🗄️🧠 Covering Index: Tại Sao Một Query Không Cần Đọc Bảng Vẫn Trả Kết Quả? - Database System Design P5
Covering Index: Tại Sao Một Query Không Cần Đọc Bảng Vẫn Trả Kết Quả?
1. The Production Hook: Câu Chuyện Về Điểm Nghẽn Cuối Cùng
Hãy tưởng tượng bạn đang trực vận hành cho một hệ thống E-commerce lớn trong ngày Mega Sale. Mọi thứ dường như đã được chuẩn bị kỹ lưỡng: Server đã scale, Load Balancer hoạt động tốt, và quan trọng nhất, các Senior Engineer đã rà soát lại toàn bộ SQL, đảm bảo mọi câu lệnh "nặng" nhất đều đã được đánh Index cẩn thận.
Nhưng rồi, một tín hiệu đỏ rực xuất hiện trên Dashboard monitoring.
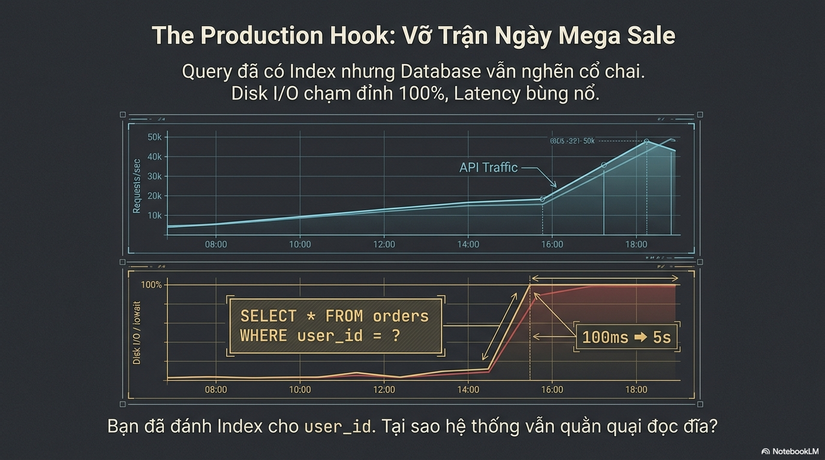
Trang danh sách đơn hàng (Order History) của khách hàng — một API tưởng chừng đơn giản — bắt đầu có Latency tăng vọt từ 100ms lên 2s, rồi 5s. Bạn mở hệ thống quản lý Database và thấy một cảnh tượng kinh hoàng: Disk I/O Utilization chạm ngưỡng 100%, hàng dài các tiến trình đang ở trạng thái iowait. Trong khi đó, throughput (lưu lượng) của các câu lệnh ghi (INSERT/UPDATE) bắt đầu bị kéo sụp theo.
Bạn tự vấn: "Vô lý. Câu lệnh lấy danh sách đơn hàng chỉ lọc theo user_id, và mình đã đánh Index cho user_id rồi. Tại sao Database vẫn phải quằn quại đọc đĩa kinh khủng đến thế?"
Đây chính là khoảnh khắc mà sự khác biệt giữa một "Developer biết dùng Database" và một "System Engineer thực thụ" được phân định. Bạn nhận ra rằng mình đã giúp Database "tìm thấy" dữ liệu, nhưng lại bắt nó phải "đi một quãng đường quá xa" để lấy được dữ liệu đó. Câu hỏi cốt lõi không còn là "Làm sao để tìm nhanh?", mà là: "Tại sao chúng ta phải lục lọi bảng chính một lần nữa khi đã cầm trong tay chiếc chìa khóa?"
2. Common Belief vs. Production Reality: Khi "Có Index" Là Chưa Đủ
Trong giới phát triển phần mềm, có một niềm tin phổ biến đến mức trở thành một "giáo điều": "Chỉ cần cột trong WHERE có index là query sẽ nhanh."
