Common Database Design Errors
Bài đăng này đã không được cập nhật trong 7 năm
Nghệ thuật thiết kế một cơ sở dữ liệu tốt giống như việc bơi lội vậy. Mọi việc bắt đầu thật dễ dàng và càng ngày càng trở nên khó khăn nếu ta đào sâu hơn và mong muốn đạt đến trình độ master. Nếu muốn tìm hiểu để thiết kế cơ sở dữ liệu, bạn cần có những kiến thức nền căn bản như kiến thức về các hình thức cơ sở dữ liệu thông thường và các mức isolation transaction. Và chúng ta cần thực hành càng nhiều càng tốt, bởi vì sự thật đáng buồn là chúng ta học được nhiều nhất ... chính từ việc ta gây ra lỗi.
Phạm vi bài viết này, chúng ta sẽ cố gắng làm cho việc học thiết kế DB đơn giản hơn một chút, bằng cách show một số lỗi phổ biến mà mọi người thường gặp phải khi thiết kế DB.
Bây giờ chúng ta cùng đi vào tìm hiểu thông qua ví dụ sau:
Giả sử muốn thiết kế một cơ sở dữ liệu cho một website bán sách online và hệ thống nên cho phép khách hàng thực hiện các chức năng sau:
- duyệt qua và tìm kiếm sách theo tiêu đề sách, mô tả và thông tin tác giả, bình luận về sách và đánh giá chúng sau khi đọc
- đặt mua sách
- xem trạng thái xử lý đơn hàng
thì mô hình cơ sở dữ liệu ban đầu có thể trông như thế này: (chúng ta có thể dùng Vertabelo để tạo ra một DB mới trong PostgreSQL RDBMS)
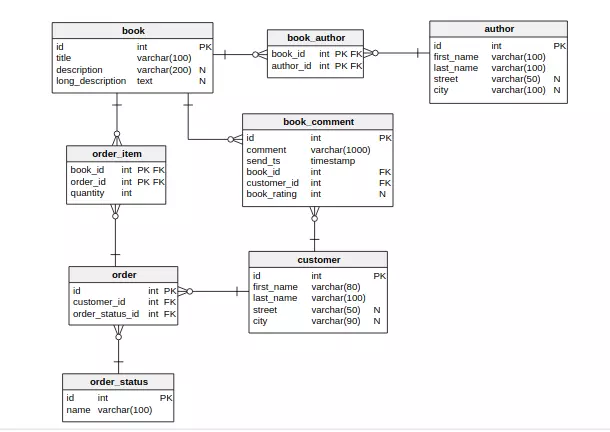
1. Sử dụng tên không hợp lệ
Trong ví dụ trên có 1 bảng được đặt tên là order, và như đã biết, order cũng là một reserved keyword của SQL. Do đó, nếu ta có gắng thực hiện query như sau:
SELECT * FROM ORDER ORDER BY ID
thằng DMS sẽ complain ngay, may mắn là trong PostgreSQL, chỉ cần thêm "order" thì câu query sẽ hoạt động bình thường:
SELECT * FROM "order" ORDER BY ID
Nếu để một từ giữa dấu "" trong SQL, nó sẽ trở thành một delimited identifiers và hầu hết các cơ sở dữ liệu sẽ phiên dịch nó theo cách phân biệt chữ hoa chữ thường. Vì "order" là một reserved keyword trong SQL, nên khi tạo SQL với Vertabelo sẽ tự động cho vào trong các dấu ngoặc kép:
CREATE TABLE "order" (
id int NOT NULL,
customer_id int NOT NULL,
order_status_id int NOT NULL,
CONSTRAINT order_pk PRIMARY KEY (id)
);
Bây giờ, tôi có thể tạo một bảng khác, lần này có tên ORDER và PostgreSQL sẽ không phát hiện xung đột đặt tên:
CREATE TABLE "ORDER" (
id int NOT NULL,
customer_id int NOT NULL,
order_status_id int NOT NULL,
CONSTRAINT order_pk2 PRIMARY KEY (id)
);
Sự kỳ diệu đằng sau đó là nếu một mã định danh không được bao bọc trong dấu ngoặc kép, nó được gọi là ordinary identifier - định danh thông thường và tự động chuyển đổi sang chữ hoa trước khi sử dụng(yêu cầu bởi chuẩn SQL 92).
