Cơ sở dữ liệu lưu trữ bảng trên đĩa như thế nào
I. Tổng quan
Khi phát triển một ứng dụng và cấu hình database, việc tạo bảng (table) hay thêm cột (column) chỉ cần vài câu lệnh DDL và việc chèn dữ liệu cũng đơn giản với các câu lệnh DML. Nhưng câu hỏi đặt ra: Liệu những dữ liệu này thực sự được lưu nguyên dạng xuống ổ đĩa?
Câu trả lời là không. Bởi lẽ, máy tính vốn không hiểu table là gì — nó chỉ làm việc với 0 và 1. Vậy làm thế nào để dữ liệu có cấu trúc gọn gàng như tables, columns có thể chuyển thành dạng mà phần cứng có thể xử lý?
Trong bài viết này, chúng ta sẽ cùng tìm hiểu những khái niệm cốt lõi như Heap Files, Index, Clustered Index… để khám phá cách dữ liệu thực sự được lưu trữ và truy xuất ở tầng vật lý.
II. Các khái niệm
1. Row-ID
Về cơ bản, dữ liệu trong một bảng của cơ sở dữ liệu sẽ trông như sau
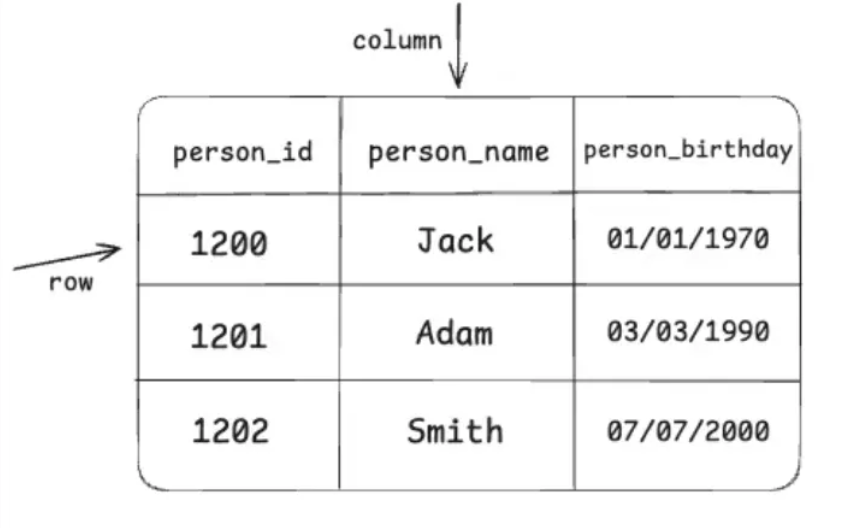
Tuy nhiên, một số loại cơ sở dữ liệu sẽ tạo thêm một trường ẩn trong một dòng dữ liệu.
Ví dụ, trong PostgreSQL, mỗi bảng mặc định có thêm một cột ẩn do hệ thống tạo ra, gọi là row_id (tuple_id, ctid). Cột này giúp PostgreSQL quản lý và theo dõi từng dòng dữ liệu. Đồng thời, nó cũng chính là “tọa độ” để xác định vị trí lưu trữ vật lý của dòng dữ liệu.
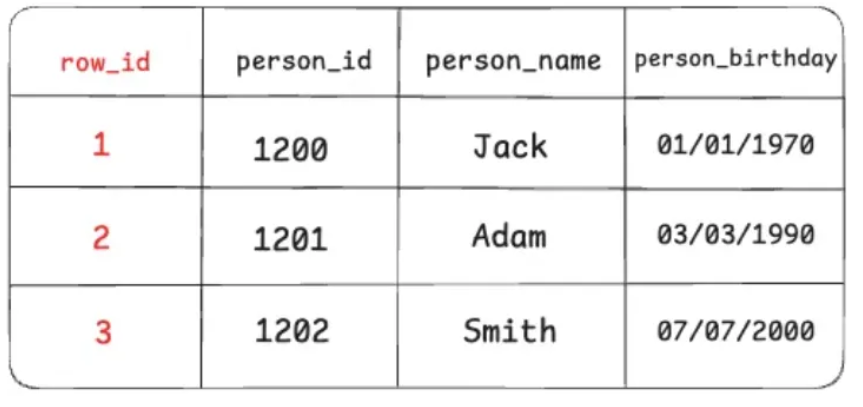
Nhưng không phải tất cả các loại cơ sở dữ liệu đều làm như vậy.
