dữ liệu cần được chuyển đổi về một chuỗi bytes - khác rất nhiều so với các cấu trúc dữ liệu được lưu trữ trong bộ nhớ.
Do đó, chúng ta cần một thao tác trung gian để chuyển đổi các dữ liệu lưu trữ trong bộ nhớ về dạng bytes. Thao tác đó được gọi là Encoding hay Serialization và thao tác đảo ngược của nó được gọi là Decoding hoặc Deserialization.
II. Các vấn đề về ngôn ngữ
Các ngôn ngữ thường sẽ cung cấp các built-in để phục vụ việc Encoding/Decoding dữ liệu. Ví dụ như Java sử dụng java.io.Serializable hay Python với pickle. Đồng thời, có nhiều thư viện bên thứ ba cũng hỗ trợ Encoding/Decoding.
Điều này rất tiện, vì các thư viện sẽ cho phép ta viết mã một cách hiệu quả mà không tốn nhiều công sức. Tuy nhiên, chúng cũng có một số điểm đáng lưu ý
- Phụ thuộc ngôn ngữ: Encoding/Decoding gán chặt với ngôn ngữ lập trình. Vì vậy, dữ liệu khó đọc hoặc tái sử dụng ở ngôn ngữ khác, dẫn đến hệ thống bị phụ thuộc vào công nghệ.
- Nguy cơ bảo mật: Khi quá trình decoding diễn ra, ứng dụng phải khởi tạo lại các lớp (class) từ dữ liệu nhận được. Nếu kẻ tấn công gửi vào dữ liệu độc hại, chúng có thể ép ứng dụng tạo ra lớp nguy hiểm và thực thi mã từ xa.
- Phiên bản: Các thư viện thường bỏ qua vấn đề quản lý phiên bản. Khi thay đổi cấu trúc dữ liệu, rất khó duy trì tính tương thích giữa các phiên bản cũ và mới.
- Hiệu năng & dung lượng: Việc Encoding/Decoding thường sẽ chậm và kích thước dữ liệu tạo ra thường không tối ưu. Ví dụ như Serializable của Java bị coi là chậm và tạo nhiều dữ liệu dư thừa.
Vì những nhược điểm đã nêu không nên dùng cơ chế Encoding/Decoding có sẵn của ngôn ngữ cho các mục đích trao đổi dữ liệu lâu dài. Nó chỉ phù hợp để dùng tạm thời trong nội bộ (ví dụ cache ngắn hạn, truyền trong cùng tiến trình) chứ không thích hợp cho giao tiếp giữa các hệ thống.
III. XML, JSON vs Protocol Buffers
Trong việc truyền tải dữ liệu trong hệ thống phân tán, lựa chọn định dạng dữ liệu là một quyết định then chốt. XML và JSON đại diện cho các chuẩn văn bản lâu đời, dễ tiếp cận và có tính liên thông cao, song thường bị phê phán vì hiệu năng thấp và cấu trúc dư thừa. Trái lại, Protocol Buffers, với đặc trưng nhị phân và dựa trên schema, mang lại ưu thế rõ rệt về tốc độ, kích thước gói tin và khả năng duy trì tương thích qua các phiên bản.
1. JSON vs XML
JSON và XML là 2 định dạng phổ biến trong việc truyền tải dữ liệu. Cả 2 đều là text-based format với một cộng đồng hỗ trợ lớn và tương đối dễ đọc. Tuy nhiên cả 2 định dạng này đều có những hạn chế cần lưu ý.
Vấn đề xử lý chuỗi nhị phân
XML và JSON đều không hỗ trợ truyền tải các chuỗi bytes - dãy nhị phân. Chúng ta giải quyết vấn đề đó bằng việc chuyển đổi các dữ liệu dạng nhị phân (ảnh, video, file…) thành một chuỗi Base64.
{
"image": "iVBORw0KGgoAAAANSUhEUgAA..."
}
// Dummy client
RestTemplate restTemplate = new RestTemplate();
Map response = restTemplate
.getForObject("http://localhost:8080/api/images/img1.png", Map.class);
String base64Image = (String) response.get("image");
// Decode theo schema (binary)
byte[] imageBytes = Base64.getDecoder().decode(base64Image);
// Save to file
Files.write(Paths.get("downloaded.png"), imageBytes);
Khi đó, đầu nhận sẽ phải tự chuyển đổi dữ liệu về đúng định dạng. Cách này hoạt động tốt nhưng sẽ khiến kích thước dữ liệu truyền tải tăng lên 33%.
Vấn đề về Schema
Cả XML và JSON đều hỗ trợ schema nhưng không bắt buộc. Áp dụng schema đồng nghĩa mọi dữ liệu qua quá trình truyền tải đều phụ thuộc vào schema được định nghĩa sẵn (number, string, …). Các schema có vai trò quan trọng vì nó giúp định nghĩa rõ ràng kiểu dữ liệu và ràng buộc các trường, từ đó tránh việc diễn giải sai, chẳng hạn một giá trị có thể bị hiểu là chuỗi thay vì số. Nếu không dùng schema, ứng dụng phải tự viết logic để kiểm tra và ép kiểu, điều này làm tăng độ phức tạp và dễ gây lỗi khi trao đổi dữ liệu giữa các hệ thống. Tuy nhiên, việc áp dụng schema cũng có những hạn chế vì chúng khá phức tạp và khó học (đặc biệt là XML Schema). Điều này cũng làm giảm tính linh hoạt vì chỉ một thay đổi nhỏ trong dữ liệu cũng đòi hỏi phải cập nhật schema. Đồng thời còn gây tốn kém hiệu năng vì khi encoding hệ thống cần thêm thao tác kiểm tra cấu trúc.