Những định danh được đặt trong dấu ngoặc kép - được gọi là delimited identifiers - số phân định giới hạn được yêu cầu không thay đổi.
*Note: Không bao giờ sử dụng từ khóa làm tên đối tượng.*
Việc đặt tên tốt cho các bảng và các thành phần khác của cơ sở dữ liệu - không những cần “không mâu thuẫn với các từ khóa SQL” mà còn phải đặt tên sao cho có ý nghĩa và dễ nhớ.
Trong một cơ sở dữ liệu nhỏ, giống như của chúng ta, việc đặt tên tuy không phải là một vấn đề quá quan trọng. Nhưng khi cơ sở dữ liệu của bạn đạt tới 100, 200 hoặc 500 bảng, bạn sẽ biết rằng việc đặt tên nhất quán và trực quan là rất quan trọng để giữ cho mô hình có thể duy trì được trong suốt thời gian tồn tại của dự án.
Tóm lại, muốn đặt một good name thì chúng ta cần lưu ý những điểm chính sau đây:
- tên ngắn ngọn, dễ hiểu
- trực quan và mô tả chính xác chức năng của nó càng tốt
- nhất quán
- tránh sử dụng các từ khóa cơ sở dữ liệu SQL để đặt tên
- thiết lập quy ước đặt tên
Với ví dụ trên, bảng order ta có thể đổi tên thành purchase
2. Chiều rộng cột không đủ
Như chúng ta có thể thấy trong bảng book_comment, cột comment có type là varchar(1000). Điều đó có nghĩa là gì?
Nếu trường này là plain-text trong GUI (khách hàng chỉ có thể nhập nhận xét chưa được định dạng) thì điều đó có nghĩa là comment có thể lưu trữ tối đa 1000 ký tự văn bản. Và nếu nó là như vậy thì không có lỗi ở đây.
Nhưng nếu trường comment cho phép một số format như bbcode hoặc HTML, thì số lượng ký tự chính xác mà có thể nhập thực tế không xác định . Nếu họ nhập một bình luận đơn giản, như thế này:
I like that book!
thì sẽ lưu vào DB là 17 ký tự.
Nhưng nếu nhập như sau:
I <b>like</b> that book!
lưu trữ tận 24 ký tự trong DB trong khi người dùng sẽ chỉ thấy 17 ký tự trên GUI.
Vì vậy, nếu customer có thể format comment bằng cách sử dụng trình soạn thảo WYSIWYG nào đó thì giới hạn kích thước của trường comment có thể gây lỗi vì khi customer nhập vượt quá max length (1000 ký tự trong raw HTML) thì số ký tự họ thấy trong GUI vẫn có thể thấp hơn nhiều 1000. Trong tình huống như vậy, chỉ cần thay đổi type và không bận tâm tới max-length trong DB.
*Tuy nhiên, khi để max-length cần chú ý thêm cả việc encoding text.*
Chúng ta cụ thể như sau: Trong Oracle, kiểu cột varchar được giới hạn ở 4000 byte - và đó là một hard limit - được fix cứng và không có cách nào bạn có thể vượt quá giới hạn này. Vì vậy, nếu bạn xác định một column với type là varchar (3000 char) thì có nghĩa là có thể lưu trữ 3000 ký tự trong cột đó, nhưng chỉ khi nó không sử dụng nhiều hơn 4000 byte trên đĩa. Khi vượt quá giới hạn, Oracle sẽ raise một lỗi khi cố lưu dữ liệu vào cơ sở dữ liệu.
Vậy tại sao một văn bản 3000 ký tự lại vượt quá 4000 byte trên đĩa?
Nếu nó bằng tiếng Anh thì không thể có chuyện này, nhưng nếu viết bằng một ngôn ngữ khác lại hoàn thoàn có thể xảy ra
Ví dụ: nếu bạn cố gắng lưu từ "mother" bằng tiếng Trung(母親) và encoding DB là UTF-8 thì chuỗi này sẽ có 2 ký tự nhưng 6 byte trên đĩa.
