Crawl Data bằng Laravel và Goutte
Bài đăng này đã không được cập nhật trong 6 năm
Giới thiệu
Thuật ngữ cào dữ liệu hay crawl data chắc chắn không còn xa lạ gì mọi người. Nó đơn giản là tự động hóa việc trích xuất thông tin từ một nguồn nào đó, cụ thể ở bài viết này là một website. Công việc này hoàn toàn có thể thực hiện bằng tay, nếu bạn có đủ thời gian và kiên nhẫn. Tuy nhiên để không phải ngồi hàng giờ liền click và copy past, bài viết này sẽ hướng dẫn cách viết một ứng dụng cào dữ liệu đơn giản.
Mục tiêu được (hoặc bị) cào dữ liệu hôm nay là trang bán điện thoại của thế giới di động. Tại link. Dữ liệu sau khi cào sẽ được lưu vào database.
Chuẩn bị
Đầu tiên bạn cần khởi tạo một ứng dụng Laravel và config kết nối đến databasse.
Tiếp đến, chạy đoạn lệnh sau để cài đặt thư viện Goutte
composer require fabpot/goutte
Goutte là một thư viện hỗ trợ việc crawl website rất hiệu quả.
Migrations và Models
Để không làm cho ứng dụng trở nên quá phức tạp, với mỗi sản phẩm, ta chỉ cần lấy 3 thông tin là: tên, giá và số sao được đánh giá. Database tương ứng chỉ có một bảng duy nhất. Chạy lệnh sau để tạo 2 file model và migrations cho bảng products.
php artisan make:model Product -m
Hàm up() trong file migration sẽ có nội dung như sau:
public function up()
{
Schema::create('products', function (Blueprint $table) {
$table->id();
$table->string('name');
$table->integer('price');
$table->integer('rate');
$table->timestamps();
});
}
Đối với model ở file App\Product.php, chúng ta giữ nguyên không cần thay đổi gì. Quá trình khởi tạo cho database kết thúc bằng việc chạy migration. Lưu ý đảm bảo rằng MySQL (hoặc bất cứ database nào các bạn sử dụng) đang chạy và các thông tin kết nối DB ở file .env đã được điền đầy đủ và chính xác.
php artisan migrate
Viết web scraper
Bắt đầu
Bot sẽ không được viết vào controller hay model, thay vào đó, bạn tạo một file mới tại App/Scraper/TGDD.php với nội dung như sau:
<?php
namespace App\Scraper;
use Goutte\Client;
use Symfony\Component\DomCrawler\Crawler;
class TGDD
{
public function scrape()
{
}
}
Tất cả nội dung của web scraper đơn giản mà chúng ta sẽ viết gói gọn ở hàm scrape() này.
Tìm hiểu cấu trúc HTML của website
Muốn cào dữ liệu từ một website, trước tiên ta phải hiểu cấu trúc HTML của website đó được tổ chức thế nào. Điều này cũng đồng nghĩa, nếu có bất kì cập nhật nào của chủ website, làm thay đổi cấu trúc HTML thì scraper của ta có khả năng ở nên vô dụng.
Truy cập vào link, sử dụng dev tool của trình duyệt để kiểm tra các phần tử của website. Chúng ta có một số kết luận như sau:
- Tất cả sản phẩm đều được đặt giữa một unorder list.
<ul class="homeproduct">
// all products
</ul>
- Mỗi sản phẩm là một item của danh sách. Một số sản phẩm nỗi bật còn có thêm class
feature, nhưng ta chỉ lấy những class chung cho tất cả sản phẩm.
<li class="item">
// item info
</li>
- Bên trong mỗi sản phẩm, tên được gói trong cặp thể
<h3>Name</h3> - Mỗi sản phẩm có 2 giá tiền, ở đây ta chỉ chú ý tới giá sau khi giảm được đánh dấu bằng thẻ
<strong>
<div class="price">
<strong>9.990.000₫</strong>
<span>11.490.000₫</span>
</div>
- Rate của sản phẩm thể hiện qua số sao. Với class tương ứng "icontgdd-ystar" là 1 sao, "icontgdd-gstar" là 0 sao, và "icontgdd-hstar" là nửa sao.
<div class="ratingresult">
<i class="icontgdd-ystar"></i>
<i class="icontgdd-ystar"></i>
<i class="icontgdd-ystar"></i>
<i class="icontgdd-gstar"></i>
<i class="icontgdd-gstar"></i>
<span>11 đánh giá</span>
</div>
Lưu ý rằng cấu trúc HTML trên có thể đã thay đổi so với thời điểm bài viết được tạo ra, vì vậy, bạn nên tự mình vào link và tìm tòi. Đây có lẽ là công đoạn thú vị nhất trong toàn bộ quá trình.
Request đến website
Sử dụng Goutte\Client, ta có thể request đến web bằng url của nó và nhận lại một đối tượng thuộc kiểu Symfony\Component\DomCrawler\Crawler.
public function scrape()
{
$url = 'https://www.thegioididong.com/dtdd';
$client = new Client();
$crawler = $client->request('GET', $url);
}
Trích xuất dữ liệu
Với đối tượng $crawler trong tay, để lấy ra thông tin từ website ta viết tiếp hàm scrape với đoạn code sau:
$crawler->filter('ul.homeproduct li.item')->each(
function (Crawler $node) {
$name = $node->filter('h3')->text();
$price = $node->filter('.price strong')->text();
$wholeStar = $node->filter('.icontgdd-ystar')->count();
$halfStar = $node->filter('.icontgdd-hstar')->count();
$rate = $wholeStar + 0.5 * $halfStar;
}
);
Mỗi đôí tượng thuộc Crawler đại diện cho một đối tượng trên website. Ở trong hàm scrape() của chúng ta, $crawler đại diện cho toàn bộ trong web. Hàm filter() chỉ có tác dụng trong phạm vi mà Cralwer đại diện. Nó nhận vào một đoạn CSS selector và trả về một hoặc một danh sách các Crawler ứng với.