Mặc dù vẫn tồn tại một số vấn đề, nhưng XML và JSON vẫn được sử dụng rộng rãi đặc biệt trong mô hình giao tiếp client-server hay các service phục vụ mục đích tích hợp do độ phổ biến và cấu trúc dễ đọc cùng cộng đồng hỗ trợ lớn.
2. Binary encoding
Nếu dữ liệu chỉ cần truyền tải nội bộ hệ thống (service-to-service) thì ta nên ưu tiên sử dụng các định dạng tối ưu hơn cho việc truyền tải. Khi đó hệ thống sẽ tiết kiệm tài nguyên hơn khi thực hiện việc Encoding/Decoding và hiệu năng cũng sẽ được cải thiện.
Với dữ liệu nhỏ, việc chọn định dạng không phải vấn đề quá lớn. Tuy nhiên, khi dữ liệu truyền tải lên đến hàng TB thì việc chọn đúng định dạng truyền tải sẽ ảnh hưởng lớn đến hệ thống
Cả 2 định dạng là JSON và XML đều có kích thước lớn hơn nếu so với định dạng nhị phân (binary) dẫn đến việc encoding sẽ kém hiệu quả hơn do hệ thống phải xử lý nhiều dữ liệu hơn.
Điều này đã dẫn đến sự phát triển của một loạt các dạng biến thể của JSON (ví dụ: MessagePack, BSON, UBJSON, BISON và Smile) và XML (ví dụ: WBXML và Fast Infoset). Những định dạng này đã được áp dụng trong một số bài toán cụ thể, nhưng không định dạng nào được sử dụng rộng rãi như JSON và XML.
Các định dạng này mở rộng tập hợp các kiểu dữ liệu nhưng về cơ bản vẫn giữ nguyên mô hình dữ liệu của JSON/XML. Cụ thể, vì chúng không quy định một schema, nên chúng cần bao gồm tất cả các tên trường trong đối tượng bên trong dữ liệu được truyền tải.
Ví dụ với MessagePack
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
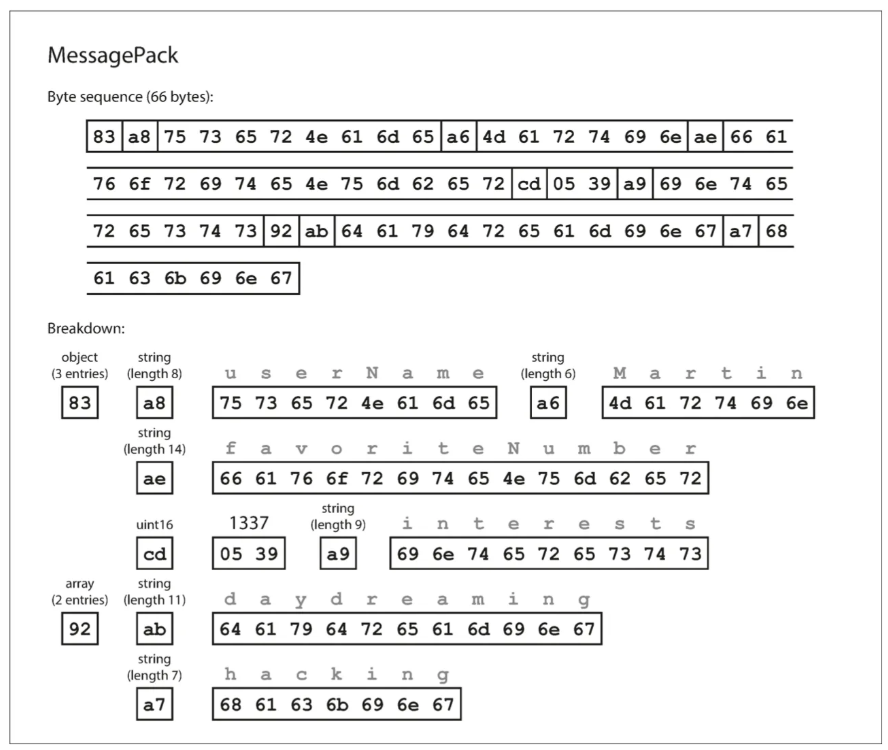
- Byte đầu tiên (0x83): Cho biết phần tiếp theo là một đối tượng. Bốn bit cao nhất (0x80) xác định kiểu dữ liệu là “object”, còn bốn bit thấp nhất (0x03) cho biết đối tượng có 3 trường. Nếu đối tượng có hơn 15 trường (không thể biểu diễn bằng 4 bit) thì sẽ dùng một mã loại khác và số trường được mã hóa trong 2 hoặc 4 byte.
