Crawl data với Selenium Django PostgreSQL
Bài đăng này đã không được cập nhật trong 6 năm
Giới thiệu
Hiện nay trên internet đang có một thứ rất quý giá đó chính là dữ liệu, việc khai thác và sử dụng chúng vào trong công việc sẽ mang lại giá trị lớn đối với chúng ta. Nhưng hiện nay việc crawl data trên web dường như khó khăn hơn khi các trang web đều sử dụng cách rend data bằng JS, nếu đơn thuần chỉ sử dụng code request lên trang web muốn lấy data thì chắc chắn không được, thậm chí là bị ban ip (do request nhiều lần ). Trong bài viết này mình sẽ giới thiệu với các bạn cách crawl data bằng sự kết hợp giữa Django , Selenium, PostgreSQL.



Cài đặt
Để kiểm tra xem data trên web mình định crawl nó có hiển thị bằng JS hay không mình install một extenstion là Quick JavaScript Switcher vào trình duyệt web. Sau khi cài xong ta thử vào trang web như Shopee hay Tiki,... để thử, như hình dưới đây trang web Shopee ban đầu sẽ load ra các sản phẩm , khi ta bật extenstion lên thì sẽ nhận được web trắng tinh khôi.
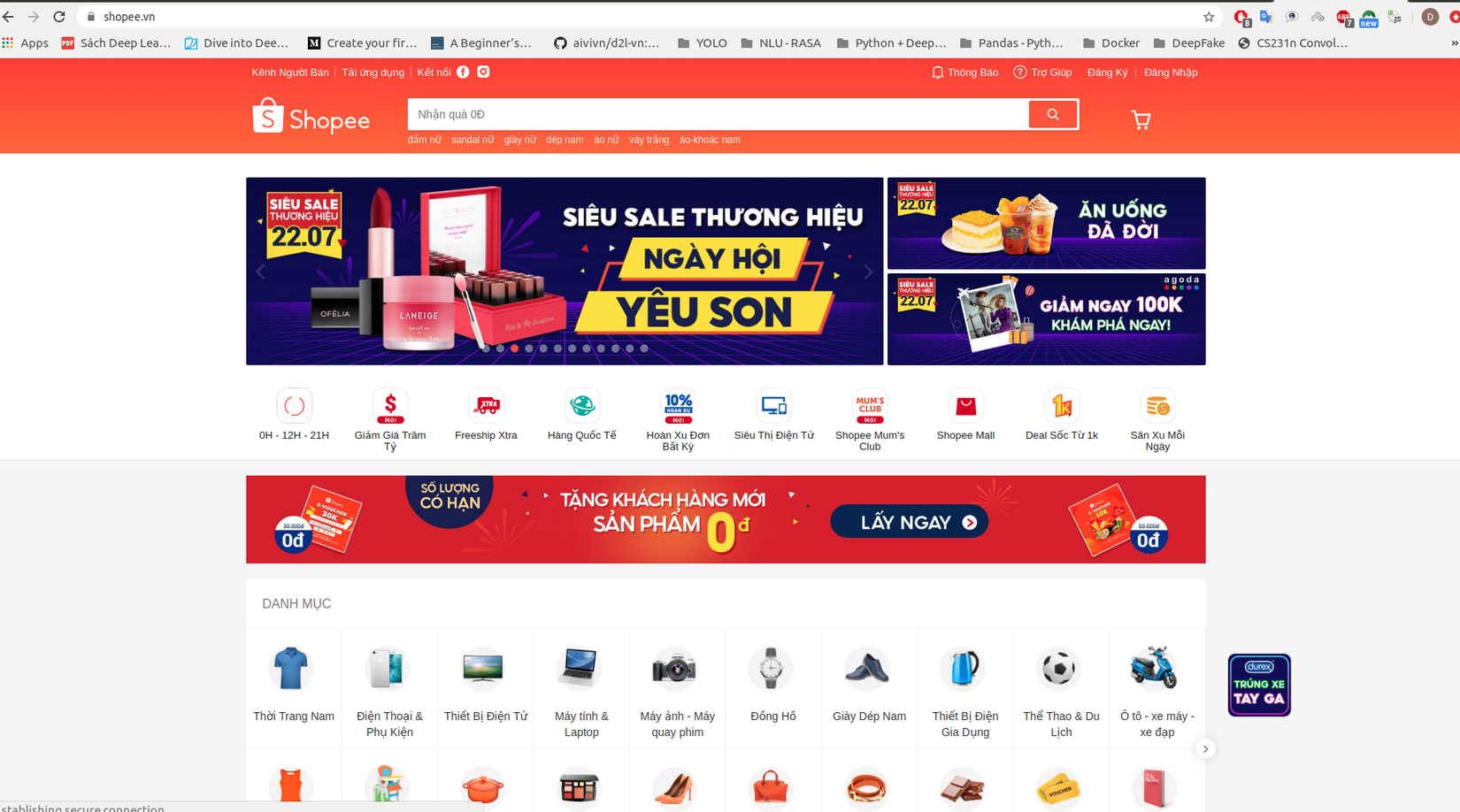
Chưa sử dụng extenstion nên data sẽ hiển thị lên web.
