Crawling dữ liệu từ website, tìm hiểu về ScrapingWeb
Bài đăng này đã không được cập nhật trong 6 năm
Dữ liệu đã và đang trở thành một phần chính trong chiến lược tăng trưởng của mọi công ty. Các dữ liệu này bao gồm:
- Dữ liệu công khai.
- Dữ liệu thông tin người dùng.
- Dữ liệu của đối thủ cạnh tranh.
- Dữ liệu thị trường chứng khoán.
- Dữ liệu sản phẩm.
- Dữ liệu công việc.
- Dữ liệu dự báo thời tiết v...v...
Tuy nhiên, các dữ liệu đều có đặc điểm chung là cần xây dựng mô hình học máy hoặc tìm kiếm dữ liệu mà không thể nhìn thấy bằng mắt thường. Khi bạn thu thập dữ liệu từ các nguồn sẵn có - báo hoặc các trang website đến các cơ sở dữ liệu, sách nội bộ nếu thu thập bằng tay rất kho khắn vì 2 lý do: Tỉ lệ sai lệch dữ liệu lớn và chậm chạp kèm theo việc tăng số lượng người xử lý dữ liệu sau khi lấy.
Thu thập thông tin: Là việc xử lý các tập dữ liệu lớn nơi cần các trình thu thập dữ liệu ( hoặc bot ) của riêng mình để thu thập các dữ liệu sâu nhất trên website. Mặt khác, dữ liệu được dùng để lấy thông tin từ bất kỳ nguồn nào đều cần trích xuất dữ liệu dưới dạng scraping ( hoặc harvesting) - quan điểm sai lầm nghiêm trọng.
Scraping data
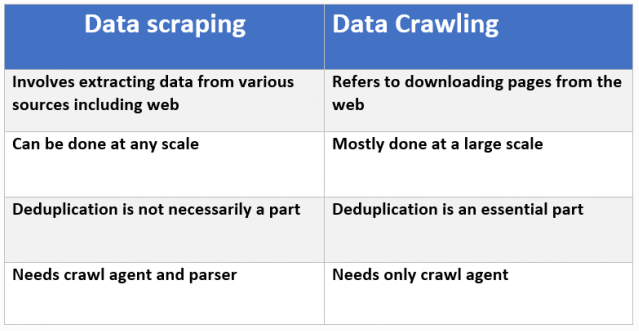
 Scraping dữ liệu không nhất thiết phải liên quan đến web. Scraping có thể đề cập đến việc trích xuất thông tin từ một hệ thống cục bộ, cơ sở dữ liệu chung hoặc thậm chí từ internet. Web Scaping cũng thực hiện việc tìm kiếm và thu thập thông tin nhưng khác với Web Crawling, Web Scraping không thu thập toàn bộ thông tin của một trang web mà chỉ thu thập những thông tin cần thiết, phù hợp với mục đích của người dùng. Trong WebScraping chúng ta cũng phần nào sử dụng WebCrawler để thu thập dữ liệu, kết hợp với Data Extraction (trích xuất dữ liệu) để tập trung vào các nội dung cần thiết.
Scraping dữ liệu không nhất thiết phải liên quan đến web. Scraping có thể đề cập đến việc trích xuất thông tin từ một hệ thống cục bộ, cơ sở dữ liệu chung hoặc thậm chí từ internet. Web Scaping cũng thực hiện việc tìm kiếm và thu thập thông tin nhưng khác với Web Crawling, Web Scraping không thu thập toàn bộ thông tin của một trang web mà chỉ thu thập những thông tin cần thiết, phù hợp với mục đích của người dùng. Trong WebScraping chúng ta cũng phần nào sử dụng WebCrawler để thu thập dữ liệu, kết hợp với Data Extraction (trích xuất dữ liệu) để tập trung vào các nội dung cần thiết.
Ví dụ như đối với trang amazon.com, Web Crawling sẽ thu thập toàn bộ nội dung của trang web này (tên các sản phẩm, thông tin chi tiết, bảng giá, hướng dẫn sử dụng, các reviews và comments về sản phẩm,…). Tuy nhiên Web Scaping có thể chỉ thu thập thông tin về giá của các sản phẩm để tiến hành so sánh giá này với các trang bán hàng online khác.