MySQL (sử dụng storage-engine mặc định là InnoDB) dùng chính Primary-Key của dòng dữ liệu làm Row-ID. Nói cách khác, loại cơ sở dữ liệu này xác định vị trí lưu trữ vật lý của dữ liệu bằng khóa chính của dòng dữ liệu. Trong trường hợp này, dữ liệu trên đĩa được sắp xếp vật lý theo thứ tự của Primary-Key. Cơ sở dữ liệu không tạo thêm Row-ID nội bộ, mà Primary-Key sẽ đóng vai trò vừa là định danh duy nhất, vừa là địa chỉ vật lý của dòng dữ liệu.
Nếu bảng không có Primary-Key, InnoDB sẽ tự động tạo một Row-ID có kích thước 6 byte. Cột này không hiển thị với người dùng (hidden column) và được gán duy nhất cho từng dòng dữ liệu, giúp hệ thống xác định và tham chiếu dữ liệu nội bộ.
Trong trường hợp không tồn tại Primary-Key, cột ẩn này trở nên đặc biệt quan trọng, vì nó đóng vai trò định danh duy nhất và hỗ trợ hiệu suất truy xuất. Nói cách khác, nếu bảng không có Primary-Key, InnoDB sẽ buộc phải tạo ra một Row-ID nội bộ để quản lý.
Khái niệm Row-ID này rất quan trọng, bởi khi đi sâu hơn vào cơ chế lưu trữ, chúng ta sẽ thấy nhiều tình huống thực tế mà nó được sử dụng để tối ưu hóa việc truy cập và quản lý dữ liệu.
2. Page
Giờ thì chúng ta đã có một bảng logic với các dòng dữ liệu, cột và bảng. Nhưng thực tế nó được lưu trên đĩa như thế nào? Rõ ràng, ổ đĩa không hề lưu bảng này dưới dạng một table — một khái niệm mà máy tính không hiểu.
Tùy thuộc vào mô hình lưu trữ (row-storage, column-storage, …) các dòng dữ liệu sẽ được lưu trữ và đọc trong các Logical-Pages/Pages hay còn gọi là các Data-blocks.
Định nghĩa mô hình lưu trữ
Mô hình lưu trữ là cách dữ liệu được lưu trữ vật lý trên ổ đĩa.
Trước khi đi vào khái niệm page, hãy tìm hiểu về 2 mô hình lưu trữ row-storage và column-storage trước.
Row Store (Row-based storage)
Đây là mô hình lưu trữ cổ điển và được sử dụng rộng rãi nhất. Được sử dụng trong các nhiều loại RDBMS như MySQL-InnoDB, PostgreSQL, …
Ở mô hình lưu trữ này, toàn bộ giá trị của các cột thuộc cùng một hàng sẽ được lưu trữ liền kề nhau.
Row 1: [id=1, name="Ali", age=25]
Row 2: [id=2, name="Ayşe", age=30]
Ưu điểm: Truy vấn rất nhanh với các thao tác trên hàng (như SELECT * FROM user).
Column Store (Column-based storage)
Đây là mô hình được sử dụng bởi các loại cơ sở dữ liệu như Amazon Redshift, ClickHouse, Apache Parquet files, Google BigQuery, Apache Cassandra,… Ở mô hình lưu trữ này, dữ liệu được lưu trữ theo cột thay vì theo hàng.
Column id: [1, 2]
Column name: ["Ali", "Ayşe"]
Column age: [25, 30]
Ưu điểm: Tốc độ cao với các truy vấn phân tích (như SELECT AVG(age)...) bởi vì chỉ cần đọc những cột cần thiết.
Tiếp theo hãy cùng tìm hiểu đến khái niệm page
Định nghĩa
Page là một khối dữ liệu có kích thước cố định, có thể lưu trữ trong bộ nhớ hoặc trên ổ đĩa.
Cơ sở dữ liệu không đọc từng dòng riêng lẻ, nó đọc một hoặc nhiều page chỉ với một thao tác I/O, nhờ vậy có thể lấy được nhiều dòng dữ liệu cùng lúc.