1.Django và PostgreSQL
Về cách cài đặt và cấu hình thì mọi người có thể xem thêm tại link này để biết thêm chi tiết. Mình tạo project như sau :
$ django-admin startproject crawl_data . (Tạo project)
$ pip install Django==2.1.3 (install Django)
$ python manage.py startapp crawl (create app)
Sau khi tạo xong project ta vào file model.py để tạo Model, tùy thuộc vào dữ liệu mà bạn muốn lấy gồm những gì thì sẽ tạo các trường phù hợp, như dưới đây mình chỉ lấy dữ liệu gồm tên sản phẩm, link sản phẩm, giá, mô tả.
from django.db import models
# Create your models here.
class Data(models.Model):
name = models.CharField('Name',max_length=255, null=True, blank=True)
link = models.CharField('Link_Image',max_length=255, null=True, blank=True)
price = models.CharField('Price',max_length=255, null=True, blank=True)
description = models.CharField('Description',max_length=255, null=True, blank=True)
def __str__(self):
return self.name
Tiếp theo trong file admin.py :
from django.contrib import admin
from .models import Data
# Register your models here.
@admin.register(Data)
class DataWeb(admin.ModelAdmin):
list_display = ['name','link','price','description'] (Khai báo hiển thị tên các trường dữ liệu)
admin.register(Data)
Và trong file setting.py hãy nhớ thêm tên app mà ta chạy lệnh startapp bên trên
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'crawl',
]
Vậy là đã xong bước tạo app ta chạy lệnh để kiểm tra:
$ python manage.py makemigrations && python manage.py migrate
$ python manage.py createsuperuser (tạo user name và pass)
$ python manage.py runserver
Ta sẽ truy cập vào đường link cổng 8000/admin để đăng nhập và thử add một vài sản phẩm :
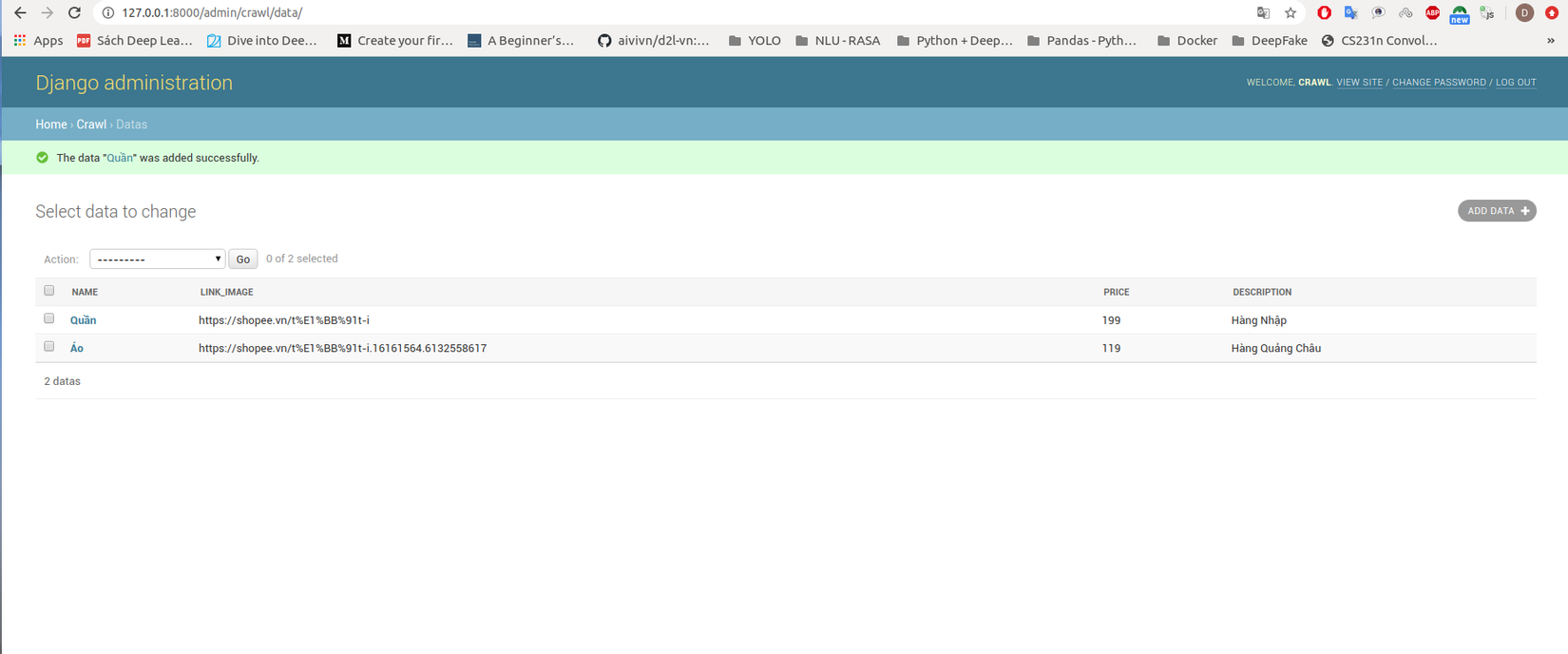
Ta cũng có thể kiểm tra db postgreSQL dưới local bằng các lệnh :
$ sudo su postgres
Sau khi vào postgres ta sẽ phải tạo User + Pass + DB trước đã :
CREATE USER user_name WITH PASSWORD 'your_pass';
CREATE DATABASE your_name_db WITH OWNER user_name;