Một số các trường hợp gặp phải khi scraping data:
Anti-bot detection
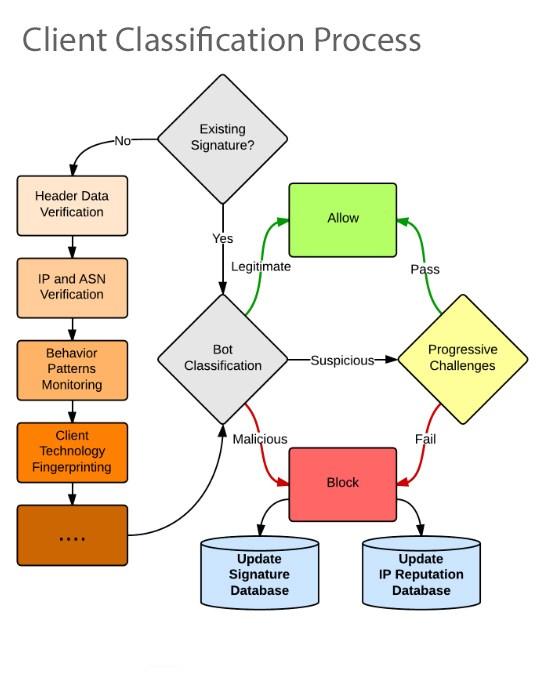
Khi cào dữ liệu thì bạn có thể gặp những websites sử dụng các cơ chế chặn bot (dĩ nhiên họ sẽ ko chặn các Search engine nổi tiếng như Google, Bing,... rồi). Họ có thể sẽ sử dụng các cơ chế:
- Phát hiện user-agents truy cập nhiều —> Giải pháp: dùng user-agent khác nhau hoặc dùng SE agents nổi tiếng cho mỗi lần request. Danh sách 450 User-Agents download tại http://cafemmo.club/threads/chia-se-danh-sach-user-agent-thong-dung-nhat.1818/
- Phát hiện IPs truy cập nhiều, giả sử 5 requests/s --> Giải pháp: dùng các dịch vụ IP rotator cho mỗi lần request. Mình dùng stormproxies(.)com.
- Phát hiện người dùng thật qua Javascript, đa số bot ko hỗ trợ JS mà --> Giải pháp: dùng headless browser như Splash, Selenium, PhantomJS, Puppeter,... Có khá nhiều sites mình gặp dùng JS để detect robot như similarweb(.)com,...
- Sử dụng honeypot traps: ví dụ như các links bẩy đính kèm display:none, visibility: hidden,... --> cài đặt cơ chế phát hiện các traps thôi ^^
- Sử dụng cookie, captcha để chặn, đa số sites dùng Cloudflare để chặn bot --> có vài script bypass Cloudflare rồi, sử dụng như https://github.com/Anorov/cloudflare-scrape (script này bypass cookie của Cloudflare nhưng chưa có cơ chế bypass captcha của Cloudflare nhé).
Ghi kết quả dữ liệu (scraped data) quá nhiều
Khi bạn cào dữ liệu với nhiều spiders, ví dụ 1 spider cào được 1 record/2s, và bạn có 20 spiders thì bạn có 10 records/s, lúc này việc ghi dữ liệu quá nhiều và liên tục vào DB sẽ làm cho DB của bạn quá tải và giảm hiệu năng, có thể ảnh hưởng đến hiệu năng hoạt động. Khi đó, bạn nên cân nhắc dùng:
- Bulk insert query: tức spider chỉ cần thực hiện 1 query để insert nhiều records
- Bulk import file: tức là spider ghi dữ liệu vào 1 file với 1000 dữ liệu chẳng hạn, sau đó bạn sử dụng lệnh import file đó vào DB. Ví dụ: MySQL (LOAD DATA LOCAL INFILE), MongoDB (mongoimport) Các DB engines nào cũng hỗ trợ 2 dạng trên, ví dụ như MySQL, MongoDB,...
Cấu trúc site thay đổi
Ví dụ như site thay đổi layout, tức HTML tags thay đổi, lúc này bạn phải thay đổi các selectors để lấy đúng dữ liệu bạn cần. Trong tình huống này, spider cần có cơ chế phát hiện sự thay đổi cấu trúc site để thông báo cho chúng ta và dừng extract data của site đó. Khi đó, mỗi site ta cần hỗ trợ nhiều schemas để extract dữ liệu hơn.
Cách ngăn chặn site Scraping:
Bạn muốn ngăn chặn một công cụ ăn cắp tài sản trí tuệ của mình có thể sử dụng phương thức phát hiện các Scraping bot và giảm thiểu việc truy vấn dữ liệu
- Sử dụng công cụ phân tích
- Triển khai các challenge-based để đánh giá hành vi của người dùng nếu hỗ trợ cookie và javascript.
- Lựa chọn hành vi tiếp cận dữ liệu
- Sử dụng robots.txt để bảo vệ website trước scraping bot ( hướng dẫn các con bot thực hiện theo rules định sẵn ). Tuy nhiên phương pháp này không được lâu dài.
Nguồn: https://securitydaily.net/tim-hieu-ve-web-scraping-bot-la-gi/ https://www.promptcloud.com/blog/data-scraping-vs-data-crawling/
All rights reserved