- Byte thứ hai (0xa8): Cho biết phần tiếp theo là một chuỗi. Bốn bit cao nhất (0xa0) xác định kiểu dữ liệu là “string”, còn bốn bit thấp nhất (0x08) cho biết chuỗi này dài 8 byte.
- Tám byte tiếp theo: Đây là tên trường userName ở dạng ASCII. Vì độ dài chuỗi đã được xác định từ trước nên không cần ký hiệu kết thúc hoặc ký hiệu thoát để đánh dấu điểm dừng.
- Bảy byte kế tiếp: Mã hóa giá trị chuỗi Martin (gồm 6 ký tự) với một tiền tố xác định độ dài, và tiếp tục theo cách tương tự cho các trường khác.
Chuỗi byte này có độ dài 66 byte, ít hơn một chút so với 81 byte của thao tác encoding JSON dạng văn bản (khi loại bỏ khoảng trắng).
Bảng tham chiếu MessagePack
| Prefix (hex) | Tên gọi | Ý nghĩa |
|---|---|---|
| 0x00 – 0x7f | positive fixint | Số nguyên không âm (0–127) |
| 0x80 – 0x8f | fixmap | Map (object), số cặp key–value = 4 bit thấp (0–15) |
| 0x90 – 0x9f | fixarray | Array, số phần tử = 4 bit thấp (0–15) |
| 0xa0 – 0xbf | fixstr | Chuỗi, độ dài = 5 bit thấp (0–31) |
| 0xc0 | nil | Null |
| 0xc2 | false | Boolean false |
| 0xc3 | true | Boolean true |
| 0xda | str16 | Chuỗi có độ dài (2 byte length prefix) |
| 0xdd | array32 | Array có độ dài (4 byte length prefix) |
| 0xdf | map32 | Map có độ dài (4 byte length prefix) |
| 0xe0 – 0xff | negative fixint | Số nguyên âm (-32 đến -1) |
3. Thrift & Protocol Buffers
Thrift và Protocol Buffers (protobuf) là 2 dạng binary-based format có tư tưởng và cách tiếp cận giống nhau trong việc encoding dữ liệu. Cả 2 định dạng này đều bắt buộc có schema để định nghĩa cấu trúc dữ liệu khi truyền tải. Đây cũng là 2 open-source được hậu thuẫn từ các công ty lớn. Cụ thể là Google (Protocol Buffers) và Facebook (Thrift).
Dưới đây là ví dụ schema của 2 định dạng trên.
- Với Thrift
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}
- Với Protocol Buffers
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3
}
Với Thrift, dữ liệu sẽ được encoding theo 2 định dạng là BinaryProtocol và CompactProtocol
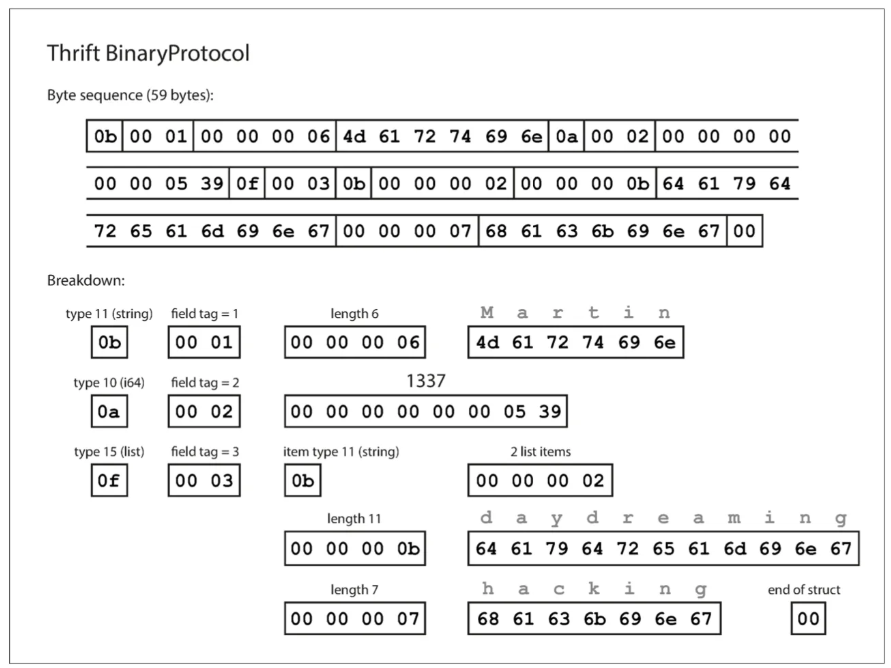
Giống như MessagePack, mỗi trường có một giá trị mô tả kiểu dữ liệu (chuỗi, số nguyên, mảng, ..) và một mô tả về độ dài của chuỗi hoặc số phần tử trong một mảng.
Các chuỗi xuất hiện trong dữ liệu (“Martin”, “daydreaming”, “hacking”) cũng được chuyển đổi dưới dạng ASCII (hoặc chính xác hơn là UTF-8). Điểm khác biệt lớn so MessagePack là không có tên trường (“favoriteNumber”, “interests”). Thay vào đó, dữ liệu sử dụng các tag-number — tức là các con số 1, 2 và 3. Đây chính là những con số xuất hiện trong định nghĩa của schema.