- Note: trong setting các bạn cũng phải khai báo nội dung giống bên trên nhé (đọc kỹ nôi dung link bên trên ) :
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': 'your_name_db',
'USER': 'user_name',
'PASSWORD': 'your_pass',
'HOST': 'localhost',
'PORT': '5432',
}
}
Trong postgres :
psql -l (liệt kê db)
\c name_db (vào db)
\l (liệt kê các bảng )
SELECT * FROM name_table;
Ta nhận được kết quả giống bên trên :

2. Selenium
Selenium là một công cụ giúp tự động hóa quá trình sử dung trình duyệt giống người dùng bình thường trên browser. Từ việc truy cập vào trang chủ, next page, submit form, click button, link... đều được tiến hành một cách tự động, Ngon. Các bạn có thể search thêm các bài viết về nó để có thể hiểu rõ hơn. Trong bài này ta cũng sẽ bắt đầu từ đầu.
$ pip install selenium
Và mình cũng cần install một Web Driver có thể là ChromeDriver, Firefox hoặc Safari, tùy thuộc vào bạn. Như mình sẽ dùng Firefox, quan trọng các bạn xem kỹ link sau để cài Web Driver.
Ta open Terminal, ghi lần lượt các lệnh sau:
$ wget https://github.com/mozilla/geckodriver/releases/download/v0.24.0/geckodriver-v0.24.0-linux64.tar.gz
$ tar -xvzf geckodriver*
$ chmod +x geckodriver
$ export PATH=$PATH:/path-to-extracted-file/.( đường dẫn file đã extrac bên trên)
Sau khi đã có đầy đủ công cụ ta sẽ code thực thi như sau.
from selenium import webdriver
import time
import pandas as pd
import os
import urllib.request
for i in range(10):
urlpage = "link_url_page_you_crawl"
#urlpage = 'https://shopee.vn/%C3%81o-s%C6%A1-mi-cat.78.2828?page=' # Ví dụ crawl data trên Shopee
driver = webdriver.Firefox(executable_path='/home/to.duc.thang/geckodriver') # Khởi tạo Web Driver, nó sẽ show trình duyệt Firefox để crawl
driver.get(urlpage + str(i))
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)") # Đoạn scrip để scroll trang web
Nội dung code trên cơ bản là đưa đường link của web vào urlpage, cái vòng for nghĩa là số trang (pages ) mình muốn lấy, bên trên mình crawl 10 trang.