RAM (Random Access Memory) có thể nhảy ngay đến bất kỳ vị trí nào trong bộ nhớ và đọc đúng phần dữ liệu cần, dù nó rất nhỏ. Ngược lại, ổ đĩa không thể đọc từng phần dữ liệu tùy ý như vậy mà nó luôn phải đọc hoặc ghi theo từng page (khối dữ liệu) có kích thước cố định (ví dụ 4KB, 8KB…) nên dù chỉ cần 1 dòng dữ liệu, toàn bộ page chứa nó vẫn phải được tải lên.
Cơ sở dữ liệu sẽ cấp phát một vùng bộ nhớ gọi là buffer-pool. Các page được đọc từ đĩa sẽ được đặt vào buffer-pool này.
Khi một page đã được tải vào buffer-pool, chúng ta không chỉ nhận được mỗi dòng dữ liệu yêu cầu, mà còn cả những dòng khác nằm trên cùng page đó. Tùy vào dung lượng mỗi dòng dữ liệu chiếm chỗ, chúng ta có thể nhận thêm nhiều dòng dữ liệu và lưu trữ trong bộ nhớ — chỉ nhờ đọc một page duy nhất.
Điều này giúp việc đọc dữ liệu hiệu quả hơn nhiều, đặc biệt là khi thực hiện index-range scan. Nếu các dòng có kích thước nhỏ, nhiều dòng có thể nằm gọn trong một page. Nghĩa là mỗi lần đọc một page từ đĩa, chúng ta thu được nhiều dữ liệu hữu ích hơn, tối đa hóa giá trị của mỗi thao tác I/O.
Nguyên tắc này cũng áp dụng cho việc ghi dữ liệu. Cụ thể hơn, cơ sở dữ liệu nạp page chứa dòng vào buffer-pool, cập nhật trong bộ nhớ và ghi log thay đổi (WAL) xuống đĩa. Page có thể được giữ lại để gom nhiều thay đổi trước khi ghi lại giúp giảm số lần I/O. Các thao tác xóa hoặc chèn dữ liệu cũng tuân theo cơ chế tương tự, dù chi tiết triển khai có thể khác nhau.
WAL là gì ?
Khi cập nhật dữ liệu, cơ sở dữ liệu không ghi trực tiếp vào file dữ liệu, mà trước hết ghi vào một loại log là Write-Ahead Log (WAL). Log này được lưu ngay xuống đĩa để tránh mất dữ liệu khi hệ thống gặp sự cố. Sau đó, dữ liệu thực tế sẽ được cập nhật dựa trên thông tin trong WAL.
Mỗi page thường có kích thước cố định tùy theo hệ quản trị cơ sở dữ liệu (ví dụ: 8KB trong PostgreSQL, 16KB trong MySQL…).
Ví dụ:
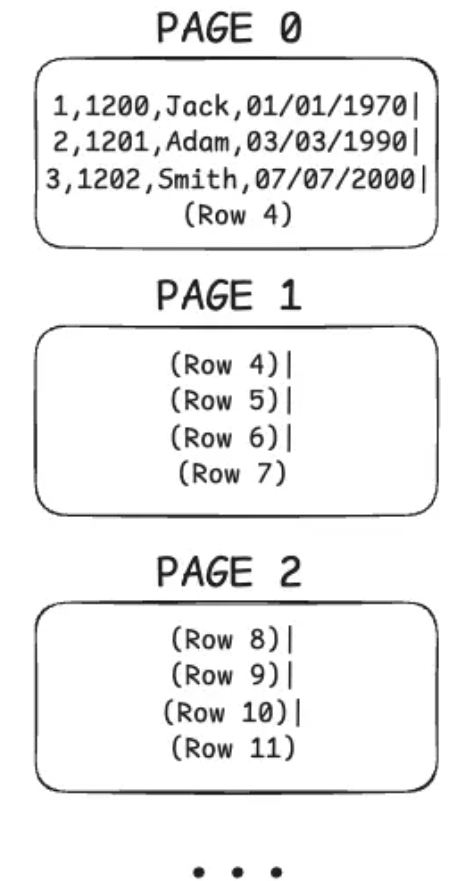
Giả sử mỗi page chứa được 4 dòng và bảng có 1000 dòng. Khi đó, tổng cộng sẽ có 250 page lưu trữ dữ liệu.