Các thẻ trường giống như bí danh cho các trường — chúng là một cách gọn gàng để chỉ ra trường nào đang được tham chiếu mà không cần phải viết đầy đủ tên trường.
CompactProtocol về cách xử lý sẽ giống với BinaryProtocol, nhưng gói cùng một lượng thông tin chỉ trong 34 byte. Nó thực hiện điều này bằng cách gộp kiểu trường (field-type) và số thẻ (tag-number) vào chung một byte bằng cách sử dụng các số nguyên có độ dài biến đổi - varint (variable-length integers).
Thay vì dùng đủ tám byte cho số “1337”, nó chỉ sử dụng hai byte, với bit cao nhất của mỗi byte dùng để chỉ ra rằng còn byte tiếp theo hay không. Điều này có nghĩa là các số từ –64 đến 63 được chuyển đổi trong một byte, các số trong khoảng từ –8192 đến 8191 được chuyển đổi trong hai byte, v.v. Những số lớn hơn sẽ dùng nhiều byte hơn.
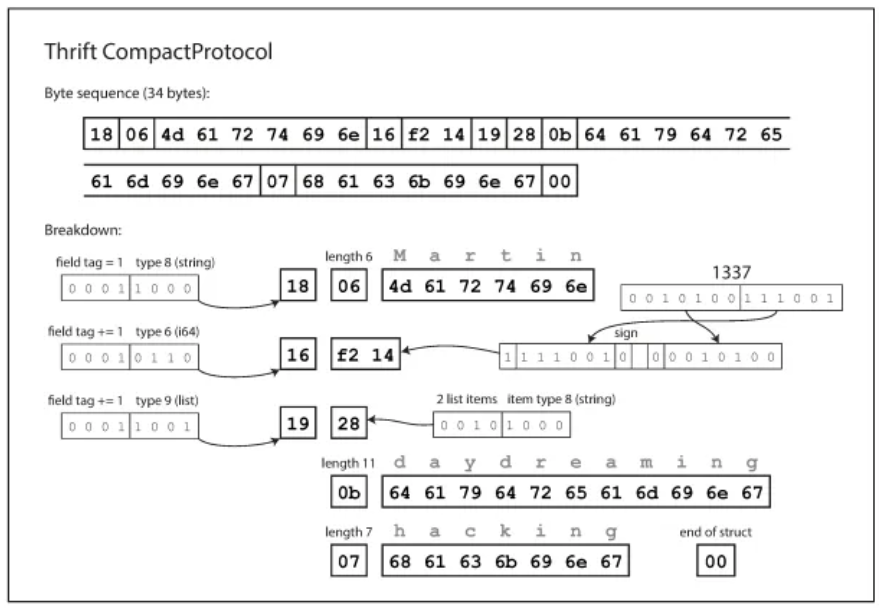
Cụ thể hơn
Trong Thrift, BinaryProtocol ghi dữ liệu nhị phân theo độ dài cố định nên tốn nhiều byte nên mỗi trường cần ít nhất 3 byte metadata (type và number) và số nguyên luôn chiếm 4 - 8 byte.
CompactProtocol tối ưu hơn bằng hai cơ chế
- Gộp field-type và tag-number vào chung 1 byte, nhờ lưu ưu chênh lệch (delta) giữa tag-number hiện tại và trước đó (nếu encoding gọn trong 1 byte) và 4 bit cho field-type.
- Dùng varint để nén số nguyên, kết hợp với zigzag encoding để chuyển số âm thành số dương nhỏ gọn, giúp giá trị nhỏ chỉ cần 1 byte thay vì 4. Nhờ đó, cùng một cấu trúc, dữ liệu có thể giảm từ hơn 10 byte (BinaryProtocol) xuống chỉ 3–4 byte (CompactProtocol) nên tiết kiệm băng thông đáng kể.
Xét ví dụ:
struct User {
1: required i32 id;
2: required bool active;
}
Giả sử giá trị: id = 5, active = true
| Tên trường | BinaryProtocol | CompactProtocol |
|---|---|---|
id |
- Field-type (1 byte): 08 - Tag-number(2 byte): 00 01 - Value i32 (4 byte): 00 00 00 05 → 7 byte |
- Delta + type (1 byte): 12 (0001 0010, delta=1, type=i32) - Value i32 varint (1 byte): 05 → 2 byte |
active |
- Field-type (1 byte): 02 - Tag-number (2 byte): 00 02 - Value bool (1 byte): 01 → 4 byte |
- Delta + type (1 byte): 11 (0001 0001, delta=1, type=bool) - Value bool (nằm trong type nên không cần thêm byte) → 1 byte |
| Tổng cộng | 11 byte | 3 byte |
Giải thích
- BinaryProtocol sẽ luôn ghi đủ 3 byte metadata/field và số nguyên theo 4 byte cố định.
- CompactProtocol sẽ gộp field-type + tag-number vào 1 byte, dùng varint cho số nhỏ.