*Note: Đối với các DB khác nhau có thể có các giới hạn khác nhau cho các trường ký tự và text fields khác nhau.*
Tóm lại là cần lưu ý những vấn đề sau để tránh việc độ dài column bị thiếu:
- giới hạn chiều dài của các cột văn bản trong DB nói chung là rất hữu ích vì lý do bảo mật và hiệu suất nhưng đôi khi không cần thiết hoặc bất tiện để làm
- với mỗi DB khác nhau thì xử lý các giới hạn văn bản cũng khác nhau
- luôn nhớ encoding nếu sử dụng ngôn ngữ khác ngoài tiếng Anh.
=> Ở ví dụ có thể chage type cột book_comment sang text
3. Không lập chỉ mục đúng cách
Có một câu nói rằng greatness is achieved, not given. Nó cũng giống với hiệu suất - đạt được bằng cách thiết kế cẩn thận mô hình cơ sở dữ liệu, điều chỉnh các parameter cơ sở dữ liệu và bằng cách tối ưu hóa các truy vấn được chạy bởi ứng dụng trên cơ sở dữ liệu. Ở đây chúng tôi sẽ tập trung vào thiết kế model.
Trong ví dụ trên, giả sử rằng nhà thiết kế GUI của bookstore quyết định rằng 30 comments mới nhất sẽ được hiển thị trong màn hình chính.
Vì vậy, để chọn các comment này sử dụng truy vấn sau:
select comment, send_ts from book_comment order by send_ts desc limit 30;
Truy vấn này chạy nhanh đến mức nào? Mất ít hơn 70 ms. Nhưng nếu chúng ta muốn ứng dụng của chúng ta mở rộng (làm việc nhanh dưới tải nặng), chúng ta cần kiểm tra trên dữ liệu lớn hơn. Và đây là bảng thống kê kết quả tương ứng với lượng records:
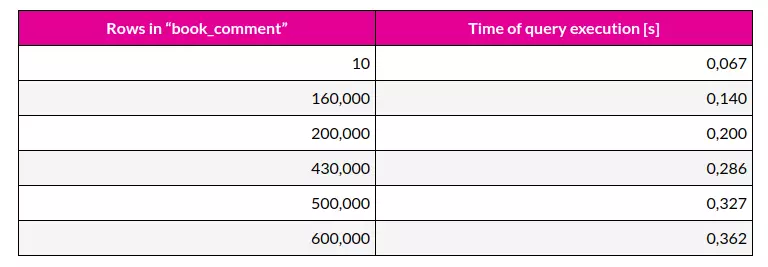
Như chúng ta có thể thấy, với việc tăng số lượng row trong bảng book_comment phải mất nhiều thời gian hơn để trả về 30 row mới nhất.
Tại sao phải mất nhiều thời gian hơn? Ta cùng xem câu truy vấn:
db=# explain select comment, send_ts from book_comment order by send_ts desc limit 30;
QUERY PLAN
-------------------------------------------------------------------
Limit (cost=28244.01..28244.09 rows=30 width=17)
-> Sort (cost=28244.01..29751.62 rows=603044 width=17)
Sort Key: send_ts
-> Seq Scan on book_comment (cost=0.00..10433.44 rows=603044 width=17)
Việc truy vấn trên cho chúng ta thấy cách DB sẽ xử lý truy vấn như thế nào và chi phí thời gian có thể để tính toán kết quả của nó sẽ là bao nhiêu. Và ở đây PostgreSQL cho chúng ta biết nó sẽ thực hiện "Seq Scan on book_comment" bằng việc kiểm tra tất cả các bản ghi của bảng book_comment, từng cái một, để sắp xếp chúng theo giá trị của cột send_ts. Tuy nhiên, PostgreSQL không đủ thông minh để chọn 30 records mới nhất mà không cần sort all 600.000 records.
May thay, ta có thể yêu cầu PostgreSQL sort bảng này bằng cột send_ts và lưu kết quả bằng cách tạo một index trên cột này:
create index book_comment_send_ts_idx on book_comment(send_ts);
Bây giờ chỉ mất 67ms để chọn 30 records trong số 600.000 records mới nhất một lần nữa.
Ta có thể thấy query khác nhau như thế nào:
db=# explain select comment, send_ts from book_comment order by send_ts desc limit 30;
QUERY PLAN
--------------------------------------------------------------------
Limit (cost=0.42..1.43 rows=30 width=17)
-> Index Scan Backward using book_comment_send_ts_idx on book_comment (cost=0.42..20465.77 rows=610667 width=17)
Index Scan có nghĩa là thay vì duyệt qua bảng, theo từng hàng, DB sẽ duyệt qua index vừa tạo. Và query ước tính nhỏ hơn rất nhiều.