Nếu bạn vẫn đang tin vào điều này, bạn đang nhìn nhận Index chỉ như một công cụ tìm kiếm đơn thuần. Thực tế sản phẩm khốc liệt hơn nhiều. Một Index thông thường (Non-Clustered Index) thực chất là một cấu trúc dữ liệu tách biệt với bảng chính. Nó giống như một cuốn sổ tay nhỏ chứa thông tin: "Giá trị X nằm ở địa chỉ Y trong kho bãi".
Khi bạn thực hiện một câu lệnh như:SELECT status, total_amount FROM orders WHERE user_id = 123;
Giả sử bạn đã có Index trên user_id. Quy trình của Database sẽ diễn ra như sau:

- Tìm trong Index: Database nhanh chóng tìm thấy
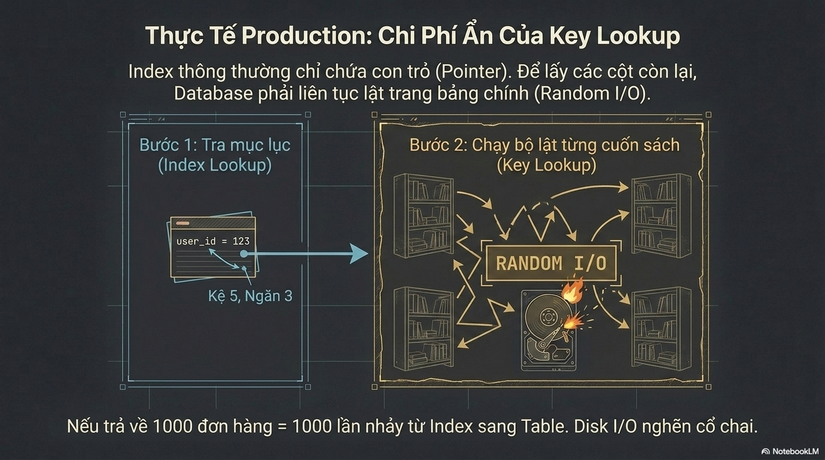
user_id = 123trong cây Index. Tại đây, nó lấy được một thứ gọi là "Pointer" (con trỏ) hoặc "Row ID". - Key Lookup (Lật trang): Vì trong Index chỉ có
user_idvà Pointer, nó không hề biếtstatusvàtotal_amountlà gì. Database buộc phải cầm Pointer đó, nhảy sang bảng chính (Heap hoặc Clustered Index) để đọc toàn bộ dòng dữ liệu đó lên.
Ẩn dụ (Metaphor): Hãy tưởng tượng bạn đi thư viện tìm sách. Bạn tra mục lục (Index) và thấy cuốn "Thiết kế hệ thống" nằm ở Kệ 5, Ngăn 3. Việc tìm ra vị trí này cực nhanh. Nhưng để biết chương 5 viết gì, bạn phải thực sự đi bộ đến Kệ 5, rút cuốn sách ra và lật đến trang đó. Nếu bạn cần xem thông tin của 100 cuốn sách khác nhau, việc "đi bộ" qua lại giữa bàn mục lục và các kệ sách chính là chi phí Random I/O cực lớn khiến bạn kiệt sức.
Trong hệ thống production, mỗi lần "đi bộ" (Key Lookup) đó là một lần truy xuất đĩa ngẫu nhiên. Khi số lượng bản ghi cần trả về lớn (ví dụ 1000 đơn hàng của một user VIP), Database sẽ phải thực hiện 1000 lần nhảy từ Index sang Table. Kết quả là Disk I/O nghẽn cổ chai, CPU tăng cao để quản lý các request I/O này, và Latency bùng nổ.
3. New Perspective: Từ "Tìm Kiếm" Sang "Phục Vụ" (Serving)
Tại TechCraft, chúng tôi không dạy bạn cách tối ưu câu lệnh SQL đơn thuần. Chúng tôi muốn bạn thay đổi tư duy: Từ việc tối ưu đường tìm kiếm (Search Path) sang tối ưu hóa đường đọc (Read Path).
