Crawl dữ liệu trang web với Scrapy
Bài đăng này đã không được cập nhật trong 7 năm
Trong bài viết này mình sẽ giới thiệu cho các bạn một thư viện rất hữu ích của python khi mà chúng ta muốn crawl dữ liệu từ các trang web. Giả sử thế này, bây giờ bạn là quản lí của thế giới di dộng và bạn muốn biết khách hàng nghĩ thế nào về một sản phẩm mà bạn đã đăng lên. Với trường hợp này thì các bạn sẽ biết được điều đó qua các bình luận, nhưng các bạn muốn xem dữ liệu dạng thống kê báo cáo chứ không phải lên trang web đọc từng bình luận. Lúc này thì scrapy có thể giúp bạn crawl dữ liệu bình luận của user, và xuất dạng json, csv... Giờ bắt tay vào làm nhé
1. Tạo project Scrapy
- Việc cài đặt python, thư viện scrapy các bạn follow trên trang chủ scrapy: http://doc.scrapy.org/en/latest/intro/install.html trên này đã hướng dẫn từng bước cho các bạn cài đăt.
- Tiếp theo chúng ta sẽ tạo một project mà minh đặt tên nố là crawler với câu lệnh sau:
scrapy startproject crawler
khi đó project chúng ta vừa tạo sẽ có cấu trúc như sau:
crawler/
crawler/ # project's Python module, you'll import your code from her
spiders/ # a directory where you'll later put your spiders
__init__.py
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
scrapy.cfg # deploy configuration file
Sau khi tạo xong chạy các bạn lên trang https://www.thegioididong.com/ và chọn một sản phẩm bất kì muốn crawl comments. Ví dụ mình vào link: https://www.thegioididong.com/dtdd/samsung-galaxy-a50
Bây giờ đến bước crawl comment về
B1. Trong file items.py chúng ta sẽ viết code thêm như sau:
import scrapy
class CrawlerItem(scrapy.Item):
# define the fields for your item here like:
User = scrapy.Field()
Comment = scrapy.Field()
Time = scrapy.Field()
time, content, user là các trường mình muốn crawl : tương ứng là thời gian bình luận, nội dung bình luận, và tên người bình luận .
B2. Trong spiders/ tạo một file tên là crawler_spider.py với nội dung như sau:
from scrapy import Spider
from scrapy.selector import Selector
from crawler.items import CrawlerItem
class CrawlerSpider(Spider):
name = "crawler"
allowed_domains = ["thegioididong.com"]
start_urls = [
"https://www.thegioididong.com/dtdd/samsung-galaxy-a50",
]
def parse(self, response):
questions = Selector(response).xpath('//ul[@class="listcomment"]/li')
for question in questions:
item = CrawlerItem()
item['User'] = question.xpath(
'div[@class="rowuser"]/a/strong/text()').extract_first()
item['Comment'] = question.xpath(
'div[@class="question"]/text()').extract_first()
item['Time'] = question.xpath(
'div[@class="actionuser"]/a[@class="time"]/text()').extract_first()
yield item
ul[@class="listcomment"]/li => Inspect để xem cấu trúc html trong thẻ <ul class="listcomment"> bên trong có các thẻ li, mỗi li chứa thông tin 1 bình luận.
Inspect 1 thẻ li chứa comment nó sẽ có cấu trúc như sau:
<li class="comment_ask" id="33467716">
<div class="rowuser">
<a href="javascript:void(0)"><div>h</div><strong onclick="selCmt(33467716)">Nguyen Thi Ngan Ha</strong></a>
</div>
<div class="question">Hiện tại có máy chưa ạ</div>
<div class="actionuser" data-cl="0"><a href="javascript:void(0)" class="respondent" onclick="cmtaddreplyclick(33467716)">Trả lời</a>
<a href="javascript:void(0)" class="time" onclick="cmtReport(33467716)">1 phút trước </a>
</div>
<div class="replyLate">Quản trị viên sẽ phản hồi bình luận của chị Nguyen Thi Ngan Ha trong vòng 15 phút.</div>
<div class="listreply hide" id="r33467716"></div><div class="inputreply hide"></div>
</li>
div[@class="rowuser"]/a/strong/text() => lấy tên người bình luận
div[@class="question"]/text() => lấy nội dung bình luận
div[@class="actionuser"]/a[@class="time"]/text() => lấy thời gian bình luận
B3. Giờ mình muốn xuất ra một file lưu giữ liệu tên là comments mình sẽ chạy lệnh sau
file json:
scrapy crawl crawler -o comments.json
hoặc file csv:
scrapy crawl crawler -o comments.csv
Kết quả file json mình export được:
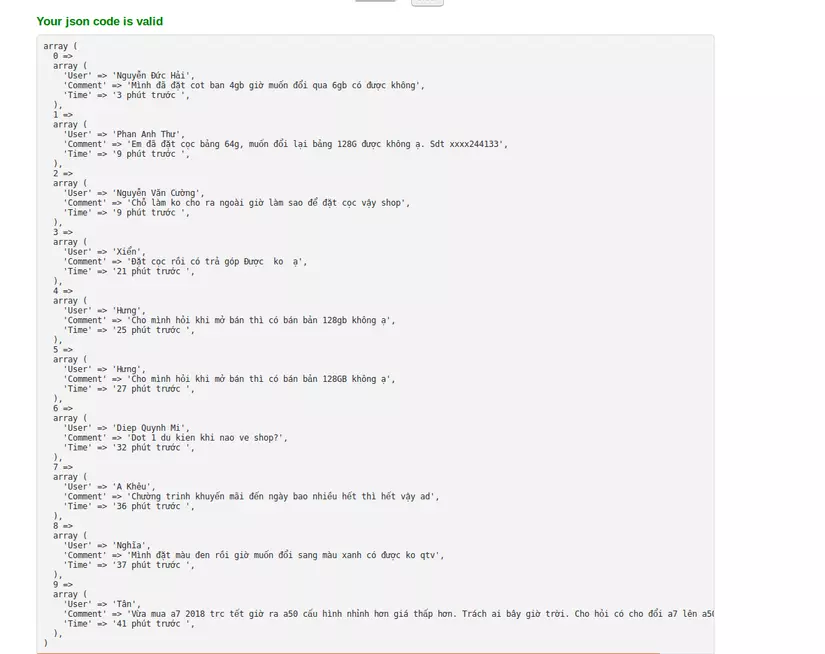
trang tgdd phân trang 10 bản ghi đầu nên mình mới lấy data của trang đầu tiên, sau khi decode thì được như ảnh trên.
Vậy là mình đã hướng dẫn các bạn dùng scrapy để crawl bình luận trên trang tgdd rồi, còn những bình luận trong phân trang các bạn có thể tìm hiểu các để crawl thêm nhé. Thanks u!
link tham khảo: http://doc.scrapy.org/en/latest/intro/install.html
All rights reserved