3. Phân tích trang web
Để crawl data ta sẽ phải bóc tách từng thuộc tính ( các thẻ HTML) để đọc dữ liệu, các thẻ <div> <img> <a> dựa vào tên thẻ và các class, id để chỉ định dữ liệu crawl.
Ví dụ như trang Shopee, ta bật Inspect lên để đọc.
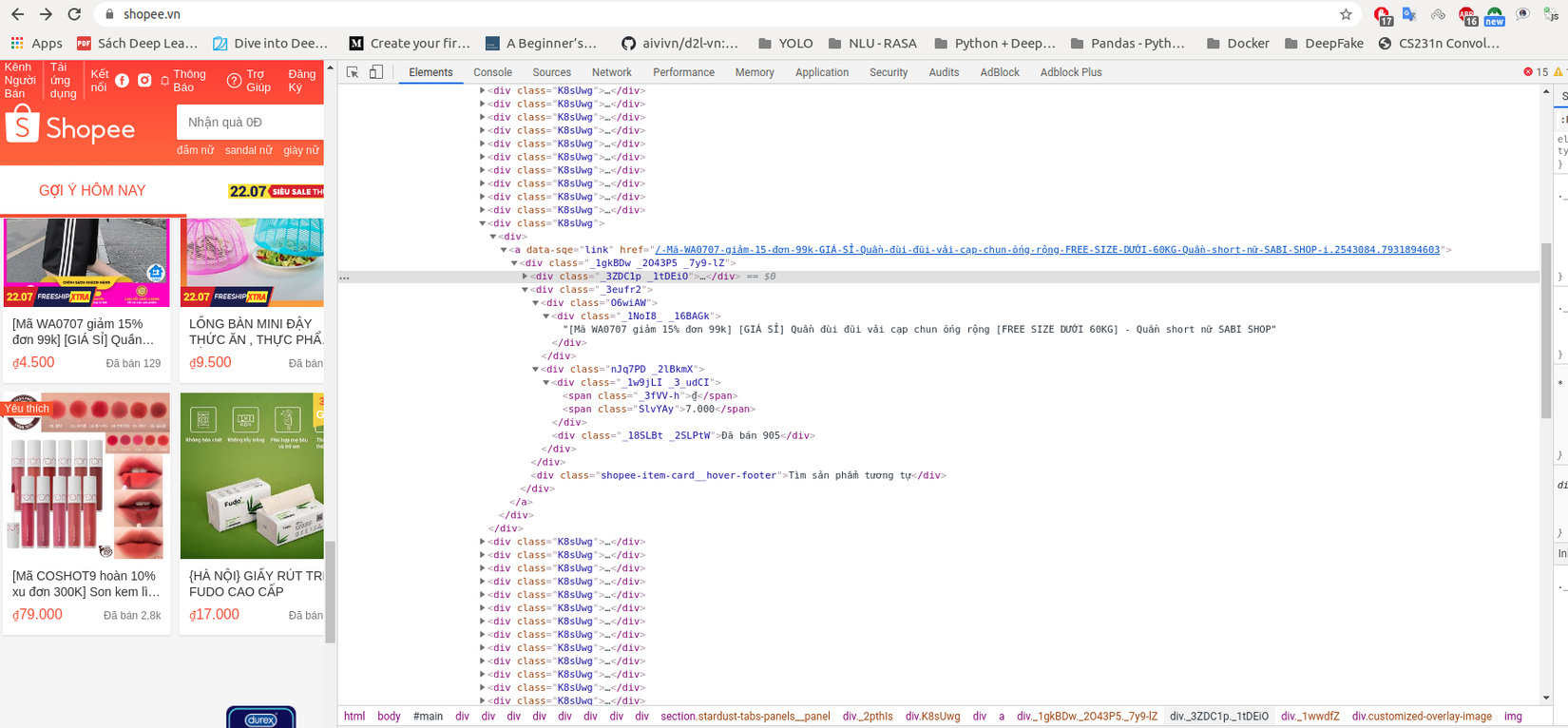
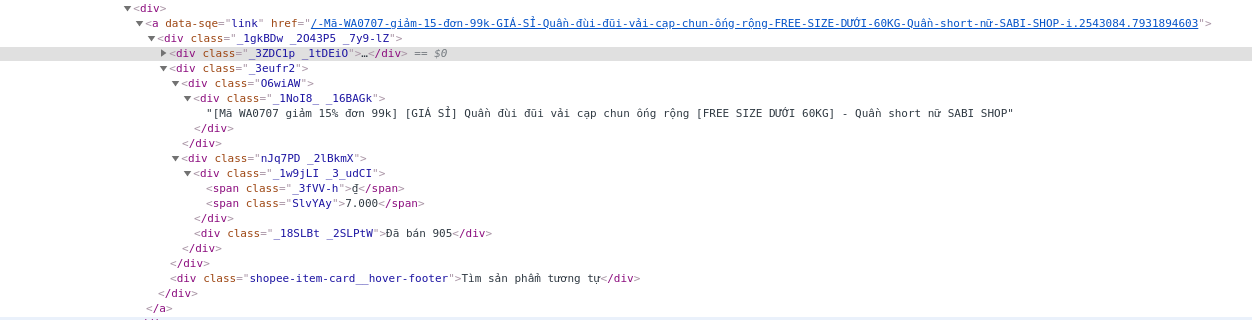
Như ban đầu mình sẽ lấy các giá trị về tên sản phẩm, link sản phẩm, giá, mô tả (tất cả đều nằm trong thẻ <div>), ta sẽ bóc tách như sau:
description = driver.find_elements_by_xpath("//*[@class='shopee-search-item-result']
//*[@class='row shopee-search-item-result__items']//*[@class='col-xs-2-4 shopee-search-item-result__item']
//*[@class='_1gkBDw']//*[@class='_3eufr2']//*[@class='_1NoI8_ _1JBBaM']")
data =[]
for browse in description:
text = browse.text
data.append({"description" : text})
Ý nghĩa là ta sẽ chỉ đường dẫn đến từng giá trị được bọc trong các thẻ HTML. Các bạn có thể xem thêm tại đây. Tương tự như vậy chúng ta sẽ lấy các thuộc tính còn lại.
Khi ta đã lấy được data thì việc tiếp theo là ta sẽ INSERT vào DB PostgreSQL, tạo file data_helpers.py
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "your_name_app.settings") # Tên app bạn tạo ( QUAN TRỌNG ).
django.setup()
from crawl.models import Data # Import Model đã tạo
class DataObject():
def __init__(self):
pass
def create(self, name, link, price, description):
# Ta sẽ insert data bằng phương thức create
return Data.objects.create(name=name, link = link , price = price, description = description)
