Core data investigate
Bài đăng này đã không được cập nhật trong 4 năm
What is core data?
- Is an object graph and persistence framework provied by Apple in MacOSX and iOS operating systems.
- It allows data organised by relational entity- attribute model to be serialised into XML, binary, Sqlite stores.
- Core data directly with SQLite
- Core data handles many of the duties of the data model. Among other tasks, it handles change management, serializing to disk, memory footprint minimization, and quires against the data.
- More informatio here :https://developer.apple.com/library/ios/documentation/Cocoa/Conceptual/CoreData/ cdProgrammingGuide.html#//apple_ref/doc/uid/TP30001200-SW1
**What Is a Fault? **
Core Data faults are similar to virtual memory page faults. Faulted objects are scoped objects that may or may not actually be in memory, or “realized,” until you actually use them. Although there is no guarantee for when a faulted NSManagedObject will be loaded into memory, it is guaranteed to be loaded when accessed. However, the object will be an instance of the appropriate class (either an NSManagedObject or the designated subclass), but its attributes are not initialized.
What Is a not core data?
- Having given an overview of what Core Data is and does, and why it may be useful, it is also useful to correct some common misperceptions and state what it is not.
- Core Data is not a relational database or a relational database management system (RDBMS).Core Data provides an infrastructure for change management and for saving objects to and retrieving them from storage. It can use SQLite as one of its persistent store types. It is not, though, in and of itself a database. (To emphasize this point: you could for example use just an in-memory store in your application. You could use Core Data for change tracking and management, but never actually save any data in a file.)
- Core Data is not a silver bullet.Core Data does not remove the need to write code. Although it is possible to create a sophisticated application solely using the Xcode data modeling tool and Interface Builder, for more real-world applications you will still have to write code.
- Core Data does not rely on Cocoa bindings.Core Data integrates well with Cocoa bindings and leverages the same technologies—and used together they can significantly reduce the amount of code you have to write—but it is possible to use Core Data without bindings. You can readily create a Core Data application without a user interface (see a target="_self" Core Data Utility Tutorial/a).
I. NSManagedObjectModel
1. What is it?
The NSManagedObjectModel can be considered a compiled, binary version of the data model that we create in Xcode. When we say that we are manipulating the object model, we mean we are editing the source file in Xcode that will compiled and used by the NSManagedObjectModel. From a database perspective, this file represents the schema of the database. In Xcode, this file is shown in two different styles
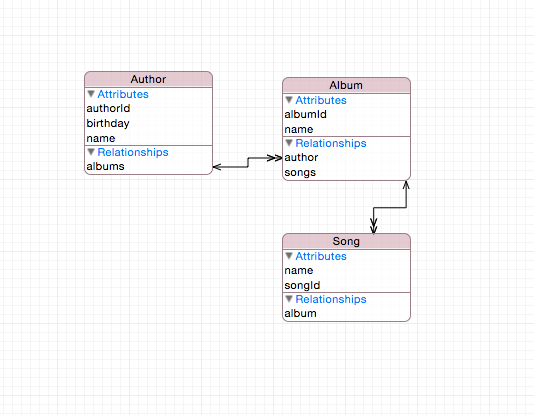
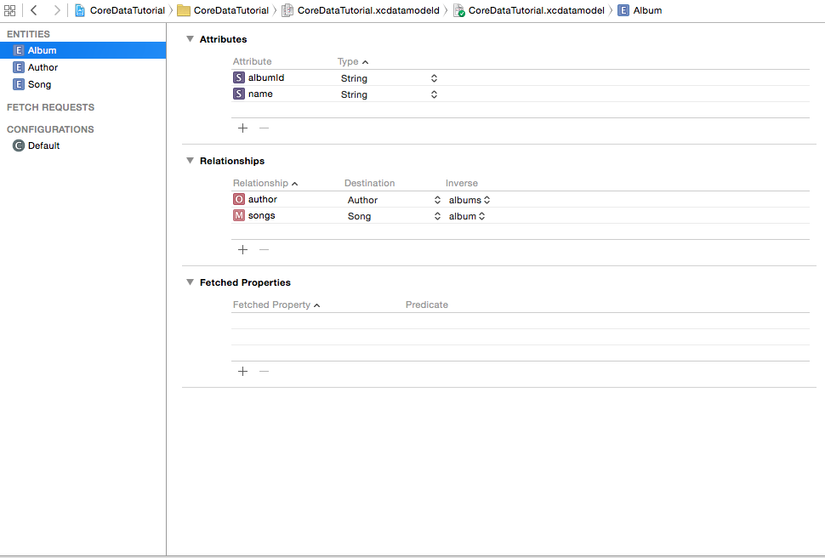
- We can switch between 2 style easy with Xcode tool at the bottom right of model editor.
- At its most basic level, Core Data is an object graph designed to manage data objects. It is common when you are first approaching Core Data to think of it as an object-relational mapping framework—and in truth, it can be used as such. However, that is not the best approach.
- With that in mind, the NSManagedObjectModel—and, by extension, the associated source file in the object model—is what we think of when we need to change the object model. The source file is saved as an .xcdatamodel file. In Xcode this is actually a bundle with an XML document stored inside.
- Xcode understands how to compile this file. When Xcode encounters this file during the compile process of a project, it compiles it into a binary form ending with the extension .mom. We can also build this file from the command line using the momc tool.
2. How to load data model?
(void) initialCoredata{
//CoreDataTutorial : This is name of your model file
NSURL *modelURL = [[NSBundle mainBundle] URLForResource:@"CoreDataTutorial" withExtension:@"momd"];
NSManagedObjectModel *mom = nil;
mom = [[NSManagedObjectModel alloc] initWithContentsOfURL:modelURL];
//We again verify that everything worked correctly by checking the new instance against nil.
if (mom != nil) {
//next stop to initial core data.