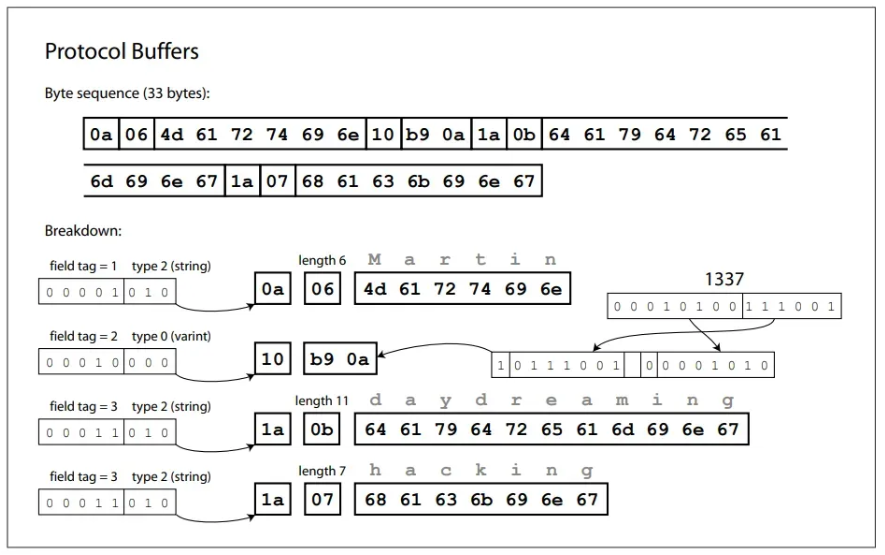
Cuối cùng là Protocol Buffers - đây là định dạng tương đối tương đồng với CompactProtocol của Thrift về tư tưởng thiết kế.
CompactProtocol của Thrift giảm kích thước bằng cách gộp kiểu trường và số thẻ vào một byte đồng thời dùng số nguyên có độ dài biến đổi (variable-length integers). Nhờ đó dữ liệu thường nhỏ hơn so với BinaryProtocol. Protocol Buffers cũng dùng cơ chế tương tự (varint, packed fields) và tối ưu hóa mạnh cho hiệu năng khi chuyển đổi. Những cải tiến đó giúp kích thước dữ liệu giảm xuống chỉ còn 33 byte.
Tuy nhiên, khác với Thrift hỗ trợ nhiều định dạng khác nhau (Binary, Compact, JSON…) - Protocol Buffers chỉ tập trung vào định dạng nhị phân (Binary).
Lưu ý
Trong các schema được trình bày trước đó, mỗi trường đều được đánh dấu là bắt buộc (required) hoặc tùy chọn (optional), nhưng điều này không tạo ra khác biệt trong cách trường đó được chuyển đổi - không có gì trong dữ liệu nhị phân cho biết một trường là bắt buộc hay không. Sự khác biệt duy nhất là trường bắt buộc cho phép kiểm tra trong lúc chạy (runtime check) và sẽ báo lỗi nếu trường đó không được thiết lập. Điều này có thể hữu ích để phát hiện lỗi.
Đảm bảo tính tương thích
Thrift và Protocol Buffers quản lý sự thay đổi của schema thông qua một vài nguyên tắc cốt lõi để đảm bảo tính tương thích ngược và xuôi. Mỗi trường trong schema được gán với một số (1, 2 và 3) duy nhất, thay vì dựa vào tên, điều này cho phép thoải mái đổi tên trường mà không làm hỏng dữ liệu hiện có.
Tuy nhiên, việc thay đổi số của một trường là không được phép vì sẽ làm mất hiệu lực của tất cả dữ liệu đã được chuyển đổi trước đó. Khi thêm một trường mới, nó phải được gán một số mới và là một trường tùy chọn, vì việc thêm một trường bắt buộc sẽ ngăn cản mã mới đọc được dữ liệu cũ. Tương tự, chỉ các trường tùy chọn mới có thể bị xóa và số của chúng cũng không được phép tái sử dụng.
Về thay đổi kiểu dữ liệu, điều này có thể thực hiện nhưng đi kèm với rủi ro mất độ chính xác. Mã mới có thể đọc dữ liệu cũ dễ dàng, nhưng mã cũ đọc dữ liệu mới có thể bị lỗi nếu dữ liệu không tương thích với kiểu dữ liệu cũ.
IV. Dataflow
1. Databases
Trong một hệ thống cơ sở dữ liệu, việc ghi dữ liệu vào được gọi là encoding và việc đọc dữ liệu ra được gọi là decoding. Khi chỉ có một luồng duy nhất truy cập cơ sở dữ liệu thì việc lưu trữ dữ liệu là thao tác chuẩn bị thông tin để chính chúng ta xử lý trong tương lai. Điều này đòi hỏi khả năng tương thích ngược (để luồng đọc có thể hiểu được dữ liệu mà luồng ghi đã ghi vào trước đó).
Tuy nhiên, trong môi trường thực tế, nhiều luồng khác nhau thường truy cập cùng lúc vào một cơ sở dữ liệu. Các luồng này có thể là nhiều ứng dụng khác nhau hoặc các phiên bản của cùng một ứng dụng (instances).