Cũng nên xem thêm tại đây. Như vậy cũng đã hoàn thành được 90% công việc rồi. Ta sẽ tạo file get_data.py sẽ import các module đã implement bên trên.
from selenium import webdriver
import time
import os
import urllib.request
from data_helper import *
for i in range(1):
urlpage = 'https://shopee.vn/%C3%81o-s%C6%A1-mi-cat.78.2828?page='
driver = webdriver.Firefox(executable_path='/home/to.duc.thang/geckodriver')
driver.get(urlpage + str(i))
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(35)
description = driver.find_elements_by_xpath("//*[@class='shopee-search-item-result']//*[@class='row shopee-search-item-result__items']//*[@class='col-xs-2-4 shopee-search-item-result__item']//*[@class='_1gkBDw']//*[@class='_3eufr2']//*[@class='_1NoI8_ _1JBBaM']")
/*/ TODO: name, prices, link_image,.....
data = []
for browse in description:
text = browse.text
data.append({"description" : text})
for i in data:
try:
description = i["description"]
/*/ TODO :name , link, price,......
# prices = i["prices"]
# name = i["name"]
# link = i["link"]
try:
data = DataObject().create(name=name,link=link, price=prices, description=str(description))
except OSError:
print ("Creation of the image %s failed" % path)
else:
print ("Successfully created the image %s " % path)
except:
pass
driver.quit()
KẾT QUẢ :
Dưới đây là kết quả mình nhận được khi lấy đầy đủ data mình cần.