Page 0 → chứa hàng 1–4, Page 1 → chứa hàng 5–8, và cứ tiếp tục như vậy.
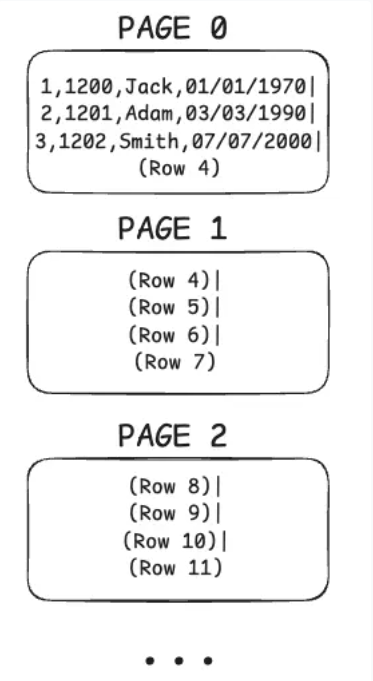
Tóm lại: Cơ sở dữ liệu lưu dữ liệu thành các page có kích cỡ cố định và mọi thao tác đọc/ghi đều diễn ra theo đơn vị page chứ không phải từng dòng. Mỗi lần I/O là một lần tương tác với ổ đĩa (hoặc đôi khi là với cache hệ điều hành) và số lần I/O càng ít thì truy vấn càng nhanh. Vì một page chứa nhiều dòng nên mỗi lần I/O thường đem lại thêm nhiều dữ liệu hơn kì vọng.
3. Heap
Tiếp theo, chúng ta cũng sẽ nói về heap/heap-file. Đây là nơi dữ liệu thực sự tồn tại và toàn bộ dữ liệu của bảng sẽ nằm trong các heap-file.
Chúng ta có thể hình dung heap-file giống như một kho chứa gồm nhiều page và mỗi page chứa nhiều dòng dữ liệu. Các page này không được sắp xếp theo thứ tự nào cả, dữ liệu sẽ được ghi vào bất cứ page nào còn chỗ trống, nên các page có thể nằm rải rác và không liên quan đến nhau.
Điều này đồng nghĩa việc tìm kiếm trong heap thường phải quét toàn bộ bảng (full-table scan).
Tóm gọn:
- Heap-file → chứa các page
- Page → chứa các record (dòng dữ liệu, bản ghi)
Việc duyệt qua heap rất tốn kém vì nó chứa toàn bộ dữ liệu. Đó là lý do chúng ta cần một cơ chế để xác định chính xác page nào chứa dữ liệu cần tìm. Hay nói cách khác, tìm đúng vị trí của dữ liệu trong heap. Đây là vai trò của index - index cho phép ta biết chính xác phần nào của heap cần đọc, tức là cần lấy page nào.
4. Index
Một index thực chất chỉ là một cấu trúc dữ liệu khác (thường là B-Tree) — tách biệt với heap và nó chứa các con trỏ (pointers) trỏ đến dữ liệu thực trong heap.
Vì vậy, index không nằm trực tiếp trong heap, mà tồn tại dưới dạng một cấu trúc riêng, chỉ trỏ đến dữ liệu thật trong heap.
Index lưu trữ một phần thông tin của dữ liệu, được dùng để tìm kiếm nhanh. Chúng ta có thể tạo index trên một cột hoặc nhiều cột cùng lúc.
Nhờ index, cơ sở dữ liệu biết chính xác cần đọc page nào từ heap, thay vì phải quét toàn bộ các page — điều này giúp tăng hiệu năng các truy vấn tìm kiếm.
Tuy nhiên, index không phải là phép màu. Chúng cũng được lưu dưới dạng các page và vẫn cần các thao tác I/O để đọc nội dung. Do đó, cần sử dụng index một cách hợp lý. Index càng nhỏ thì càng nhiều phần của nó có thể được giữ trong bộ nhớ và việc tìm kiếm sẽ càng nhanh.