Điều này tạo ra một tình huống phức tạp hơn: dữ liệu được ghi bởi phiên bản code mới hơn có thể được đọc bởi phiên bản code cũ hơn. Vì vậy, khả năng tương thích xuôi cũng trở nên cần thiết. Một vấn đề phát sinh là khi code mới thêm một trường dữ liệu mới vào một bản ghi và ghi nó vào cơ sở dữ liệu. Khi code cũ đọc bản ghi đó, nó không nhận biết trường mới này. Trong trường hợp này, hành vi mong muốn là code cũ sẽ giữ nguyên trường dữ liệu mới đó mà không làm hỏng nó, mặc dù nó không thể hiểu được nội dung của trường đó.
Tóm lại, các hệ thống cơ sở dữ liệu hiện đại đòi hỏi cả khả năng tương thích ngược (để đọc dữ liệu cũ) và khả năng tương thích xuôi (để xử lý dữ liệu mới) để đảm bảo hoạt động trơn tru trong một môi trường luôn thay đổi.
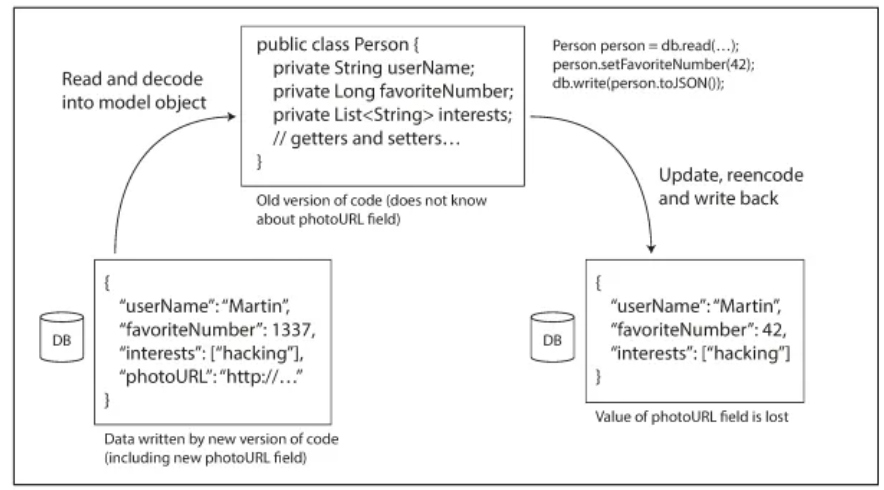
Cơ sở dữ liệu thường cho phép bất kỳ giá trị nào được cập nhật bất cứ lúc nào. Điều này có nghĩa là trong một cơ sở dữ liệu, có thể có một số giá trị được ghi cách đây năm giây và một số giá trị được ghi cách đây năm năm.
Khi triển khai phiên bản mới của một ứng dụng, ta có thể thay thế hoàn toàn phiên bản cũ bằng phiên bản mới trong vòng vài phút. Nhưng điều này không đúng với cơ sở dữ liệu. Cụ thể hơn là dữ liệu năm năm tuổi vẫn sẽ ở đó và vẫn tuân theo quy tắc encoding cũ trừ khi bạn đã rewrite nó một cách rõ ràng vào thời điểm thay đổi. Việc đó được gọi là data outlives code.
Việc migrate dữ liệu sang một schema mới chắc chắn là khả thi, nhưng việc này khá tốn kém trên một tập dữ liệu lớn, vì vậy hầu hết các cơ sở dữ liệu đều tránh làm điều này nếu có thể.
Các cơ sở dữ liệu quan hệ đa phần đều hỗ trợ thay đổi schema một cách đơn giản. Chẳng hạn như thêm một cột mới với giá trị mặc định là null mà không cần ghi lại dữ liệu hiện có. Khi một hàng cũ được đọc, cơ sở dữ liệu sẽ điền giá trị null cho bất kỳ cột nào bị thiếu trong dữ liệu trên đĩa.
2. REST vs RPC
Trong một hệ thống mạng, giao tiếp giữa các tiến trình thường được tổ chức theo mô hình client-server. Trong mô hình này, server (máy chủ) cung cấp một API qua mạng và client (máy khách) kết nối với server để gửi các yêu cầu đến API đó (các dịch vụ web).
Trình duyệt web (client) sẽ gửi các yêu cầu như GET để tải dữ liệu (HTML, CSS, hình ảnh,...) hoặc POST để gửi dữ liệu đến máy chủ web (server). Nhờ các giao thức chuẩn như HTTP, URL, SSL/TLS, bất kỳ trình duyệt nào cũng có thể truy cập bất kỳ trang web nào.
Ngoài trình duyệt, các ứng dụng gốc trên thiết bị di động hay máy tính để bàn cũng có thể hoạt động như client. Thậm chí, một ứng dụng JavaScript chạy trong trình duyệt cũng có thể trở thành một client HTTP (kỹ thuật Ajax). Trong những trường hợp này, server thường trả về dữ liệu ở định dạng như JSON để các ứng dụng có thể xử lý, thay vì trả về HTML để hiển thị cho người dùng.
Một điểm quan trọng khác là một server cũng có thể đồng thời là client của một dịch vụ khác. Cách tiếp cận này thường được sử dụng để chia nhỏ một ứng dụng lớn thành các dịch vụ nhỏ hơn, mỗi dịch vụ đảm nhận một chức năng cụ thể. Kiểu kiến trúc này phát triển thành kiến trúc hướng dịch vụ (SOA) và gần đây là kiến trúc microservices.