}
}
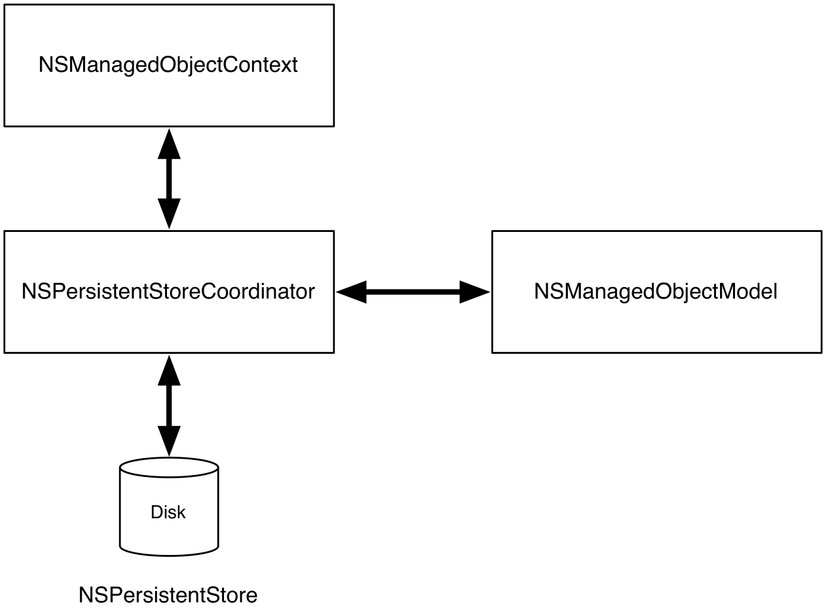
**II- NSPersistentStore ** - Representation of a location in which the data is saved/persisted - You shouldn’t subclass this class. Core data only support subclassing of NSAtomicStore and NSIncrementalStore. - The NSPersistentStore is responsible for describing the file format used. This file format can be one of several: SQLite, binary, or atomic. (There’s also an XML store for OS X, but do not recommend using it because it is not available on iOS, nor does it perform very well.)
**II - NSPersistentStoreCoordinator **
-
The NSPersistentStoreCoordinator is the true maestro of Core Data. The NSPersis- tentStoreCoordinator is responsible for persisting, loading, and caching data. Think of the NSPersistentStoreCoordinator as the heart of Core Data. Having said this, we do very little work with the NSPersistentStoreCoordinator directly. We work with it upon initialization, but we almost never touch it again over the life of the application
-
NSPersistentStoreCoordinator *psc = nil; psc = [[NSPersistentStoreCoordinator alloc] initWithManagedObjectModel:mom];
-
In this first bit of code, we initialize the NSPersistentStoreCoordinator and pass it the NSManagedObjectModel that we previously initialized. This call returns imme- diately, and therefore we can do it inline as part of the start-up of the application.
-
We can adding one or more NSPersistentStore instances to the NSPersistentStoreCoordinator. But we unknown amount of time, and addition of NSPersistentStore can delay the launch of the application to the point of providing a poor user experience or, worse, being terminated by the operating system. To avoid either of these situations, we want to add the NSPersistentStore on a background queue so that the application can finish launching while we perform our start-up.
dispatch_queue_t queue = NULL; queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0); dispatch_async(queue, ^{ NSFileManager *fileManager = [NSFileManager defaultManager]; NSArray *directoryArray = [fileManager URLsForDirectory:NSDocumentDirectory inDomains:NSUserDomainMask]; NSURL *storeURL = nil; storeURL = [directoryArray lastObject]; storeURL = [storeURL URLByAppendingPathComponent:@"CoreDataTutorial.sqlite"]; NSError *error = nil; NSPersistentStore *store = nil; store = [psc addPersistentStoreWithType:NSSQLiteStoreType configuration:nil URL:storeURL options:nil error:&error]; if (!store) { ALog(@"Error adding persistent store to coordinator %@\n%@", [error localizedDescription], [error userInfo]); //Present a user facing error }
III- NSManagedObjectContext - NSManagedObjectContext is the object in the Core Data stack that we’ll most often access. The NSManagedObjectContext is the object we access when we want to save to disk, when we want to read data into memory, and when we want to create new objects - NSManagedObjectContext isn’t thread-safe. Each thread that needs access to the data should have its own NSManagedObjectContext. This is generally not an issue, since most applications are not multithreaded or their multithreaded portions do not need to interact with NSManagedObjectContext on any thread other than the main thread. However, it is important to keep in mind that, like the UI, NSManagedObjectContext should be accessed only on the thread that created it, which is generally the main thread.
NSManagedObjectContext *moc = nil;
NSManagedObjectContextConcurrencyType ccType = NSMainQueueConcurrencyType;
moc = [[NSManagedObjectContext alloc] initWithConcurrencyType:ccType];
[moc setPersistentStoreCoordinator:psc];
- For now, we will be constructing an NSMainQueueConcurrencyType NSManagedObjectContext. That parameter tells Core Data that the NSManagedObjectContext we are initializing can be used only from the main (UI) queue of our application. Once the NSManagedObjectContext has been initialized, we only need to set the NSPersistentStoreCoordinator that it is going to access. From there, it is ready to be used.
**IV-NSManagedObject ** - The NSManagedObject is the object we work with the most in a Core Data appli- cation. Each instance of the NSManagedObject represents one entity in our Core Data repository. This one object can dynamically represent any object that we need and that we need and that can be defined in our data model. - All of the properties and relationships defined in our data model are available and are easy to access directly from the NSManagedObject. Without subclassing it, we can access values associated with an NSManagedObject in the following ways.
1. Accessing Attributes - Attributes are the easiest to access. By utilizing KVC, we can get or set any attribute on the NSManagedObject directly - When we want to subclass NSManagedObject, we can also define properties for the attributes (and relationships discussed in a moment) so that we can access them directly. In the header of our subclass, we would define the properties normally. @class NSManagedObject;
@interface Album : NSManagedObject
@property (nonatomic, retain) NSString * name;
@property (nonatomic, retain) NSString * albumId;
@property (nonatomic, retain) NSManagedObject *author;
@property (nonatomic, retain) NSSet *songs;
@end
@interface Album (CoreDataGeneratedAccessors)
- (void)addSongsObject:(NSManagedObject *)value;
- (void)removeSongsObject:(NSManagedObject *)value;
- (void)addSongs:(NSSet *)values;
- (void)removeSongs:(NSSet *)values;
@end
@implementation Album
@dynamic name;
@dynamic albumId;
@dynamic author;
@dynamic songs;
@end
- By declaring them as @dynamic, we are telling the compiler to ignore any warnings associated with these properties because we “promise” to generate them at runtime. Naturally, if they turn up missing at runtime, our application is going to crash. However, when we are working with NSManagedObject objects, the attributes will be looked up for us, and we do not need to implement anything.
2. Subclass NSManagedObject - Although NSManagedObject provides a tremendous amount of flexibility and handles the majority of the work a data object normally does, it does not cover every possibility, and there are occasions where we might want to sub- class it. Subclassing to gain @property access to attributes and relationships is one common situation, but we may also want to add other convenience methods or additional functionality to the object. When such a situation arises, there are some general rules to remember.
