Đánh giá hiệu năng hệ thống tìm kiếm trình diễn thông tin
Bài đăng này đã không được cập nhật trong 6 năm
Tìm kiếm trình diễn thông tin là một bài toán đã được phát triển từ rất lâu. Cho đến nay có rất nhiều kĩ thuật tìm kiếm được phát triển phù hợp với từng bài toán thực tế, không chỉ dừng lại ở tìm kiếm văn bản mà còn tìm kiếm âm thanh, hình ảnh, ... Trong các hệ thống tìm kiếm ngày nay, bên cạnh những kĩ thuật phục vụ cho việc tìm kiếm, những phương pháp đánh giá kết quả cũng đóng vai trò không kém phần quan trọng. Với việc đánh giá trực quan và hiệu quả, ta có thể đánh giá được hiệu năng của hệ thống tìm kiếm, từ đó biết được kĩ thuật tìm kiếm sử dụng có phù hợp với bài toán và dữ liệu không để điểu chỉnh cho phù hợp. Trong bài viết này, các kĩ thuật đánh giá cơ bản trong một hệ thống tìm kiếm sẽ được trình bày giúp người đọc có một cái nhìn tổng quan về việc đánh giá kết quả trong các hệ thống tìm kiếm nhỏ thường xuất hiện hàng ngày (vd: tìm kiếm hàng hóa tại cửa hàng, tìm kiếm văn bản liên quan, ....)
1. Tổng quan hệ thống đánh giá
Để phục vụ cho việc đánh giá, ta cần một tập test cho hệ thống. Tập test này bao gồm:
- Tập dữ liệu chứa tất cả các kết quả
- Tập kiểm tra chứa kết quả truy vấn cho từng câu truy vấn cụ thể
- Tập thể hiện mức độ liên quan của các kết quả với các câu truy vấn
Phương pháp đánh giá tập trung vào hai khái niệm chính cho một kết quả là relevant (liên quan) và non-relevant (không liên quan). Mức độ liên quan được đánh giá trên lượng thông tin mà người dùng thực sự cần. Vì lí do này, tập test cho hệ thống đánh giá nên được xây dựng trên ý kiến của người dùng hơn là ý kiến chủ quan của người xây dựng hệ thống.
Một kết quả được cho là relevant nếu nó giải quyết được lượng thông tin người dùng cần. Ví dụ: lượng thông tin người dùng cần là: "Bệnh viện tốt nhất tại Hà Nội", những kết quả như: "Bệnh viện Bạch Mai", "Bệnh viện Nhiệt đới Trung ương" rõ ràng giải quyết nhu cầu thông tin hơn là những kết quả như "quán ăn tốt nhất tại Hà Nội" mặc dù nó chứa nhiều từ trong câu truy vấn hơn các kết quả trên. Sự khác biệt này đôi khi bị hiểu lầm vì khái niệm "nhu câu thông tin" trong thực tế không phải luôn luôn được chỉ ra rõ ràng. Do đó, trước khi xây dựng hệ thống tìm kiếm, nhu câu thông tin của người dùng cần được xác định và chỉ ra rõ ràng. Nếu người dùng nhập python vào ô tìm kiếm, họ có thể muốn tìm mua một con trăn, họ cũng có thể muốn học lập trình. Vì lí do đó nên hệ thống đánh giá nói chung và tập test nói riêng cần được xây dựng dựa trên người dùng.
2. Đánh giá hệ thống tìm kiếm
Trong phần 2, các độ đo thường dùng để đánh giá được đưa ra và thảo luận chi tiết. Tuy nhiên, việc đánh giá cần được thực hiện trong những bài toán và trường hợp cụ thể. Những độ đo dưới đây tập trung vào lượng kết quả trả về, chứ không tập trung vào việc sắp xếp các kết quả. Việc đánh giá kết quả được xếp hạng sẽ được trình bày ở các bài viết sau.
2.1. Các độ đo cơ bản
Hai độ đo cơ bản và không thể thiếu trong việc đánh giá một hệ thống tìm kiếm là Precision và Recall.
Giả sử hệ thống tìm kiếm trả về một tập kết quả cho một câu truy vấn. Hai độ đo trên được định nghĩa như sau:
- Precision (P): là độ đo được tính bằng tỉ lệ số lượng kết quả relevant trên tổng số lượng kết quả trả về.
- Recall (R): là độ đo được tính bằng tỉ lệ số lượng kết quả relevant trên tổng số lượng kết quả relevant trong tập test.
Một cách giải thích trực quan hơn, hãy nhìn vào bảng dưới đây
| Relevant | Nonrelevant | |
|---|---|---|
| Retrieved | true positives (tp) | false positives (fp) |
| Not Retrieved | false negatives (fn) | true negatives (tn) |
Khi đó:
Một độ đo khác mà chúng ta có thể gặp khi đọc các tài liệu về hệ thống tím kiếm đó là Accuracy (A). Độ đo này được tính bằng tỉ lệ giữa các kết quả được phân loại đúng (bao gồm cả relevant và non-relevant) trên tổng số kết quả. Cụ thể:
Truy nhiên độ đo này không quá phù hợp với hệ thống tìm kiếm thông tin. Lí do là vì trong hầu hết các trường hợp, các dữ liệu non-relevant thường lớn hơn rất nhiều so với dữ liệu relevant vì thế khi cải thiện độ đo này, sự ảnh hưởng của chúng ta lên sự chính xác thực sự của kết quả trả về là rất thấp. Trong thực tế, độ đo này phù hợp hơn và thường được sự dụng trong các hệ thống học máy.