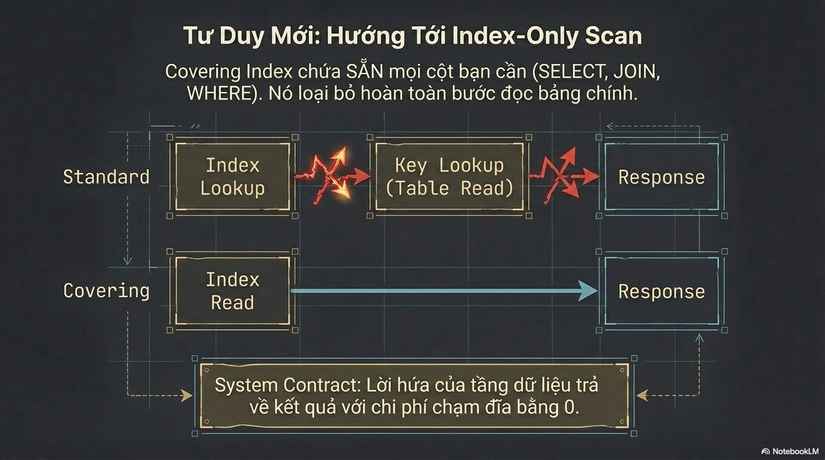
Database không nên chỉ là một kho lưu trữ (Storage). Nó nên được nhìn nhận như một System Contract (Hợp đồng hệ thống). Một Index không chỉ là công cụ hỗ trợ tìm kiếm; nó là một lời hứa của tầng dữ liệu đối với API layer rằng: "Tôi sẽ trả lời yêu cầu này với chi phí thấp nhất có thể."
Đây là lúc khái niệm Covering Index xuất hiện.
Covering Index không phải là một tính năng kỹ thuật cao siêu trong tài liệu của MySQL hay Postgres. Nó là một chiến lược thiết kế Index sao cho: Toàn bộ các cột cần thiết cho một query (nằm trong SELECT, JOIN, WHERE, ORDER BY, GROUP BY) đều hiện diện ngay trong cấu trúc của Index đó.
Khi điều này xảy ra, Database đạt tới một trạng thái gọi là Index-Only Scan. Nó nhận ra rằng: "Ồ, mọi thứ khách hàng cần tôi đều đã cầm trong tay rồi. Tôi không cần phải lật bảng chính ra xem nữa."
Thay vì quy trình: Index Lookup -> Key Lookup -> Table Read -> Response,Quy trình mới chỉ còn: Index Read -> Response.
Đây chính là "trạng thái cực khoái" của hiệu năng query. Bạn đã loại bỏ hoàn toàn bước tốn kém nhất, rủi ro nhất và dễ gây nghẽn nhất trong chu kỳ sống của một câu lệnh SQL.
4. Engineering Thinking: Tại Sao Nó Lại Nhanh Đến Thế?
Để hiểu tại sao Covering Index lại mang lại hiệu năng đột phá, chúng ta cần nhìn sâu vào cấu trúc dữ liệu và cách vận hành vật lý của Database Engine.