**2.1. Methods That Are Not Safe to Override **
-primitiveValueForKey:
-hash
-self
-isKindOfClass:
-respondsToSelector:
-autorelease
-entity
-isUpdated
-alloc
-setPrimitiveValue:forKey:
-superclass
-zone
-isMemberOfClass:
-retain
-retainCount
-objectID
-isDeleted
-allocWithZone:
-isEqual:
-class
-isProxy:
-conformsToProtocol:
-release
-managedObjectContext
-isInserted
-isFault
+new
+instancesRespondToSelector: +instanceMethodForSelector: -methodForSelector:
-methodSignatureForSelector: -isSubclassOfClass:
**2.2 initXXX ****
- The first is -initXXX. There is really no reason or benefit to overriding the -init methods of an NSManagedObject, and there are situations in which doing so has unpredictable results. Although it is not specifically against the documentation
- to override the -init methods, I recommend strongly against it. The -awakeFromIn- sert and -awakeFromFetch methods provide sufficient access that overriding -init is unnecessary.
2.3 KVO Methods
- I’d also add all of the KVO methods. The documentation flags these methods as “discouraged,” but I’d put them right in the “do not subclass” list. There is no reason to override these methods, and any logic that you would want to put into them can probably be put somewhere else with fewer issues.
2.4 Description
- In addition, there’s the -description method, used fairly often in logging. It is a great way to dump the contents of an object out to the logs during debugging.
2.5. Dealloc
- dealloc is normally the place that we release memory before the object is being freed. However, when we are dealing with NSManagedObject objects, it is possible that the object will not actually be released from memory when we think it will. In fact, the -dealloc method may never get called in the life cycle of our application! Instead of releasing objects in the -dealloc method, I recommend using -didTurnIntoFault as the point of releasing transient resources. -didTurnIntoFault will be called whenever the NSManagedObject is “faulted,” which occurs far more often than the object actually being removed from memory.
2.6 Finalize
- finalize is on the list for the same reason as -dealloc. When dealing with NSMan- agedObject objects, -finalize is not the proper point to be releasing resources.
**2.7 Methods to Override **
-With the long list of methods that we should not override, what methods should we consider overriding? There are a few methods we will commonly override.
**-didTurnIntoFault **
This method is called after the NSManagedObject has been turned into a fault. It is a good place to release transient resources. One important thing to note is that when this method is called, all the stored values/relationships in the NSManagedObject are already out of memory. If you access any of them, it will fire the fault and pull them all back into memory again.
**-willTurnIntoFault **
- Similar to -didTurnIntoFault, this method is called just before the NSManagedObject is turned into a fault. If your code needs to access attributes or relationships on the NSManagedObject before it is turned into a fault, then this is the entry point to use. Transient resources that impact attributes and relationships should be released here.
**-awakeFromInsert **
As mentioned, overriding any of the -init methods is risky and unnecessary. However, it is very useful to be able to prepare an NSManagedObject before it starts accepting data. Perhaps we want to set up some logical defaults or assign some relationships before handing the object to the user. In these sit- uations, we use -awakeFromInsert. As the name implies, this method is called right after the NSManagedObject is created from an insert call. This method is called before any values are set and is a perfect opportunity to set default values, initialize transient properties, and perform other tasks that we would normally handle in the -init method. This method is called exactly once in the entire lifetime of an object. It will not be called on the next execution of the application, and it will not be called when an object is read in from the persis- tent store. Therefore, we do not need to worry about overriding values that have been set previously. When we override this method, we should be sure to call [super awakeFromInsert] at the very beginning of our implementation to allow the NSManagedObject to finish anything it needs to before we begin our code.
-awakeFromFetch awakeFromFetch is the counterpart to -awakeFromInsert. The -awakeFromFetch method will be called every time the object is retrieved from the persistent store (that is, loaded from disk). This method is highly useful for setting up transient objects or connections that the NSManagedObject will use during its life cycle. At this point in the creation of the NSManagedObject, the observation of changes to the object (or other objects) is turned off, and Core Data will not be aware of any changes made. Ideally, we should avoid making any changes to rela- tionships during this method because the inverse will not be set. However, if we explicitly set both sides of the relationship, it is possible to make changes here. Like the -awakeFromInsert method, when we override this method, we should call [super awakeFromFetch]; before any of our own code is called.
**V - NSFetchRequest **
NSFetchRequest is the part of Core Data that causes people to think it is a database API instead of an object hierarchy. When we want to retrieve objects from Core Data, we normally use an NSFetchRequest to do the retrieval. It is best to view an NSFetchRequest as a way to retrieve all instances of an entity from the object hierarchy, with the option to filter the results with an NSPredicate. There are two parts to the creation of an NSFetchRequest: setting the entity to be retrieved and optionally defining an NSPredicate to filter the objects we want retrieved.
**1. Setting the Entity **
One thing that we must do as part of every NSFetchRequest is define the entity we want returned from the fetch. We do this by passing the appropriate NSEntityDescription to the NSFetchRequest.
example: If you want to retrieve Author entities. We construct the NSFetchRequest as follows.
NSManagedObjectContext *moc = [self managedObjectContext]; NSFetchRequest *request = [[NSFetchRequest alloc] init]; [request setEntity:[NSEntityDescription entityForName:@“Author”
inManagedObjectContext:moc]];
**2. Executing a Fetch Request **
NSError *error = nil;
NSArray *results = [moc executeFetchRequest:request error:&error]; if (error) {
NSLog(@"Error: %@\n%@", [error localizedDescription], [error userInfo]);
return; }
**VI -NSPredicate **
When we don’t want every instance of an entity returned, we use an NSPredicate to narrow the search or filter the results. The NSPredicate class is quite complex and powerful and can be used for more things than just Core Data. It is fre- quently used to filter the results of collection classes by acting on the KVC API and doing logic checks on the objects contained in the NSArray or NSSet. One of the most common ways to use an NSPredicate is to construct a SQL-like query, such as the following example:
NSManagedObjectContext *moc = [self managedObjectContext]; NSFetchRequest *request = [[NSFetchRequest alloc] init]; [request setEntity:[NSEntityDescription entityForName:@“Author”
inManagedObjectContext:moc]];
NSPredicate *predicate = [NSPredicate predicateWithFormat:@“authorId = xxxxx”];
[request setPredicate:predicate];
There are many different ways to build an NSPredicate. The one shown in the previous example accepts a SQL-like NSString and can accept any number of parameters after the NSString.
**1. Stored Fetch Requests **
In addition to constructing the NSFetchRequest directly in code, it is possible to build them within the data model and store them for later use. By storing the fetch requests within the model itself, it is possible for us to change them as needed without having to go through all the code looking for every place that it is used. Simply changing it in the model will automatically update wherever it is being used. To store an NSFetchRequest within the data model, we select the entity that we want to run the request against and choose Design > Data Model > Add Fetch Request from the main menu.