Note:
-
luôn kiểm tra các query chạy tốn time, có thể sử dụng tính năng EXPLAIN vì hầu hết các DB hiện đại nhất đều có nó
-
Khi tạo index:
- nhớ rằng index không phải lúc nào cũng được dùng, DB có thể quyết định không sử dụng một index nếu nó ước tính việc sử dụng nó sẽ làm chậm hơn so với khi thực hiện quét tuần tự hoặc một số toán tử khác
- việc sử dụng các index - INSERT và DELETE trên các bảng được đánh index sẽ chậm hơn
- xem xét các index non-default nếu cần
-
đôi khi bạn cần tối ưu hóa query chứ không phải model.
-
không phải mọi vấn đề hiệu năng đều có thể được giải quyết bằng cách tạo ra một index, còn có những cách khác để giải quyết vấn đề hiệu suất này:
- caching
- turing các params DB và kích thước bộ đệm.
- điều chỉnh transaction isolation level
4. Không xem xét số lượng hoặc lưu lượng truy cập
Chúng ta thường thêm thông tin về khối lượng dữ liệu có thể có. Nếu hệ thống mới đang xây dựng dựa trên một dự án hiện có, bạn có thể estimate kích thước của dữ liệu trong hệ thống của mình bằng cách xem khối lượng dữ liệu(data volume) trong hệ thống cũ. Bạn có thể sử dụng thông tin này khi bạn thiết kế một model cho một hệ thống mới.
Nếu cửa hàng online buôn may bán đắt, lượng data của bàng purchase có thể rất lớn. Khi càng bán được nhiều hàng hơn sẽ có trong bảng purchase.
Nếu chúng ta dự trước được điều này, ta có thể tách các giao dịch mua hiện tại đã xử lý khỏi các giao dịch mua đã hoàn tất. Thay vì một bảng là purchase ta tách thành 2 bảng: purchase - cho các giao dịch mua hiện tại và archived_purchase- cho các đơn hàng đã hoàn tất.
Các giao dịch mua hiện tại được truy xuất mọi lúc: trạng thái của chúng được cập nhật, khách hàng thường xuyên kiểm tra thông tin trên đơn đặt hàng của họ. Mặt khác, các giao dịch mua hoàn tất chỉ được lưu giữ dưới dạng dữ liệu lịch sử. Chúng hiếm khi được cập nhật hoặc truy xuất, vì vậy bạn có thể xử lý thời gian truy cập dài hơn vào bảng này. Với việc tách như này, có thể giữ cho bảng được sử dụng nhỏ mà vẫn bảo toàn dữ liệu.
Bạn nên tối ưu hóa tương tự dữ liệu thường xuyên được cập nhật. Hãy tưởng tượng một hệ thống mà các phần của thông tin người dùng được cập nhật thường xuyên bởi một hệ thống bên ngoài((ví dụ, hệ thống bên ngoài tính điểm thưởng). Sau đó, cũng có các thông tin khác trong bảng user, ví dụ như thông tin cơ bản như: đăng nhập, password và full-name. Thông tin cơ bản được truy xuất rất thường xuyên. Các cập nhật thường xuyên làm chậm việc nhận thông tin cơ bản của user. Giải pháp đơn giản nhất là chia dữ liệu thành hai bảng: một là thông tin cơ bản (often read), một cho thông tin điểm thưởng (thường xuyên được cập nhật). Thao tác cập nhật theo cách này không làm chậm thao tác đọc.
Tuy nhiên, tách dữ liệu thường xuyên và không thường xuyên sử dụng vào nhiều bảng không phải là cách duy nhất để xử lý dữ liệu khối lượng lớn. Ví dụ: nếu bạn cho rằng mô tả sách rất dài, bạn có thể sử dụng application-level caching để bạn không phải truy xuất dữ liệu nặng này thường xuyên mà không cần phải tách thành các bảng nhỏ.
Tóm lại là cần chú ý những điểm sau để khắc phụ lỗi này:
- Dùng kiến thức về nghiệp vụ, domain-specific mà khách hàng của bạn phải ước tính khối lượng dự kiến của dữ liệu bạn sẽ xử lý trong cơ sở dữ liệu của mình.