Cấu trúc B-Tree và Localized Data
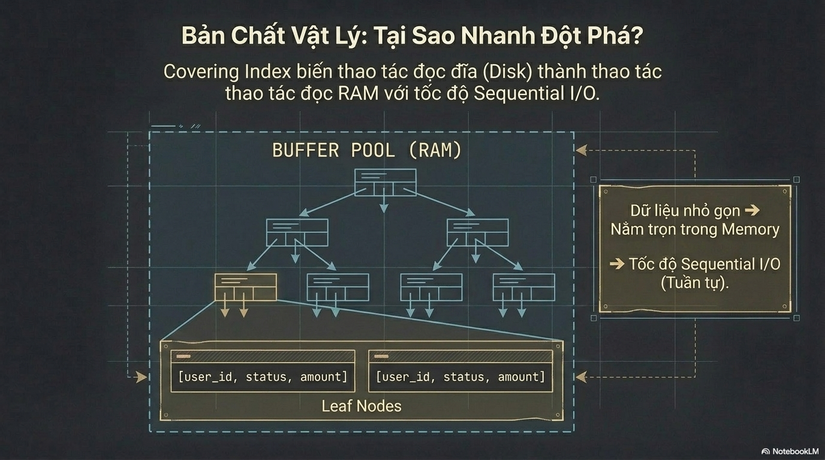
Trong cấu trúc B-Tree của một Index thông thường, các Leaf Nodes (nút lá) chỉ chứa khóa (Key) và địa chỉ vật lý. Với Covering Index (hoặc kỹ thuật INCLUDE trong SQL Server/Postgres), chúng ta chủ động đưa thêm các cột dữ liệu "phụ trợ" vào các nút lá này.
Khi thực hiện Index-Only Scan, Database đọc dữ liệu theo kiểu Sequential I/O (I/O tuần tự) trên các trang của Index. I/O tuần tự nhanh hơn gấp nhiều lần so với Random I/O (I/O ngẫu nhiên) khi phải nhảy đi tìm từng dòng trong bảng chính.
Tác động lên Buffer Pool và RAM
RAM là tài nguyên quý giá nhất của Database. Database Engine sử dụng một vùng đệm gọi là Buffer Pool để lưu các trang dữ liệu từ đĩa lên.
- Với Key Lookup: Database phải load cả trang Index và rất nhiều trang dữ liệu từ bảng chính vào Buffer Pool. Điều này gây ra hiện tượng "loãng" RAM, làm các dữ liệu quan trọng khác bị đẩy ra ngoài.
- Với Covering Index: Database chỉ cần load các trang Index. Vì Index thường nhỏ hơn nhiều so với bảng chính, nó có khả năng nằm hoàn toàn trong RAM (In-memory). Điều này biến một thao tác đọc đĩa thành thao tác đọc RAM với tốc độ ánh sáng.
So sánh chi phí I/O và Tài nguyên hệ thống
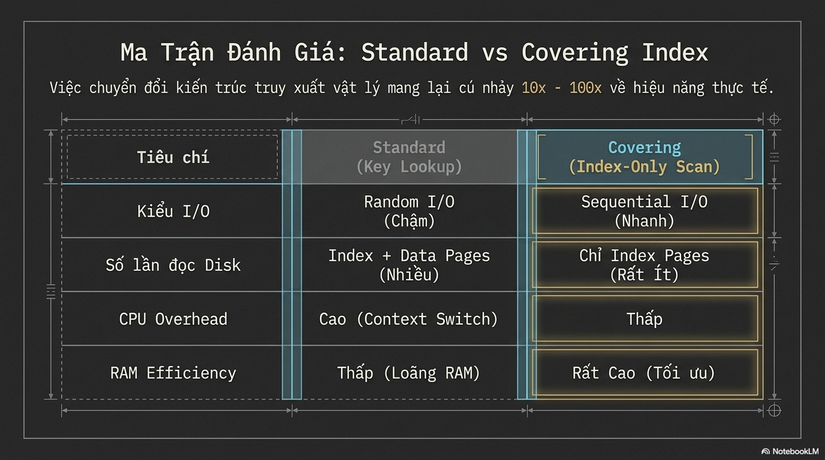
Nhận định từ góc nhìn kiến trúc: Một Index tốt không chỉ giảm bước tìm kiếm; nó thay đổi bản chất vật lý của cách dữ liệu được truy xuất. Việc chuyển từ Random I/O sang Sequential I/O không chỉ là tối ưu 10-20%, nó thường là cú nhảy 10x hoặc 100x về hiệu năng trong môi trường thực tế.