Điểm mạnh của 2 độ đo Precision và Recall là ta có thể đánh giá trực quan hệ thống vừa dựa trên kết quả thực tế đã trả về, vừa dựa trên kết quả đáng ra phải được trả về. Một hệ thống lý tưởng sẽ trả về tập kết quả là tất cả các kết quả trong tập test, khí đó giá trị của . Có thể nhận thấy rằng Precision và Recall là 2 giá trị liên quan mật thiết đến nhau. Cụ thể là khi tăng thì sẽ giảm và ngược lại:
- Khi tăng thì giảm: Để đạt giá trị cao - các kết quả trả về có độ chính xác lớn, ta chỉ cần hạn chế số lượng kết quả trả về. Ví dụ đơn giản nếu kết quả trả về là 1 và kết quả đó nằm trong 50 kết quả của tập test thì giá trị của . Tuy nhiên khi đó giá trị của sẽ rất nhỏ vì có quá ít kết quả được trả về, cụ thể trong trường hợp trên giá trị của chỉ là .
- Khi tăng thì giảm: Rõ ràng là theo chiều tăng của số lượng các kết quả trả về, các kết quả trong tập test sẽ dễ được trả về hơn, dẫn đến tăng, tuy nhiên khi có quá nhiều kết quả trả về, độ chính xác sẽ bị giảm đi đáng kể. Ví dụ trả về kết quả trong đó bao gồm kết quả trong tập test thì trong khi chỉ là .
Hình dưới đây thể hiện sự phụ thuộc của 2 độ đo Precision và Recall:
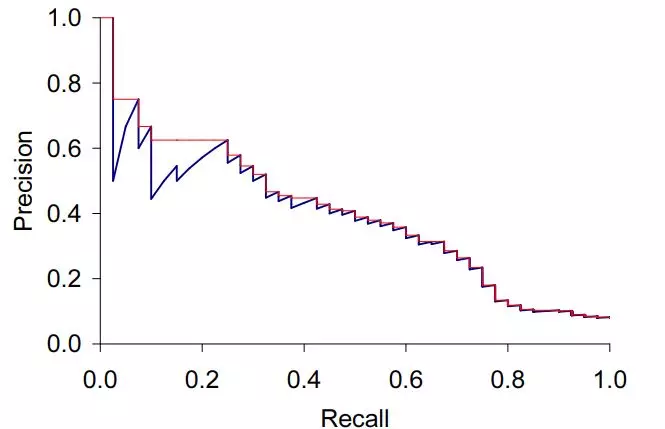
2.2. Một số độ đo khác
Precision và Recall là 2 độ đo cơ bản trong việc đánh giá hệ thống tìm kiếm, tuy nhiên chúng chỉ được áp dụng trong một câu truy vấn. Khi lượng câu truy vấn mẫu lên đến vài nghìn thậm chí hàng triệu, chúng ta cần đánh giá tổng quan hiệu năng của hệ thống trên tất cả các câu truy vấn. Một số độ đo sau đây sẽ giải quyết được vấn đề này.
Với số lượng câu truy vấn là
- Mean Precision (MP): Độ đo tính trung bình giá trị của tất cả các câu truy vấn:
- Mean Recall (MR): Độ đo tính trung bình giá trị của tất cả các câu truy vấn:
Ngoài Precision và Recall, Khi muốn đánh giá hệ thống bằng một giá trị thống nhất, độ đo F thường được sử dụng để kết hợp hai đại lượng này thành một đại lượng duy nhất. Có nhiều cách tính độ đo F, dưới đây là 3 cách tính đại lượng này thường được sử dụng:
Với và
Một vài lưu ý:
- Nếu hoặc , thì là trung bình điều hòa của và
- Nếu ,
- Nếu ,
Kết luận
Bài viết tập trung vào 2 độ đo chính là Precision và Recall và một vài độ đo liên quan. Về cơ bản với những độ đo này, chúng ta có thể đánh giá hầu hết các hệ thống tìm kiếm thông tin trong thực tế. Tuy nhiên, một vấn đề quan trọng mà bài viết chưa đề cập đến là việc đánh giá thứ tự của kết quả trả về. Vấn đề này được thảo luận và trình bày rất kĩ trong tài liệu được đưa ra trong phần danh mục tài liệu tham khảo và sẽ được đề cập ở các bài viết sau.
Danh mục tài liệu tham khảo
- Sách Introduction to Information Retrieval - Stanford NLP Group (https://nlp.stanford.edu/IR-book/pdf/irbookonlinereading.pdf)
Chapter 8: Evaluation in information retrieval
All rights reserved