**VII- NSSortDescriptor **
NSSortDescriptor has been around longer than Core Data, and it is still quite useful for ordering data. As mentioned previously, data that comes from a to-many relationship is unordered by default, and it is up to us to order it. For example, if we wanted to retrieve all the recipes and sort them by their name property in alphabetical order, we would require an additional step as part of the fetch. NSFetchRequest *fetchRequest = nil; fetchRequest = [NSFetchRequest fetchRequestWithEntityName:@“Author”]; NSSortDescriptor *sort = [[NSSortDescriptor alloc] initWithKey:@"name" ascending:YES]; [fetchRequest setSortDescriptors:[NSArray arrayWithObject:sort]];
**VIII- Performance Tuning **
1. Persistent Store Types
Four types of repositories are included with the Core Data API: SQLite, XML, binary, and in-memory. (XML is available only on OS X, not on iOS.) In- memory is technically not a persistent store because it is never written out to disk. Binary is effectively a serialized version of the object graph written out to disk. The XML store writes out the object graph to a human-readable text file, and SQLite stores the object graph in a relational database. When working with an iOS project, it is common to just use SQLite unless there is a very specific reason to use one of the other store formats. ** a. Atomic Stores **
- Atomic stores include XML, binary, and custom data stores. All of these stores are written to disk atomically; in other words, the entire data file is rewritten on every save. Although these store types have their advantages, they do not scale as well as the SQLite store. In addition, they are loaded fully into memory when they are accessed. This causes atomic stores to have a larger memory footprint than a SQLite store.
- However, because they reside completely in memory while the application is running, atomic stores can be very fast, since the disk is hit only when the file is read into memory and when it is saved back out. SQLite, although still considered a fast store, is slower when dealing with smaller data sets because of its inherent disk access. The differences are measured in fractions of a second, so we cannot expect a dramatic speed increase by using an atomic store. But if fractions of a second matter, it may be something to consider.
**b. SQLite Persistent Store **
- In the most common cases, SQLite is the store option to use for application development. This is true on both iOS and OS X. SQLite is a software library that implements a self-contained, server-less, zero-configuration, transactional SQL database engine. SQLite is the most widely deployed SQL database engine in the world. The source code for SQLite is in the public domain.
**c. Better Scaling **
By utilizing a relational database as the persistent store, we no longer need to load the entire data set into memory to work with it. Because the data is being stored in a relational database, our application can scale to a very large size. SQLite itself has been tested with data sets measured in terabytes and can handle just about anything that we can realistically develop. Since we are loading only the data we want at a particular moment, SQLite keeps the memory footprint of our application quite low. Likewise, SQLite makes efficient use of its disk space and therefore has a small footprint on disk as well.
d. More Performance-Tuning Options
By working with a database instead of a flat file, we have access to many more performance-tuning options. For example, we can index the columns within our entities to enable faster predicates. We can also control exactly what gets loaded into memory. It is possible to get just a count of the objects, just the unique identifiers for objects, and so on. This flexibility allows us to tune the performance of our application more than any other store type. Because the SQLite store is the only format that is not fully loaded into memory, we get to control the data flow. All of the other formats require that the entire data file be loaded into memory before they can be used ** 2. Optimizing Your Data Model **
-
When we design our data model, we need to consider several factors. Where we put our binary data can be extremely important because its size and storage location plays a key role in the performance of our application. Like- wise, relationships must be carefully balanced and used appropriately. Also, entity inheritance, a powerful feature of Core Data, must be used with a del- icate thand because the underlying structure may be surprising.
-
Although it is easy to think of Core Data as a database API, we must remember that it is not and that structuring the data with data normalization may not yield the most efficient results. In many cases, denormalizing the data can yield greater performance gains.
**a. Where to Put Binary Data **
-
One of the easiest ways to kill performance in a Core Data application is to stick large amounts of binary data into frequently accessed tables
For example, if we were to put the pictures of our recipes into the recipe table, we would start seeing performance degradation after only a couple hundred recipes had been added. Every time we accessed a Recipe entity, we would have to load its image data, even if we were not going to display the image. Since our application displays all the recipes in a list, this means every image would reside in memory immediately upon launch and remain there until the application quit. Imagine this situation with a few thousand recipes! But where do we draw the line? What is considered a small enough piece of binary data to fit into a table, and what should not be put into the repository at all?
If you are developing an application that is targeting iOS 6.0 or greater (or Mac OS X 10.8 or greater), the answer is simple: turn on external binary storage in the model and let Core Data solve the problem for you
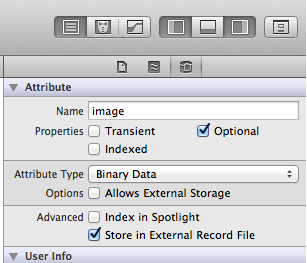
This feature instructs Core Data to determine how to store binary data. With this flag on, Core Data decides whether the image is small enough to store inside of the SQLite file or whether it is too big and therefore should be stored on disk separately. In either case, the decision is an implementation detail from the perspective of our application. We access the binary data just like any other attribute on the entity.
**Small Binary Data **
Anything smaller than 100 kilobytes is considered to be small binary data. Icons or small avatars are a couple examples of data of this size. When working with something this small, it is most efficient to store it directly as a property value in its corresponding table. The performance impact of binary data this size is negligible. The transformable attribute type is ideal for this use.
Medium Binary Data Medium binary data is anything larger than 100 kilobytes and smaller than 1 megabyte in size. Average-sized images and small audio clips are a few examples of data in this size range. Data of this size can also be stored directly in the repository. However, the data should be stored in its own table on the other end of a relationship with the primary tables. This allows the binary data to remain a fault until it is actually needed. In the previous recipe example, even though the Recipe entity would be loaded into memory for dis- play, the image would be loaded only when it is needed by the UI.
SQLite has shown itself to be quite efficient at disk access. There are cases where loading data from the SQLite store can actually be faster than direct disk access. This is one of the reasons why medium binary data can be stored directly in the repository.