5. Production Cases: Khi Nào Nên "Cover" Toàn Bộ?
Việc tạo Covering Index không miễn phí. Nó đòi hỏi chi phí về bộ nhớ và hiệu năng ghi. Tuy nhiên, trong các hệ thống quy mô lớn (Banking, Payment, Logistics), có những kịch bản mà việc "bao phủ" toàn bộ là một khoản đầu tư mang lại ROI (Lợi nhuận trên đầu tư) cực cao:

1. Hệ thống Ledger & Transaction History (Banking/Fintech)
Khách hàng thường xuyên kiểm tra lịch sử giao dịch. Một bảng giao dịch có thể có 50 cột (meta data, audit logs, provider info), nhưng API lịch sử chỉ cần 5 cột: id, amount, currency, status, created_at.Bằng cách tạo một Covering Index trên (user_id, created_at) INCLUDE (amount, currency, status), bạn giúp hàng triệu user có thể xem lịch sử giao dịch mượt mà mà không làm "rung chuyển" ổ cứng của Database Server.
2. Listing APIs với Pagination (E-commerce/Marketplace)
Các câu lệnh phân trang như LIMIT 20 OFFSET 1000 là cơn ác mộng. Database phải duyệt qua 1020 dòng. Nếu dùng Index thông thường, nó phải thực hiện 1020 lần Key Lookup chỉ để bỏ đi 1000 dòng đầu. Với Covering Index, toàn bộ quá trình "duyệt và bỏ" này diễn ra ngay trong Index ở RAM. Tốc độ trang cuối sẽ nhanh tương đương trang đầu.
3. Real-time Dashboard & Analytics (Logistics/SaaS)
Các query tính tổng (SUM), trung bình (AVG) hay đếm (COUNT) trên một khoảng thời gian dài. Nếu Index đã chứa sẵn các cột định lượng này, Database có thể quét qua hàng triệu bản ghi trong Index nhanh hơn nhiều so với việc quét bảng chính. Điều này giúp các dashboard của quản lý luôn "tươi" (fresh) mà không cần đến các giải pháp Cache phức tạp.
6. The "Cost" & Trade-off Analysis: Không Có Bữa Trưa Miễn Phí
Là một Senior Architect, câu hỏi đầu tiên bạn phải đặt ra khi nghe về một kỹ thuật thần thánh là: "Cái giá phải trả là gì?". Covering Index có 3 cái bẫy chết người mà nếu không cẩn thận, bạn sẽ biến Database thành một "con quái vật" ngốn tài nguyên.

- Write Amplification (Khuếch đại ghi): Đây là rủi ro lớn nhất. Mỗi khi bạn
INSERTmột dòng vào bảng, Database phải cập nhật bảng chính và TOÀN BỘ các Index. Nếu bạn có một Covering Index chứa 10 cột, mỗi lầnUPDATEbất kỳ cột nào trong số đó, Index cũng phải được cập nhật lại. Với các bảng Write-heavy (như bảng Log giao dịch, Tracking), quá nhiều Covering Index sẽ làm sụp đổ throughput của hệ thống ghi. - Storage Bloat (Phình to lưu trữ): Bạn đang thực sự thực hiện "phi chuẩn hóa" (denormalization) dữ liệu ở tầng vật lý. Việc sao chép dữ liệu từ bảng chính sang Index khiến kích thước Database phình to. Điều này dẫn đến hóa đơn Cloud (EBS, RDS Storage) tăng cao và thời gian Backup/Restore hệ thống kéo dài đáng kể.
- Memory Pressure (Áp lực lên Buffer Pool): RAM là hữu hạn. Khi bạn làm Index "béo" lên (Wide Index), số lượng trang Index có thể chứa trong RAM giảm xuống. Nếu bạn lạm dụng, các Index quan trọng khác sẽ bị đẩy xuống Disk, vô tình làm chậm toàn bộ các câu lệnh khác trong hệ thống.