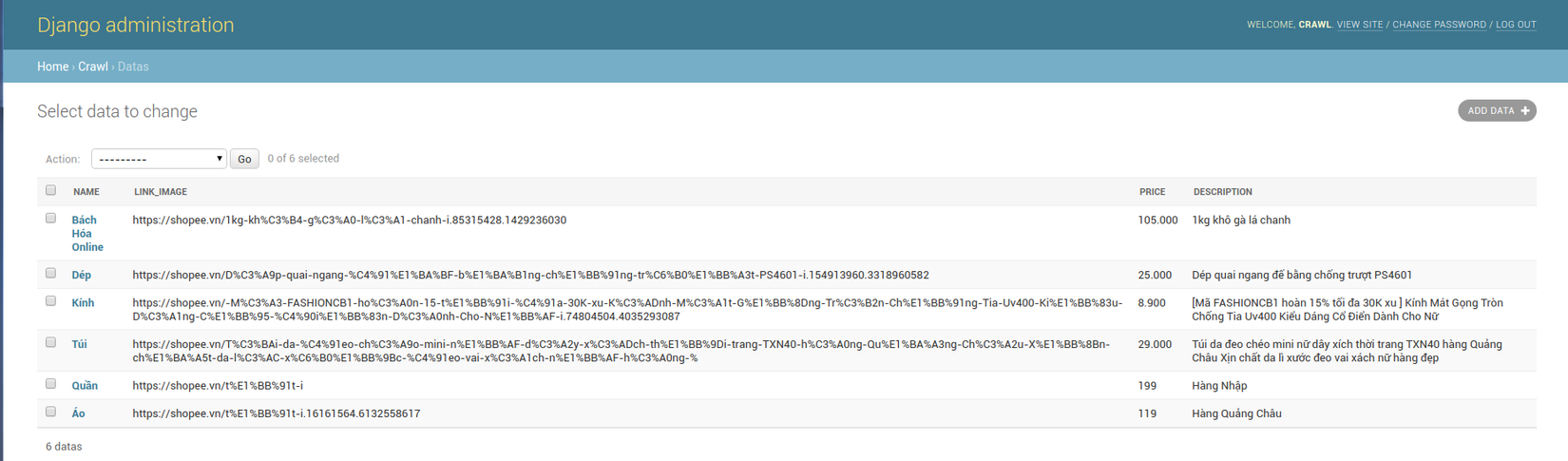
Bạn cũng có thể check bên dưới local . Ngoài ra bạn có thể xem thêm cách viết API cũng sử dụng Django + PostgreSQL tại đây
Bonus
Khi ta đã crawl được link image thì ta có thể save lại hình ảnh vào folder bằng thư viện requests như sau :
import urllib
path = 'home/Desktop/'
number = 0
for i in data :