**Large Binary Data **
Large binary data is anything greater than 1 megabyte in size. Large images, audio files, and video files are just some examples of data of this size. Any inary data of this size should be stored on disk as opposed to in the reposi- tory. When working with data of this size, it is best to store its path information directly in the primary entity (such as the Recipe entity) and store the binary data in a known location on disk (such as in the Application Support subdi- rectory for your application).
b. Entity inheritance
is a very powerful feature within Core Data. It allows you to build an object-like inheritance tree in your data model. However, this feature comes at a rather large cost. For example, let’s look at an example model that makes moderate use of entity inheritance, as shown here:

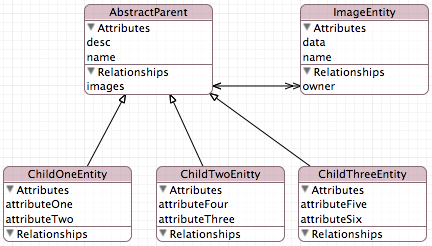
The object model itself looks quite reasonable. We are sharing name, desc, and a one-to-many relationship to the ImageEntity. However, the underlying table structure actually looks like this:
The reason for this is how Core Data handles the object model to relational table mapping. Instead of creating one table for each child object, Core Data creates one large table that includes all the properties for the parent entity as well as its children. The end result is an extremely wide and tall table in the database with a high percentage of empty values.
Although the entity inheritance feature of Core Data is extremely useful, we should be aware of what is going on underneath the object model to avoid a performance penalty. We should not treat entity inheritance as an equal to object inheritance. There is certainly some overlap, but they are not equal, and treating them as such will have a negative impact on the performance of the repository.
**c. Denormalizing Data to Improve Performance **
Although the most powerful persistent store available for Core Data is a database, we must always be conscious of the fact that Core Data is not just a database. Core Data is an object hierarchy that can be persisted to a database format. The difference is subtle but important. Core Data is first a collection of objects that we use to display data in a user interface of some form and allow the user to access that data. Therefore, although database normalization might be the first place to look for performance improvements, we should not take it too far. There are six levels of database normalization,1 but a Core Data repository should rarely, if ever, be taken beyond the second level. There are several cases where we can gain a greater performance benefit by denormalizing the data.
**d. Search-Only Properties **
Searching within properties can be quite expensive. For properties that have a large amount of text or, worse, Unicode text, a single search field can cause a huge performance hit. One way to improve this situation is to create a derived attribute based on the text in an entity. For example, searching in our description property of the Recipe entity can potentially be very expensive if the user has verbose descriptions and/or uses Unicode characters in the description.
To improve the performance of searches in this field, we could create a second property on the Recipe entity that strips the Unicode characters from the description and also removes common words such as a, the, and, and so on. If we then perform the search on this derived property, we can drastically improve search performance. The downside to using search-only properties is that we need to maintain them. Every time the description field is edited, we need to update the derived property as well.
**e. Expensive Calculations **
In a normalized database, calculated values are not stored. It is considered cheaper to recalculate the value as needed than to store it in the database. However, from a user experience point of view, the opposite can frequently be true. In cases where the calculation takes a human-noticeable amount of time, it may very well be better for the user if we were to store that calculation in the entity and recalculate it only when one of its dependent values has changed. For example, if we store the first and last names of a user in our Core Data repository, it might make sense to store the full name as well.
**f. Intelligent Relationships **
Relationships in a Core Data model are like salt in a cooking recipe. Too much and you ruin the recipe; too little and something is missing. Fortunately, there are some simple rules we can follow when it comes to relationships in a Core Data repository.
**g. Follow the Object Model **
Core Data is first and foremost an object model. The entities in our model should represent the data as accurately as possible. Just because a value might be duplicated across several objects (or rows from the database point of view) does not mean it should be extruded into its own table. Many times it is more efficient for us to store that string several times over in the entity itself than to traverse a relationship to get it.
Traversing a relationship is generally more expensive than accessing an attribute on the entity. Therefore, if the value being stored is simple, it’s better to leave it in the entity it is associated with.
**h. Separate Commonly Used from Rarely Used Data **
If the object design calls for a one-to-many relationship or a many-to-many relationship, we should definitely create a relationship for it. This is usually the case where the data is more than a single property or contains binary data or would be difficult to properly model inside the parent object. For example, if we have a user entity, it is more efficient to store the user’s address in its own object as opposed to having several attributes in the user object for address, city, state, postal code, and so on.
A balance needs to be carefully maintained between what is stored on the other end of a relationship and what is stored in the primary entity. Crossing key paths is more expensive than accessing attributes, but creating objects that are very wide also slows down data access.
**3. Fetching **
Fetching is the term used to describe the resolving of NSManagedObject objects from the repository. When we retrieve an NSManagedObject, it is “fetched” into memory, and we can then access its properties. To help us utilize memory efficiently, fetching may not always happen all at once. Specifically, when we are using a SQLite store, it is quite possible that an object we think is in memory is actually only on disk and has yet to be read into memory. Likewise, objects that we think we are done with may actually still sit in a cache.
To demonstrate the differences in the ways that we can load data into memory from our SQLite Store, I used an older Apple demonstration application from a previous WWDC called GoFetch. (The source code for this application is available as part of this book’s download.) The entire goal of this application is to generate a large amount of random data and let us control how it is fetched back into memory. Each fetch is then timed to demonstrate the speed of various options. These tests were performed with 3,417 records in the SQLite repository. ** a. Loading NSManagedObjectID Objects Only **
The smallest amount of data that we can retrieve as part of an NSFetch-Request is just the NSManagedObjectID. The NSManagedObjectID is the unique identifier for the record and contains no content.
**b How to Retrieve NSManagedObjectID Objects **
NSFetchRequest *fetchRequest = [[NSFetchRequest alloc] init]; [fetchRequest setEntity:[NSEntityDescription entityForName:@"Person"
inManagedObjectContext:[self managedObjectContext]]];
[fetchRequest setResultType:NSManagedObjectIDResultType];
**c. Loaded As a Fault **
The next smallest amount of data we can retrieve is referred to as a fault- ed NSManagedObject. What this means is the NSFetchRequest returns an NSArray of NSManagedObject objects, but those objects contain only the NSManagedObjectID. All the properties and relationships are empty or in a faulted state. As soon as an attribute is accessed, all of the attributes on that object are loaded in. Likewise, as soon as a relationship is accessed, all the NSManagedObject objects on the other end of that relationship are loaded in as faults.
**d. How to Retrieve Faulted NSManagedObject Objects **
To disable the fetching of attributes as part of the NSFetchRequest, we need to disable it prior to executing the fetch. NSFetchRequest *fetchRequest = [[NSFetchRequest alloc] init]; [fetchRequest setIncludesPropertyValues:NO]; [fetchRequest setEntity:[NSEntityDescription entityForName:@"Person" inManagedObjectContext:[self managedObjectContext]]];
Although this seems like a great solution, it can be a bit of a trap. Because this configuration returns empty skeletons, each object gets loaded from disk individually. This is significantly slower than loading all the objects needed at once. However, the time to load the objects is spread out and can be less noticeable to the user. For raw speed, it is recommended that we load all the data for the objects in one pass.