Lời khuyên về "Điểm bão hòa": Một Index trở nên "quá rộng" khi bạn cố nhét những cột có kích thước lớn (như text, varchar(max)) hoặc những cột rất ít khi được query. Hãy chỉ chọn những cột thực sự nằm trong Access Pattern (mẫu truy cập) có tần suất cao nhất.
7. Failure Cases: Những Bài Học Đắt Giá Từ Thực Tế
Tại TechCraft, chúng tôi tin rằng một thất bại trong production có giá trị hơn nghìn bài giảng lý thuyết. Dưới đây là hai câu chuyện "xương máu":
Tình huống 1: "Cái Chết Vì Quá Tham Lam" (Over-indexing)
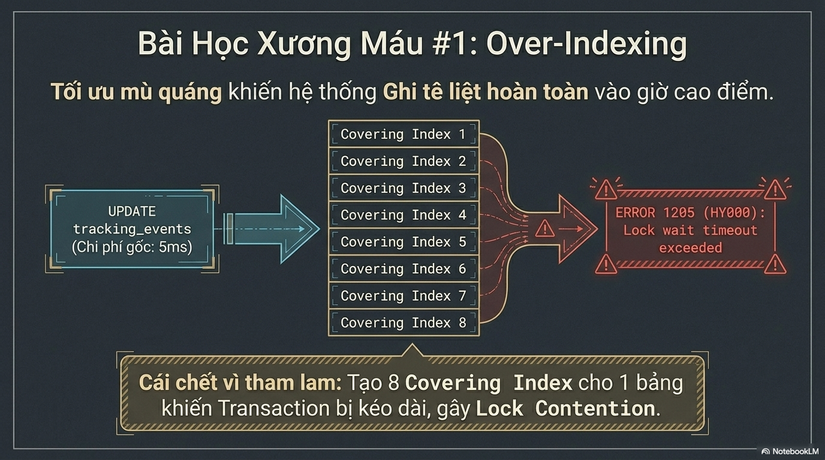
Một hệ thống Tracking cho Logistics muốn mọi query báo cáo đều phải đạt Index-Only Scan. Họ tạo 8 cái Covering Index cho cùng một bảng tracking_events.
- Symptom: Vào giờ cao điểm, khi các shipper đồng loạt cập nhật trạng thái, Database bắt đầu xuất hiện hàng loạt
Lock Wait Timeout. - Root Cause: Việc cập nhật 8 Index cho mỗi lần thay đổi trạng thái khiến một lệnh
UPDATEđơn giản mất tới 200ms thay vì 5ms. Các transaction bị kéo dài, gây ra tình trạng khóa lẫn nhau (Lock contention). - Remediation: Chúng tôi phải xóa bỏ 6 Index, chấp nhận một số query báo cáo chạy chậm hơn (hoặc đẩy sang Replica) để cứu lấy luồng ghi quan trọng nhất của doanh nghiệp.
Tình huống 2: "Sai Một Ly, Đi Một Dặm" (Wrong Column Order)
Một team Backend tạo Covering Index trên (status, user_id, total_amount). Họ đinh ninh rằng query nào có user_id cũng sẽ nhanh vì đã có Index "che phủ".

- Symptom: Query
WHERE user_id = Xvẫn chậm như rùa và Disk I/O vẫn cao. - Root Cause: Theo nguyên tắc tiền tố (Leftmost Prefix) của B-Tree, nếu query không lọc theo
status(cột đầu tiên của Index), Database không thể dùng Index để tìm kiếm hiệu quả. Nó buộc phải quét toàn bộ Index (Full Index Scan) hoặc quay về quét bảng chính. - Lesson: Covering Index chỉ phát huy tác dụng khi nó phục vụ đúng Access Pattern. Thứ tự cột vẫn là yếu tố quyết định hàng đầu trước khi nói đến chuyện "che phủ".