Ta tiếp tục chain hàm each() vào sau filter. Hàm này nhận vào một Clouse, mang Closure này áp dụng lên từng phần tử trong danh sách mà filter() trả về trước đó. Đối số của Clouse chính là mỗi phần tử trong danh sách. Ở đây, $node đại diện cho HTML element ứng với mỗi sản phẩm.
Bên trong hàm each, ta dễ dàng trích xuất ra thông tin tên sản phẩm, giá và số sao đánh giá dựa theo CSS selector của nó. Với rating, ta sử dụng hàm count() để đếm số sao mỗi loại và cộng nó vào giá trị cuối cùng.
Lưu ý $price nhận về là một chuỗi có dạng 21.990.000₫. Để chuyển nó về dạng số cần sử dụng một chút regex, như đã được giới thiệu trong bài viết trước.
$price = preg_replace('/\D/', '', $price);
Công việc còn lại đơn giản là lưu lại thông tin vào DB
$product = new Product;
$product->name = $name;
$product->price = $price;
$product->rate = $rate;
$product->save();
Dùng Artisan Console để chạy Web Scraper
Vì việc scraper có thể diễn ra trong một thời gian rất dài, không thể nào gọi hàm scrape() vừa viết ở trên trong controller và request tới app để khởi chạy scraper được. Trong ứng dụng thực thế, việc chạy scraper có thể được tạo bằng việc sử dụng cron job. Tuy nhiên, ở ứng đơn giản này, ta sẽ viết một Command và chạy scraper bằng terminal.
Từ terminal, chạy lệnh:
php artisan make:command ScrapeCommand
Một file ScraperCommand.php sẽ được tạo tại thư mục App/Console/Command. Bạn cần điều chỉnh giá trị biên signature lại như sau, với scrape:tgdd chính là lệnh mình sẽ chạy trên terminal sau này.
protected $signature = 'scrape:tgdd';
Sau đó sửa nội dung của hàm handle như sau
public function handle()
{
$bot = new \App\Scraper\TGDD();
$bot->scrape();
}
Nếu chạy lệnh php artisan list mà nhìn thấy scrape:tgdd ở trong danh sách thì việc tạo Command đã thành công.
Kết quả
Sau khi đã hoàn tất mọi bước trên, bạn có thể tận hưởng thành quả bằng cách chạy lệnh artisan do chính mình viết ra ở bước kế trước. Từ terminal, gõ:
php artisan scrape:tgdd
Kiểm tra database để thấy kết quả.
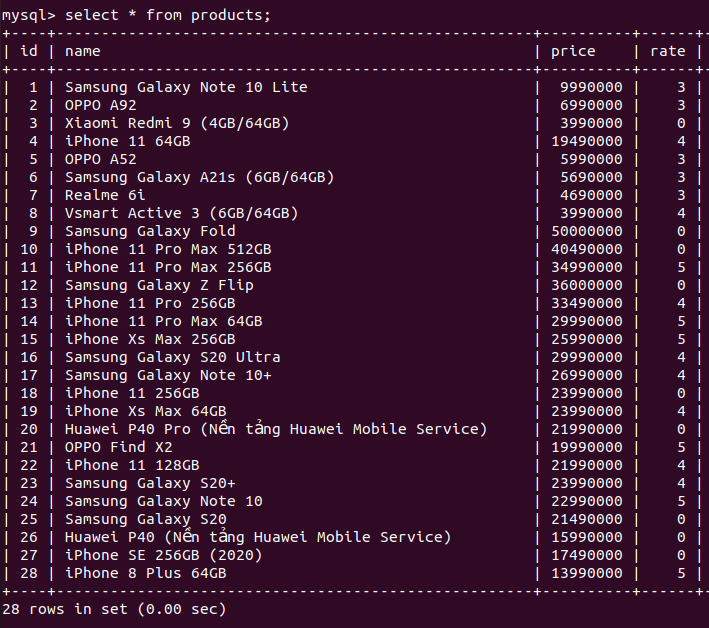
Kết luận
Việc xây dựng web scraper trở nên cực kì đơn giản với Goutte. Bạn có thể tham khảo thêm về Goutte và DomCralwer theo các link bên dưới: Goutte: https://github.com/FriendsOfPHP/Goutte DomCralwer: https://symfony.com/doc/current/components/dom_crawler.html Tuy nhiên, hạn chế của Goutte (và tất cả headless browser nói chung) là các button sử dụng AJAX. Tại thời điểm viết bài này, ở cuối trang web thế giới di động có một button, khi click vào sẽ trigger một hàm Javascript để load thêm sản phẩm. Sử dụng Goutte không thể mô phỏng lại hành động này, vì vậy chỉ có thể scrape được 28 sản phẩm ở trang đầu. Để xử lí vấn đề này, cần dùng một browser simulator như puppeteer của Javascript. Nội dung về puppeteer có thể sẽ được thảo luận ở một bài viết trong tương lai.
Xin cảm ơn.
All rights reserved