**e. Loading Property Values **
The next step up from faulted NSManagedObject objects is to prefetch their property values. This will not retrieve the objects on the other sides of relationships. Performing this query took 0.021 seconds for the 3,417 records in the test repository
**IX- Threading **
Multithreading is one of the great double-edged swords of programming. If it is done correctly, it can be a real boon to your application; done incorrectly, it leads to strange, unreproducible errors in the application. Multithreading has a tendency to polarize developers: they either swear that it is necessary for any application to perform properly or declare it is to be avoided at all costs. The truth, of course, is somewhere in the middle. Multithreading is a vital piece of the overall performance puzzle. While adding more threads will not make your application automatically faster, it can make your application “feel” faster to the user.
The problem is that Core Data is not inherently thread-safe. It still wants and expects to be run in a single thread. Therefore, when we start multithreading our applications, we must take care to work with Core Data properly to avoid threading issues. Fortunately, as of iOS 6.0 and OS X 10.8 Mountain Lion, things have improved significantly.
**1. Why Isn’t Core Data Thread-Safe? **
You may be surprised to learn that there are a lot of things in Cocoa and Objective-C that are not thread-safe, and Core Data is only one of the many. For instance, whenever you make a change to a GUI widget, it is recommended you be on the main thread, because the UI is not thread-safe. Prior to iOS 6.0 and OS X 10.8 Mountain Lion, you could get away with using Core Data incorrectly in a multithreaded environment. If you read from NSManagedObject instances only on threads other than the one that created the instance and didn’t write to them, then things would work—usually. However, as of iOS 6.0 and OS X 10.8 Mountain Lion, that has changed. Core Data now monitors what thread the objects are being accessed from and will throw an exception if an improper access is detected. While this change can catch developers off-guard, it is a net win. We now have well- defined boundaries for what is correct and what is not.
Whether we are developing for the latest release of iOS or OS X or targeting an older platform, we must now follow a strict rule for thread safety with Core Data: contexts and their resulting objects must be accessed only on the thread that created them.
2. Creating Multiple Contexts
As of iOS 6.0 and Mac OS X Lion, there are two recommended methods for using Core Data across multiple threads. The first method, which is valid on all versions of iOS and Mac OS X that can use Core Data, involves creating a separate NSManagedObjectContext for each thread that will be interacting with Core Data. The creation of the separate context on a background thread is quite straightforward and is nearly identical to the creation of the NSManagedOb- jectContext on the main thread.
NSManagedObjectContext *localMOC = nil;
NSPersistentStoreCoordinator *psc = nil;
localMOC = [[NSManagedObjectContext alloc] init];
psc = [[self mainContext] persistentStoreCoordinator];
[localMOC setPersistentStoreCoordinator:psc];
Although the NSPersistentStoreCoordinator is not thread-safe either, the NSManage- dObjectContext knows how to lock it properly when in use. Therefore, we can attach as many NSManagedObjectContext instances to a single NSPersistentStoreCoor- dinator as we want without fear of collision.
**3. Cross-thread Communication **
There is one major catch when standing up multiple NSManagedObjectContext instances. Each instance is unaware of the existence and activity of the other instances. This means that when an NSManagedObject is created, edited, or deleted by one NSManagedObjectContext, the other instances aren’t aware of the change. Fortunately, Apple has given us a relatively easy way to keep all the NSManage- dObjectContext instances in sync. Every time an NSManagedObjectContext completes a save operation, it broadcasts an NSNotification with the key NSManagedObjectCon- textDidSaveNotification. In addition, the NSNotification instance contains all the information about what is occurring in that save. To complement the NSNotification broadcast, the NSManagedObjectContext has a method designed to consume this NSNotification and update itself based on its contents. This method, -mergeChangesFromContextDidSaveNotification:, will update the NSManagedObjectContext with the changes and also notify any observers of those changes. This means our main NSManagedObjectContext can be updated with a single call whenever the background NSManagedObjectContext instances perform a save, and our user interface will be updated automatically.
NSNotificationCenter *center = [NSNotificationCenter defaultCenter];
[center addObserver:self
selector:@selector(contextDidSave:) name:NSManagedObjectContextDidSaveNotification
object:localMOC];
In this example, we listen for an NSManagedObjectContextDidSaveNotification and call -contextDidSave: whenever the notification is received. Also note that we’re interested only in notifications generated from our own localMOC; this helps to avoid polluting the main NSManagedObjectContext with duplicate merges.
- (void)contextDidSave:(NSNotification*)notification {
NSManagedObjectContext *moc = [self mainContext]; void (^mergeChanges) (void) = ^ {
[moc mergeChangesFromContextDidSaveNotification:notification];
};
if ([NSThread isMainThread]) { mergeChanges();
} else {
dispatch_sync(dispatch_get_main_queue(), mergeChanges);
}
}
When we receive a change notification, the only thing we need to do with it is hand it off to the primary NSManagedObjectContext for consumption. However, the main NSManagedObjectContext needs to consume that notification on the main thread. To do this, we create a simple block and either call that block directly (if we are on the main thread) or pass it off to the main thread via a dispatch _sync if we are not on the main thread.
X - Concurency
You can find the Apple’s document here.
https://developer.apple.com/library/ios/releasenotes/DataManagement/RN- CoreData/index.html#//apple_ref/doc/uid/TP40010637-CH1-DontLinkElementID_1
1. Thread safe
- Core data is not thread safe. Core data expert to run on single thread. This doesn't that every core data operation needs to run on main thread.
- Careful how to change from one thread are propagated to other thread. Working with core data on multiple threads is actually simple from a theoretical point of view. NSManagedObject,NSManagedObjectContext, NSPersistentStoreCoordinator aren't thread safe, an instance of these classes should only be accessed from the thread they were created on.
2. How to access a record from different thread?
a. NSManagedObject
NSManagedObject has an objectID method that return an instance of the NSManagedObjectID, It is thread safe and an instance contains all information a managed object context needs to fetch the corresponding managed object. The objectWithID and existingObjectWithID:error: methods return a local version – local to the current thread The basic rule to remember is to not pass the NSManagedObject instance from once thread to another. Instead, pass the NsmanagedObjectId and ask the thread's managed object context for a local version of the managed object.
b. NSManagedObjectContext
We know that this class isn't thread safe. We should create a managed object context for every thread that interacts with Core data. A common approach is to store the managed object context in the thread's dictionary, a dictionary to store thread-specific data.