- Phân tách dữ liệu được cập nhật thường xuyên từ dữ liệu đọc thường xuyên
- Cân nhắc sử dụng application-level caching cho dữ liệu nặng hoặc dữ liệu cập nhật không thường xuyên.
Đây là bookstore model sau khi thay đổi.
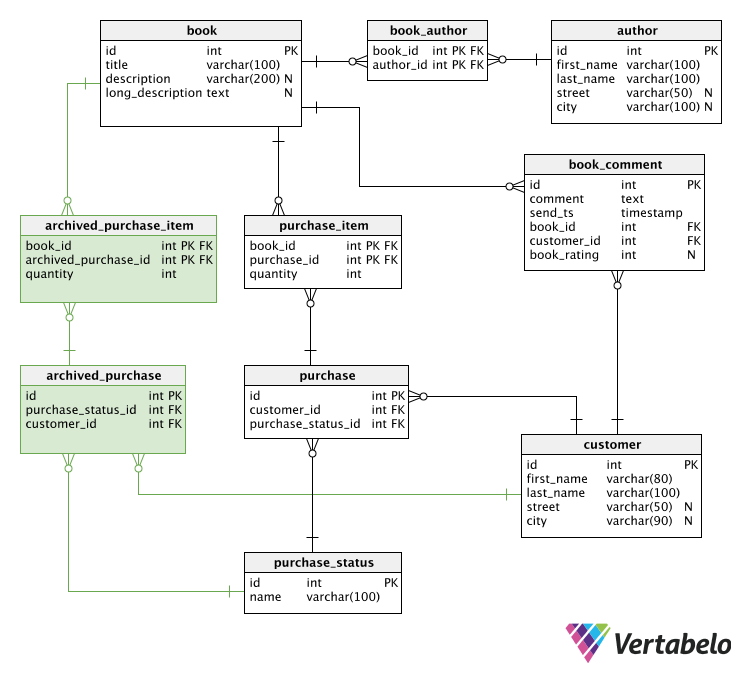
5. Bỏ qua các múi giờ
Điều gì xảy ra nếu bookstore hoạt động trên phạm vi quốc tế? Khách hàng đến từ khắp nơi trên thế giới và sử dụng các múi giờ khác nhau. Quản lý các múi giờ trong các trường date hay datetime có thể là một vấn đề nghiêm trọng trong một hệ thống đa quốc gia.
Hệ thống phải luôn hiển thị đúng ngày và giờ cho người dùng theo múi giờ riêng của họ.
Ví dụ:
Thời gian hết hạn của ưu đãi đặc biệt (tính năng quan trọng nhất trong bất kỳ cửa hàng nào) phải được tất cả người dùng hiểu theo cùng một cách. Nếu bạn chỉ nói "chương trình khuyến mãi kết thúc vào ngày 24 tháng 12", họ sẽ giả định kết thúc vào nửa đêm ngày 24 tháng 12 theo múi giờ của họ. Nếu bạn định nghĩa đêm Giáng sinh là nửa đêm theo múi giờ của mình, bạn phải nói “24 tháng 12, 23,59 giờ UTC” (hoặc bất kỳ múi giờ nào của bạn). Đối với một số người dùng thì giờ này sẽ khác nhau theo từng múi giờ của họ.
Trong trường hợp xử lý các múi giờ, cơ sở dữ liệu phải hợp tác với application code. Cơ sở dữ liệu có các kiểu dữ liệu khác nhau để lưu trữ date và time. Một số loại thời gian lưu trữ với thông tin time zone, một số lưu trữ không có time zone. Các lập trình viên nên phát triển các thành phần tiêu chuẩn hóa trong hệ thống để xử lý các vấn đề múi giờ một cách tự động.
Note:
- Kiểm tra chi tiết các kiểu dữ liệu date và time trong DB. Timestamp trong SQL Server là một cái gì đó hoàn toàn khác với Timestamp trong PostgreSQL.
- Lưu trữ date và time trong UTC.
- Xử lý các time zone đúng cách đòi hỏi sự hợp tác giữa DB và mã của ứng dụng. - Chắc chắn rằng bạn hiểu các chi tiết của database driver
Tham khào và dịch từ bài viết 7 Common Database Design Errors Các bạn có thể xem thêm ở đây.
Thanks for your reading!
All rights reserved