Xét ví dụ với dữ liệu sau:
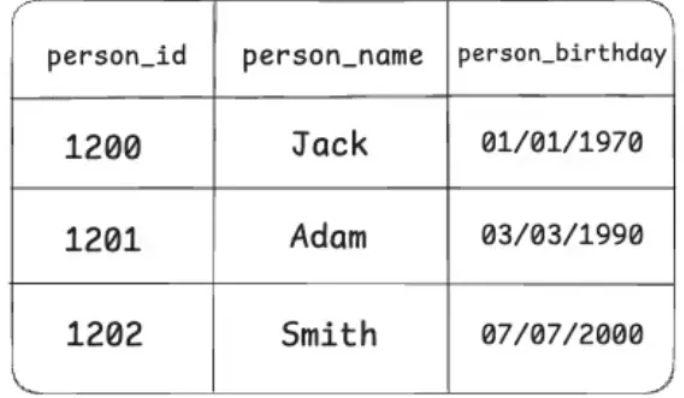
Giả sử chúng ta tạo index cho cột person_id trong bảng. Trong phần heap, dữ liệu được lưu dưới dạng các page trên ổ đĩa.
Khi đó, hệ quản trị cơ sở dữ liệu sẽ tạo một cấu trúc dữ liệu khác để lưu thông tin về index, không nằm trong heap mà được lưu ở một nơi khác (Hình minh họa dưới đây không phải là B-Tree - thực tế index không được lưu tuần tự như vậy mà thường được lưu trong cấu trúc B-Tree để tối ưu tìm kiếm. Tuy nhiên chúng ta sẽ không đi sâu vào phần này).

Sau khi tạo index cho person_id, bên ngoài heap-file, chúng ta có thêm một cấu trúc dữ liệu riêng để chứa index.
Trong đó, với mỗi dòng dữ liệu, index sẽ lưu giá trị của person_id, kèm theo thông tin vị trí của dòng đó.
Ví dụ:
- person_id= 1200 → row_id = 1 ⇒ page 0
- person_id= 1204 → row_id = 5 ⇒ page 1
⇒ row_id (Row-ID) và page đóng vai trò là con trỏ (pointers) giúp định vị chính xác dữ liệu trong heap.
Giả sử, nếu ta muốn lấy name của person_id = 1202:
- Đầu tiên, ta thực hiện một thao tác I/O để đọc index-page và tìm vị trí chính xác của người đó trong heap.
- Khi đã biết vị trí, ta thực hiện thêm một thao tác I/O nữa để truy cập heap, ví dụ: “Lấy page 0 và row_id 3.”. Trên thực tế, ta sẽ đọc toàn bộ page 0, nhưng chỉ dùng dữ liệu ở Row-ID = 3.
Như đã nói trước đó, index trong thực tế không được lưu tuần tự mà được lưu trong cấu trúc B-Tree tối ưu hơn. Nhờ vậy, việc truy xuất từ index-page và tìm đúng person_id sẽ diễn ra rất nhanh - O(log N).
5. Clustered-Index
Như đã nói ở trên, thông thường heap lưu trữ dữ liệu không theo thứ tự cụ thể nào. Nhưng nếu ta tạo một clustered-index trên một cột, dữ liệu của bảng sẽ được sắp xếp dựa trên index đó.
Một bảng chỉ có thể có một clustered-index vì dữ liệu chỉ được sắp xếp vật lý theo một cách duy nhất
Giả sử ta có bảng Users(id, name, age)
- Nếu bảng không có index, nó gọi là heap-table (heap) — dữ liệu lưu không theo thứ tự nào cả, giống như một đống giấy để lộn xộn.
- Nếu tạo clustered-index trên cột
id:- Dữ liệu trong bảng sẽ sắp xếp (vật lý) theo thứ tự của
id. - Điều này giúp truy vấn như
WHERE id = 100nhanh hơn, vì cơ sở dữ liệu có thể tìm trực tiếp theo thứ tự đã sắp xếp.
- Dữ liệu trong bảng sẽ sắp xếp (vật lý) theo thứ tự của
- Trong InnoDB-MySQL:
- Mặc định mọi bảng đều có clustered-index.
- Nếu bảng có Primary-Key, clustered-index sẽ tạo dựa trên cột đó, dữ liệu được lưu theo thứ tự của Primary-Key.
- Nếu bảng không có ****Primary-Key, InnoDB sẽ tạo index dựa trên Row-ID nội bộ (giá trị tăng dần theo thứ tự thêm).