8. Senior Engineer Lens: Cách Tiếp Cận Có Chiến Lược
Đừng bắt đầu bằng việc tạo Index. Hãy bắt đầu bằng việc hiểu Access Pattern. Một Senior Engineer không bao giờ tối ưu hóa mù quáng; họ tối ưu hóa dựa trên dữ liệu thực tế.
Trước khi quyết định nâng cấp một Index thông thường thành Covering Index, hãy chạy qua "Pre-flight Checklist" gồm 3 câu hỏi sau:

- Tần suất query này có đủ cao để xứng đáng với chi phí ghi không? Nếu query chỉ chạy trong các báo cáo cuối ngày của Admin, hãy để nó Key Lookup. Nếu nó là API trang chủ của hàng triệu user, hãy Cover nó ngay lập tức.
- Độ chọn lọc (Selectivity) như thế nào? Nếu query của bạn lọc ra 50% dữ liệu của bảng, Database sẽ chọn Full Table Scan vì nó nhanh hơn dùng Index. Trong trường hợp này, Covering Index là vô nghĩa.
- Tác động tới Business Flow chính là gì? Nếu bảng này thuộc module thanh toán (thứ cần ghi cực nhanh và đúng), hãy cực kỳ dè dặt khi thêm Covering Index. Nếu bảng này thuộc module hiển thị (thứ cần đọc cực nhanh), hãy ưu tiên nó.
9. Key Takeaways & Open Loop
Để làm chủ tầng dữ liệu, hãy ghi nhớ 4 điểm cốt lõi về Covering Index:

- Nó không chỉ là tìm kiếm: Covering Index chuyển đổi mục tiêu từ "tìm thấy địa chỉ" sang "phục vụ dữ liệu ngay lập tức".
- Loại bỏ Random I/O: Mục tiêu tối thượng là đạt được Index-Only Scan, đưa toàn bộ thao tác đọc về Sequential I/O và RAM.
- Kỷ luật về Trade-off: Luôn cân nhắc giữa lợi ích của người đọc (Read latency) và nỗi đau của người ghi (Write amplification).
- Hệ thống tiến hóa: Không có Index nào là vĩnh cửu. Khi Business thay đổi, Access Pattern thay đổi, cấu trúc Index của bạn cũng phải tiến hóa theo.
Open Loop: Chúng ta đã nói rất nhiều về việc Database "làm gì" bên dưới. Nhưng làm sao bạn biết chắc chắn 100% rằng Database đang thực sự dùng Index-Only Scan hay nó đang lén lút thực hiện hàng triệu lần Key Lookup dưới nền? Làm sao để đọc được "ý định" của Database Engine trước khi nó gây ra sự cố?
Câu trả lời nằm ở "bản đồ thực thi" của hệ thống. Hẹn gặp lại các bạn ở Episode 06: Execution Plan (EXPLAIN): Cách Đọc Query Plan Để Biết Database Đang Nghĩ Gì.
🎯 Dành cho những Developer muốn đi xa hơn
Viết được tính năng chỉ là điểm khởi đầu.
Khi hệ thống ngày càng lớn, những bài toán về hiệu năng, tính đúng đắn của dữ liệu, khả năng mở rộng và các trade-off trong kiến trúc mới là điều tạo nên sự khác biệt giữa một Developer và một System Engineer.
Nếu bạn muốn tiếp tục khám phá những chủ đề đó, hãy tham gia cùng TechCraft thông qua Dev Insider.
🚀 Dev Insider
https://www.patreon.com/techcraft_official/posts/vi-sao-dev-ra-161163881?collection=2220113
📘 Facebook
https://www.facebook.com/techcraft.official
🎥 YouTube
https://www.youtube.com/@techcraft.official
🎵 TikTok
https://www.tiktok.com/@techcraft.official
Build Systems. Not Just Features.
All rights reserved