// Add Object to Thread Dictionary
NSThread *currentThread = [NSThread currentThread];
[[currentThread threadDictionary] setObject:managedObjectContext forKey:@"managedObjectContext"];
c. NSPersistentStoreCoordinator
It is possible and once of the strategies Apple used to recommend. It isn't necessary to create a separate persistent store. This class is designed to support multiple managed object contexts, even if those managed object context created on different threads. Because NSManagedObjectContext class locks the persistent store coordinator while accessing it. It is possible for multiple managed object contexts to use the same persistent store coordinator even if those managed object contexts live on different threads. This makes a miltithreaded core data setup much more managable and less complex.
3. Three different core data stacks
a. Stack 1
The first setup is a not so smart solution you sometimes see or read about. I included this stack on purpose as a reference point for the better alternatives. In this case the core data stack consists of a main managed object context initialized with the NSMainQueueConcurrencyType, and a background managed object context initialized with the NSPrivateQueueConcurrencyType. The main context is configured to be the parent context of the background context. In this setup the background context is used for the data import.
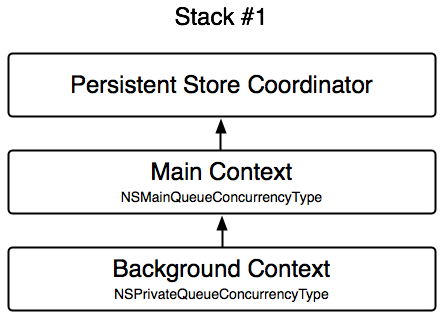 
b. Stack 2

b. Stack 2
It consists of three layers: the master context in a private queue, the main context as its child in the main queue, and one or multiple worker contexts as children of the main context in the private queue. In this example the worker contexts are used to import the data.

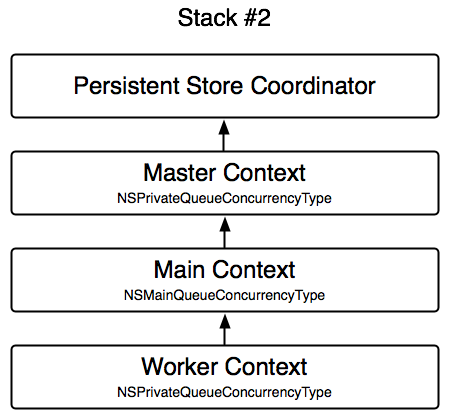
c. Stack 3
This stack consists of two independent managed object contexts which are both connected to the same persistent store coordinator. One of the contexts is set up on the main queue, the other one on a background queue. Change propagation between the contexts is achieved by subscribing to the NSManagedObjectContextDidSaveNotification and calling mergeChangesFromContextDidSaveNotification: on the other context.
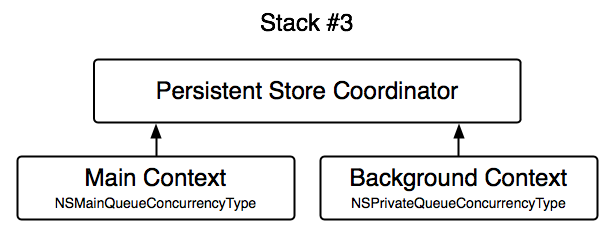
**XI- Example **
In this example i will use MagicalRecord open source. And show you how to integrate MagicalRecord with Concurrency Support for Managed Object Contexts **
- How to install MagicalRecord**
- You can find the answer here: https://github.com/magicalpanda/MagicalRecord
2. Use MagicalRecord.
- Before you can use magicalRecord for your app. You init init and setup it. [MagicalRecord setupCoreDataStackWithStoreNamed:coreDataFileName]; - coreDataFileName: It is name of your data model (.xcdatamodeld).
- After initialization success MagicalRecord provide you the default context (MR_DefaultContext) this work on main thread.
1. User model
User.h
@interface User : NSManagedObject
@property (nonatomic, retain) NSString * avatar;
@property (nonatomic) double balance;
@property (nonatomic) BOOL isFriend;
@property (nonatomic) int32_t country_code;
@property (nonatomic, retain) NSString * display_name;
@property (nonatomic, retain) NSString * email;
@property (nonatomic) NSTimeInterval last_update;
@property (nonatomic, retain) NSString * phone_number;
@property (nonatomic, retain) NSString * sip_number;
@property (nonatomic) int32_t status;
@property (nonatomic) int32_t user_id;
@property (nonatomic, retain) NSString * user_name;
@end
User.m
@implementation User
@dynamic avatar;
@dynamic balance;
@dynamic country_code;
@dynamic display_name;
@dynamic email;
@dynamic last_update;
@dynamic phone_number;
@dynamic sip_number;
@dynamic status;
@dynamic user_id;
@dynamic user_name;
@dynamic isFriend;
@end
2. Database manager.
I created a class name Database. This class will handle multiple contexts, merge change from background contexts to main context.
Database.h
@interface Database : NSObject
- (NSArray *) getListFonextFriends:(NSString *)filter;
- (void) saveFonextUserToCoreData:(FonextUser *)user;
- (void) removeUserWithId:(int)aid;
- (void) unfriendWithId:(int)aid;
- (User *) userMOWithPredicate:(NSPredicate *)predicate;
- (User *) createNewUser;
+ (Database *) shareInstance;
@end
Database.m
@interface Database()
{
}
@property (nonatomic, strong) NSManagedObjectContext *userContext; // this is concurrency context. Any action interactive with User entity will perform on this context.
@property (nonatomic, strong) NSManagedObjectContext *messageContext;// Like as userContext for other purpose
@end
@implementation Database
// This method return the singleton instance and make this class thread safe access.
+ (Database *) shareInstance{
static Database *singleton = nil;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^
{
singleton = [[Database alloc] init];
});
return singleton;
}
- (instancetype) init
{
self = [super init];
if (self){
_userContext = [[NSManagedObjectContext alloc] initWithConcurrencyType:NSPrivateQueueConcurrencyType];
[_userContext setPersistentStoreCoordinator:[NSPersistentStoreCoordinator MR_defaultStoreCoordinator]];
_messageContext = [[NSManagedObjectContext alloc] initWithConcurrencyType:NSPrivateQueueConcurrencyType];
[_messageContext setPersistentStoreCoordinator:[NSPersistentStoreCoordinator MR_defaultStoreCoordinator]];
NSNotificationCenter *nc = [NSNotificationCenter defaultCenter];
[nc addObserver:self selector:@selector(managedObjectContextDidSave:) name:NSManagedObjectContextDidSaveNotification object:nil];
}
return self;
}
- (void) dealloc{
[[NSNotificationCenter defaultCenter] removeObserver:self];
}
// This is important. Any change from background context will notified here. We need call marge change to main context.