Một mục tiêu thiết kế cốt lõi của kiến trúc hướng dịch vụ/microservices là làm cho ứng dụng dễ dàng thay đổi và bảo trì hơn bằng cách cho phép các dịch vụ được triển khai và phát triển một cách độc lập. Ví dụ, mỗi dịch vụ nên do một đội nhóm chịu trách nhiệm và đội nhóm đó có thể phát hành các phiên bản mới của dịch vụ một cách thường xuyên mà không cần phải phối hợp với các đội nhóm khác. Nói cách khác, chúng ta nên chấp nhận việc các phiên bản cũ và mới của máy chủ và máy khách cùng chạy đồng thời. Do đó, encoding dữ liệu được sử dụng bởi máy chủ và máy khách phải tương thích giữa các phiên bản của API.
REST vs SOAP
Có hai cách tiếp cận phổ biến đối với các dịch vụ web: REST và SOAP. Chúng gần như đối lập hoàn toàn về mặt triết lý và thường là chủ đề của các cuộc tranh luận gay gắt giữa những người ủng hộ chúng.
REST không phải một giao thức mà là một nguyên lý thiết kế dựa trên chính những nguyên tắc cơ bản của web. Nó tận dụng tối đa những gì HTTP có sẵn—từ các URL đơn giản để định danh tài nguyên cho đến các tính năng mạnh mẽ như kiểm soát bộ nhớ tạm và xác thực thông tin.
Nhờ sự đơn giản và tính linh hoạt này, các API RESTful trở thành lựa chọn hàng đầu cho các ứng dụng hiện đại, đặc biệt là trong kiến trúc microservices. Chúng giúp việc phát triển trở nên nhanh chóng và hiệu quả, cho phép các đội nhóm hoạt động độc lập mà không cần quá nhiều công cụ phức tạp.
Ngược lại, SOAP lại theo đuổi một con đường hoàn toàn khác. Là một giao thức dựa trên XML, SOAP sử dụng một bộ tiêu chuẩn đồ sộ, phức tạp để đảm bảo tính chặt chẽ. Mặc dù nó thường chạy trên HTTP, SOAP lại cố gắng "độc lập" khỏi các tính năng của HTTP, thay vào đó tạo ra một hệ sinh thái riêng với các tiêu chuẩn WS-*. Điều này cũng khiến SOAP được đánh giá cao hơn về tính bảo mật nếu so sánh với REST (các bảo mật của API RESTful phụ thuộc nhiều vào giao thức HTTP).
Sự phức tạp của SOAP đòi hỏi các công cụ chuyên dụng và trình tạo mã tự động, khiến việc tích hợp trở nên khó khăn nếu thiếu sự hỗ trợ. Cho nên mặc dù vẫn còn tồn tại trong nhiều hệ thống doanh nghiệp lớn, triết lý cầu kỳ của SOAP đã không còn phù hợp với xu hướng phát triển nhanh và gọn của thế giới công nghệ ngày nay.
Sự phát triển của RPC
RPC (Remote Procedure Call) là một giao thức cho phép một chương trình máy tính yêu cầu một dịch vụ từ một chương trình khác trên một máy tính khác trong mạng mà không phải hiểu chi tiết về mạng đó. Nó giúp viết các chương trình phân tán giống như khi gọi một hàm cục bộ.
RPC hoạt động theo mô hình client-server, trong đó client gọi một hàm/thủ tục (procedure) từ xa và server thực thi nó, sau đó gửi kết quả trở lại.
Nó thường được sử dụng để gọi các dịch vụ trên các máy chủ từ xa, giúp đơn giản hóa việc phát triển các ứng dụng phân tán. RPC được xem là một phương pháp cổ điển và hiệu quả để giao tiếp giữa các tiến trình.
Tuy nhiên, việc giao tiếp thông qua mạng (network-call) rất khác so với việc giao tiếp nội bộ (local-call) nên khi sử dụng RPC các điểm yếu dần xuất hiện:
- Việc giao tiếp nội bộ (như các hàm gọi lẫn nhau) thường luôn biết rõ kết quả success hoặc failure vì toàn bộ các tham số đều có thể kiểm soát được. Tuy nhiên nếu việc giao tiếp thông qua mạng (network-call) rất nhiều sự cố không mong muốn hoàn toàn có thể xảy ra. Điều đó có thể dẫn đến việc client không thể nhận được response.
- Một lệnh gọi hàm nội bộ có thể trả về kết quả, hoặc ném ra ngoại lệ, hoặc không bao giờ trả về (vì nó rơi vào vòng lặp vô hạn hoặc tiến trình bị sập). Một yêu cầu mạng có thể có một kết quả khác - nó có thể trả về mà không có kết quả (Null-value) do hết thời gian chờ (timeout). Trong trường hợp đó, ta hoàn toàn không biết chuyện gì đã xảy ra. Nếu không nhận được phản hồi từ web-service, không có cách nào biết liệu yêu cầu có được xử lý hay không.