Điều này có nghĩa là trong InnoDB, dữ liệu luôn được lưu theo một thứ tự vật lý nhất định chứ không phải hoàn toàn ngẫu nhiên.
Vì vậy, giả sử nếu chọn UUID làm Primary-Key thì dữ liệu sẽ bị chèn vào các vị trí rải rác, dễ gây phân mảnh và giảm hiệu năng.
UUID Trap
- Tại sao việc sử dụng UUID làm Primary-Key có thể gây ảnh hưởng nghiêm trọng đến hiệu năng ?
Bởi vì UUID là giá trị hoàn toàn ngẫu nhiên, nên mỗi dòng mới sẽ được chèn vào đâu đó ở giữa hoặc một vị trí ngẫu nhiên trong bảng. Điều này khiến InnoDB liên tục phải tổ chức lại dữ liệu, dẫn đến page-split (tách dữ liệu thành page mới khi page đạt ngưỡng) và fragmentation (phân mảnh dữ liệu). Kết quả là thao tác truy cập đĩa và bộ nhớ tăng lên khiến hiệu suất đọc và ghi đều giảm.
Đối với Primary-Key, sử dụng các giá trị số nguyên tăng dần thường tốt hơn vì việc chèn dữ liệu sẽ diễn ra ở cuối bảng, giúp giảm thao tác sắp xếp lại.
Trong InnoDB, các chỉ mục khác (secondary-index) không trỏ trực tiếp đến dữ liệu dòng mà trỏ đến Primary-Key của dòng đó.
![]()
Ví dụ:
CREATE INDEX idx_name ON users(name)
Trong trường hợp này, idx_name trở thành secondary-index và InnoDB sẽ dùng nó để tìm giá trị Primary-Key trước, rồi mới truy cập bản ghi thực sự thông qua khóa chính.
Tuy nhiên PostgreSQL xử lý rất khác so với MySQL. Cụ thể, với PostgreSQL thì mọi index thực ra đều là secondary-index. Vì Postgres tự tạo ra row_id (tuple_id, ctid) để theo dõi dòng dữ liệu. Tất cả các index trỏ trực tiếp đến row_id và row_id cho biết chính xác vị trí của bản ghi trong heap.
Nói cách khác:
Index → trỏ đến row_id → trỏ đến vị trí chính xác của bản ghi
Tuy nhiên, có một điểm quan trọng trong PostgresSQL .
Mọi thao tác UPDATE trong Postgres sẽ cập nhật toàn bộ các chỉ mục của bảng.
Tại sao? Bởi vì khi UPDATE, PostgresSQL thực chất thực hiện DELETE + INSERT. Nghĩa là nó tạo ra một bản ghi mới với tuple_id mới và tất cả các chỉ mục — vì đang trỏ đến tuple_id — đều phải được cập nhật để trỏ đến tuple_id mới này.
Vì sao UPDATE lại là DELETE + INSERT ?
PostgreSQL không cập nhật dữ liệu trực tiếp tại chỗ. Thay vào đó, nó tạo phiên bản mới của dòng dữ liệu (tuple) và giữ nguyên phiên bản cũ để phục vụ các truy vấn đang đọc song song. Sau đó, tiến trình VACUUM sẽ dọn dẹp các dead-tuple này.
Nếu ta xóa một bản ghi rồi chèn một bản ghi mới, kết quả gần như giống hệt:
- 1 dead-tuple
- 1 live-tuple mới
Đó là lý do người ta hay nói UPDATE trong Postgres gần như là DELETE rồi INSERT.
Nguyên nhân là vì Postgres sử dụng MVCC (Multi-Version Concurrency Control) cho phép nhiều giao dịch đọc và ghi dữ liệu cùng lúc mà vẫn đảm bảo tính nhất quán, bằng cách lưu trữ song song cả phiên bản cũ và mới của bản ghi.
III. Tổng kết
- Dữ liệu bảng được lưu trong trang (pages) cố định.
- Cách hoạt động của Heap và Page.
- Cách Index hoạt động
- Primary-Key quyết định thứ tự lưu trữ (clustered-index).
- Nếu dùng giá trị ngẫu nhiên như UUID làm khóa chính, dữ liệu sẽ chèn vào giữa, gây page-split và phân mảnh, làm chậm đọc/ghi.
All rights reserved