urllib.request.urlretrieve(link, path + str(number) + ".jpg")
number +=1
Kết quả :
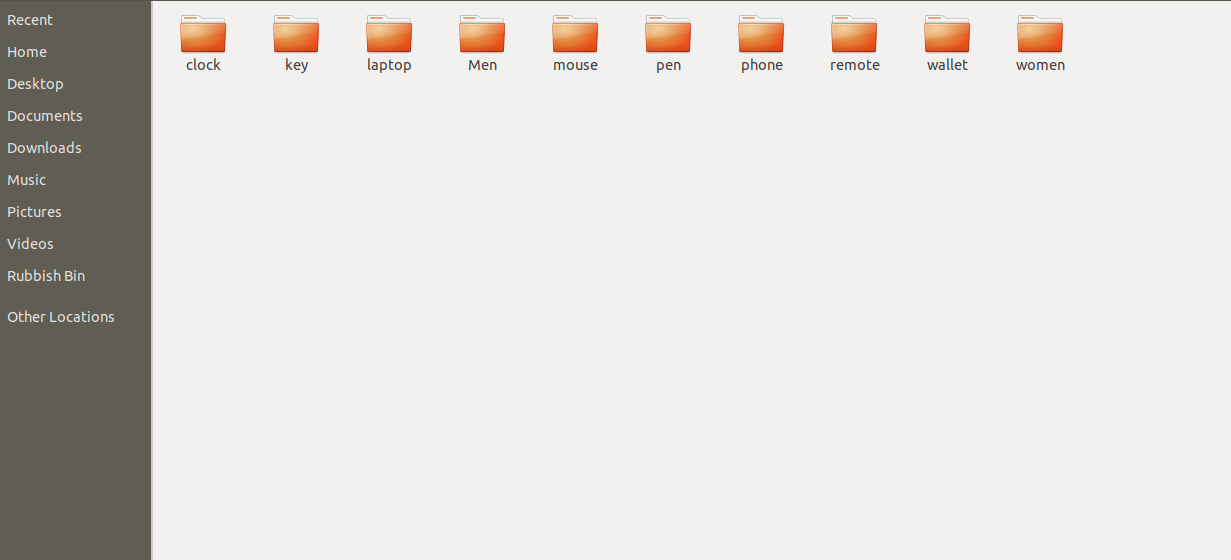
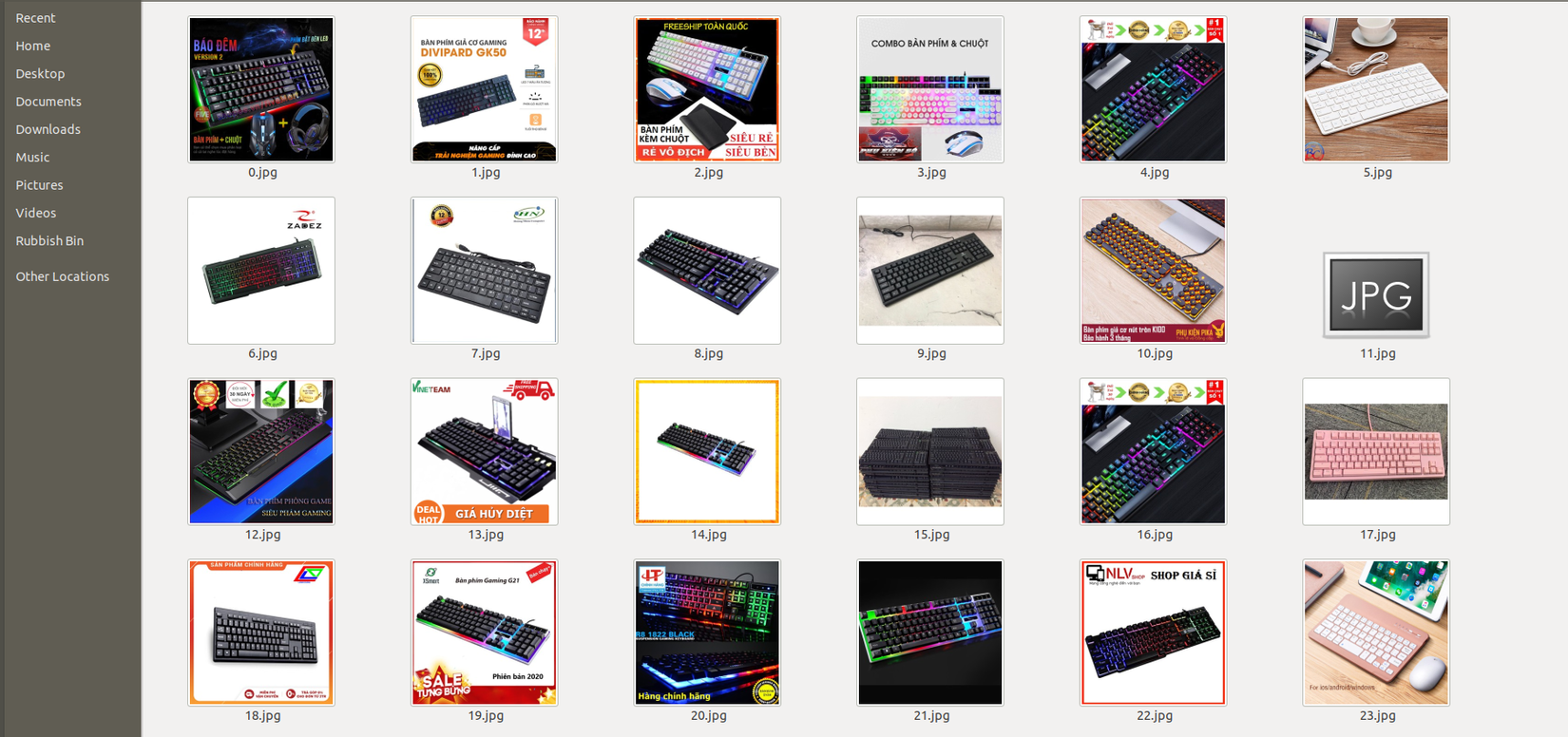
Note :
Nếu có vấn đề gì trong quá trình code các bạn hãy comment bên dưới nhé. Và đừng quên upvote , follow nhé  .
.
Hẹn gặp lại trong bài viết tiếp theo..
Link tham khảo
All rights reserved