- (void) managedObjectContextDidSave:(NSNotification *)notification{
[Utils dispatchOnMainThread:^{
[[NSManagedObjectContext MR_defaultContext] mergeChangesFromContextDidSaveNotification:notification];
}];
}
- (void) saveFonextUserToCoreData:(FonextUser *)user {
User *umo = [User MR_findFirstWithPredicate:[NSPredicate predicateWithFormat:@"user_id == %d",user.user_id] inContext:self.userContext];
if (!umo){
umo = [User MR_createInContext:self.userContext];
}
[umo mapFonextUser:user];
NSError *error = nil;
[self.userContext save:&error];
if (error){
NSLog(@"==> save user error");
}
}
- (NSArray *) getListFonextFriends:(NSString *)filter
{
NSMutableArray *result = [NSMutableArray array];
NSArray *arr = nil;
if (filter && filter.length >0){
arr = [User MR_findAllWithPredicate:[NSPredicate predicateWithFormat:@"(isFriend == 1) AND ((display_name contains[c] %@) || ((user_name contains[c] %@)))",filter,filter] inContext:self.userContext];
}else{
arr = [User MR_findAllWithPredicate:[NSPredicate predicateWithFormat:@"isFriend == 1"] inContext:self.userContext];
}
for (User *mo in arr) {
[result addObject:[[FonextUser alloc] initWithCoreData:mo]];
}
return result;
}
- (void) unfriendWithId:(int)aid
{
User *umo = [User MR_findFirstWithPredicate:[NSPredicate predicateWithFormat:@"user_id == %d",aid] inContext:self.userContext];
if (umo){
umo.isFriend = false;
}
NSError *error = nil;
[self.userContext save:&error];
if (error){
NSLog(@"==> unfriendWithId error");
}
}
- (User *) userMOWithPredicate:(NSPredicate *)predicate
{
return [User MR_findFirstWithPredicate:predicate inContext:self.userContext];
}
- (User *) createNewUser
{
return [User MR_createInContext:self.userContext];
}
- (void) removeUserWithId:(int)aid{
}
We also can create and manage background context for each thread it working on like as bellow
ImportOperation.h
@interface ImportOperation : NSOperation {
BOOL started;
BOOL executing;
BOOL paused;
BOOL finished;
NSUInteger initialRecord;
NSUInteger totalRecords;
NSUInteger identifier;
double percentDone;
}
@property(readwrite, getter=isStarted) BOOL started;
@property(readwrite, getter=isPaused) BOOL paused;
@property(readwrite, getter=isExecuting) BOOL executing;
@property(readwrite, getter=isFinished) BOOL finished;
@property(readwrite) NSUInteger identifier;
@property(readwrite) NSUInteger initialRecord;
@property(readwrite) NSUInteger totalRecords;
@property(readwrite) double percentDone;
// Create a new operation to make a series of records
- (id)initWithInitial:(NSUInteger)initial numberOfRecords:(NSUInteger)total identifier:(NSUInteger)identifier;
@end
ImportOperation.m
@implementation ImportOperation
@synthesize started;
@synthesize executing;
@synthesize paused;
@synthesize finished;
@synthesize initialRecord;
@synthesize totalRecords;
@synthesize identifier;
@synthesize percentDone;
- (id)initWithInitial:(NSUInteger)initial numberOfRecords:(NSUInteger)total identifier:(NSUInteger)idf
{
[super init];
[self setStarted:false];
[self setExecuting:false];
[self setPaused:false];
[self setFinished:false];
[self setIdentifier:idf];
[self setInitialRecord:initial];
[self setTotalRecords:total];
[self setPercentDone:0.0];
return self;
}
- (void)mergeChanges:(NSNotification *)notification
{
ApplicationController *appController = [[NSApplication sharedApplication] delegate];
NSManagedObjectContext *mainContext = [appController managedObjectContext];
// Merge changes into the main context on the main thread
[mainContext performSelectorOnMainThread:@selector(mergeChangesFromContextDidSaveNotification:)
withObject:notification
waitUntilDone:YES];
}
- (void)main
{
// Set Executing Flag
[self setStarted:true];
[self setExecuting:true];
[self setPaused:false];
// Create context on background thread
ApplicationController *appController = [[NSApplication sharedApplication] delegate];
NSManagedObjectContext *ctx = [[NSManagedObjectContext alloc] init];
[ctx setUndoManager:nil];
[ctx setPersistentStoreCoordinator: [appController persistentStoreCoordinator]];
// Register context with the notification center
NSNotificationCenter *nc = [NSNotificationCenter defaultCenter];
[nc addObserver:self
selector:@selector(mergeChanges:)
name:NSManagedObjectContextDidSaveNotification
object:ctx];
// Create some records to simulate a long running import
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init];
NSUInteger x = [self initialRecord];
while (x < [self totalRecords] + [self initialRecord]) {
// Pause to simulate an import from an external source
sleep(1);
if ([self isPaused]) {
// Don't import anything while paused
continue;
}
NSLog(@"Importing user %d", x);
// Create a new User to "import"
NSManagedObject *newUser = [NSEntityDescription insertNewObjectForEntityForName:@"User"
inManagedObjectContext:ctx];
[newUser setValue:[NSString stringWithFormat:@"User %d", x] forKey:@"user_name"];
[newUser setValue:[NSString stringWithFormat:@"user%d@bogus.com", x] forKey:@"email"];
….
if (x % 10 == 0) {
// We'll occasionally write our imports to the store and clear out the ctx and the pool
// to improve the memory footprint. We would likely do this in larger batches in a real app.
NSError *error = nil;
[ctx save:&error];
if (error) {
[NSApp presentError:error];
}
[ctx reset];
NSLog(@"Write imports from operation %d to store", [self identifier]);
[pool drain];
pool = [[NSAutoreleasePool alloc] init];
}
[self setPercentDone:(double)(x - [self initialRecord] + 1) / (double)[self totalRecords]];
x++;
}
// Clean up any final imports
NSError *error = nil;
[ctx save:&error];
if (error) {
[NSApp presentError:error];
}
[ctx reset];
NSLog(@"Write imports from operation %d to store", [self identifier]);
[pool drain];
// Release context
return [ctx release];
// Flag execution complete
[self setExecuting:false];
[self setFinished:true];
}
@end
All rights reserved