- Nếu bạn retry một request không thành công, có thể request trước đó thực sự được chuyển tiếp và chỉ có response bị mất. Trong trường hợp đó, việc retry sẽ khiến hành động được thực hiện nhiều lần, trừ khi bạn xây dựng một cơ chế loại bỏ trùng lặp (idempotence) vào giao thức. Các lệnh gọi hàm cục bộ không gặp phải vấn đề này.
- Mỗi lần bạn gọi một hàm cục bộ, thông thường thời gian thực thi sẽ gần bằng nhau. Yêu cầu mạng chậm hơn nhiều so với lệnh gọi hàm và độ trễ của nó cũng rất khác nhau. Đôi khi nó có thể hoàn tất trong chưa đầy một mili-giây nhưng khi mạng bị tắc nghẽn hoặc web-service bị quá tải, có thể mất nhiều giây để thực hiện chính xác cùng một việc.
- Khi bạn gọi một hàm cục bộ, bạn có thể truyền tham chiếu đến các đối tượng trong bộ nhớ cục bộ một cách hiệu quả. Khi bạn thực hiện một yêu cầu mạng, tất cả các tham số đó cần được chuyển đối thành một chuỗi byte có thể được gửi qua mạng. Điều này không phải vấn đề nếu các tham số là các kiểu dữ liệu nguyên thủy như int hoặc string, nhưng sẽ nhanh chóng trở nên khó khăn khi kiểu dữ liệu là các object có kích thước **lớn.
- Client và web-service có thể được triển khai bằng các ngôn ngữ lập trình khác nhau. Do đó, RPC phải dịch các kiểu dữ liệu từ ngôn ngữ này sang ngôn ngữ khác. Điều này có thể dẫn đến hậu quả xấu, vì không phải tất cả các ngôn ngữ đều có cùng kiểu dữ liệu.
Mặc dù có một số vấn đề, RPC (Remote Procedure Call) vẫn phát triển mạnh mẽ nhờ các framework hiện đại như Thrift, Avro, và gRPC (sử dụng Protocol Buffers). Thế hệ RPC mới này đã giải quyết những điểm yếu của mô hình cũ bằng cách nhận thức rõ ràng sự khác biệt giữa gọi hàm từ xa và hàm cục bộ. Chúng sử dụng các kỹ thuật như futures (promises) để xử lý các yêu cầu không đồng bộ và cho phép thực hiện nhiều yêu cầu song song và gRPC còn hỗ trợ streams cho phép trao đổi một chuỗi yêu cầu và phản hồi liên tục.
Về mặt hiệu năng, các giao thức RPC mới tùy chỉnh với định dạng nhị phân có thể vượt trội hơn so với JSON qua REST. Tuy nhiên, RESTful API lại chiếm ưu thế đối với các API công khai nhờ khả năng dễ thử nghiệm, gỡ lỗi và được hỗ trợ bởi một hệ sinh thái công cụ phong phú. Vì vậy, các framework RPC mới chủ yếu tập trung vào việc giao tiếp giữa các dịch vụ nội bộ trong cùng một tổ chức hoặc các dịch vụ đòi hỏi tối ưu về hiệu năng.
3. Message brokers
Một thành phần cốt lõi trong các hệ thống phân tán là Message brokers, đóng vai trò như một trung gian, cho phép các tiến trình giao tiếp mà không cần kết nối trực tiếp. Các nền tảng mã nguồn mở như RabbitMQ và Apache Kafka đã thay thế các giải pháp truyền thống và trở nên cực kỳ phổ biến.
Cách hoạt động
Một producer gửi thông điệp (message) đến một queue hoặc topic cụ thể và broker sẽ đảm bảo thông điệp đó được chuyển đến một hoặc nhiều consumer đã đăng ký. Mô hình này giúp tách rời các tiến trình, cho phép nhiều producer và consumer hoạt động song song. Mặc dù luồng dữ liệu thường là một chiều, nó có thể được mở rộng để hỗ trợ trao đổi hai chiều, giống như trong RPC.
Một ưu điểm lớn của Message brokers là tính linh hoạt. Chúng không yêu cầu một định dạng dữ liệu cụ thể mà cho phép ta sử dụng bất kỳ encoding format nào.
Để hệ thống hoạt động ổn định và dễ dàng nâng cấp, các bên gửi và nhận dữ liệu cần có thể thay đổi phiên bản độc lập với nhau. Muốn vậy, ta phải sử dụng các encoding format có khả năng tương thích xuôi và cả tương thích ngược. Nhờ đó, có thể triển khai cập nhật mà không làm gián đoạn toàn bộ hệ thống.
Điều này có nghĩa là phiên bản mới của hệ thống vẫn đọc được dữ liệu từ phiên bản cũ (tương thích ngược), và ngược lại, phiên bản cũ vẫn có thể bỏ qua các trường dữ liệu mới được thêm vào từ phiên bản mới (tương thích xuôi).
Nếu một producer (bên gửi) lấy thông điệp từ một topic và gửi lại sang một topic khác, chúng ta cần đảm bảo rằng các trường dữ liệu mà producer không hiểu phải được bảo toàn. Nếu không, các trường này sẽ bị mất và gây ra lỗi hoặc thiếu dữ liệu cho các consumer (bên nhận), đặc biệt là những bên sử dụng phiên bản mới hơn.
All rights reserved
