Cơ chế xây dựng context từ dữ liệu chunk
Trong các hệ thống AI dùng mô hình ngôn ngữ lớn (LLM), bài toán không chỉ là “LLM thông minh đến đâu” mà là “LLM được cung cấp đúng thông tin hay không”. Muốn trả lời chính xác, mô hình cần một phần ngữ cảnh (context) thật phù hợp thay vì cả đống tài liệu thô. Cách làm phổ biến hiện nay là chia tài liệu thành các đoạn nhỏ (chunk) và lắp ghép lại đúng lúc mô hình cần. Phần dưới đây sẽ đi qua toàn bộ luồng xử lý từ lúc người dùng gửi câu hỏi (Query) cho đến lúc ta dựng được Prompt hoàn chỉnh để gửi vào model.
Khái niệm nền tảng
Để nắm cơ chế này, có hai mảnh ghép phải rõ:
(1) Chunked data
- Tài liệu gốc (PDF, wiki nội bộ, policy hoàn tiền, hướng dẫn kỹ thuật, ticket support, email trao đổi khách hàng, v.v.) không ném nguyên cục vào hệ thống.
- Thay vào đó, nội dung được cắt nhỏ thành các “chunk” có kích thước vừa phải thường vài trăm đến vài nghìn token.
- Lợi ích: dễ tìm kiếm hơn, tránh bỏ sót thông tin chỉ vì nó nằm sâu giữa một tài liệu dài hàng chục trang.
(2) Context building pipeline
- Là chuỗi các bước có kiểm soát:
người dùng hỏi → hệ thống phân tích → tìm đoạn liên quan → dựng context → tạo prompt cuối. - Vì pipeline rõ ràng nên có thể log, debug, tối ưu từng tầng thay vì xem LLM như một “hộp đen”.
Bây giờ ta bóc tách từng bước chi tiết.
Bước 1: User Query – câu hỏi đầu vào
Tín hiệu khởi đầu luôn là câu hỏi của người dùng. Ví dụ:
- “Chính sách hoàn tiền như thế nào?”
- “Bao lâu thì được đổi trả nếu sản phẩm lỗi?”
Trước khi đem câu hỏi này đi tìm câu trả lời, hệ thống sẽ xử lý sơ bộ (preprocess / normalize), thường bao gồm:
- Loại bỏ ký tự thừa, xuống dòng không cần thiết.
- Chuyển toàn bộ về dạng chuẩn (ví dụ: lowercase).
- Có thể lọc stop-words trong một số pipeline cổ điển.
- Với hệ thống hiện đại hơn, thay vì chỉ nhìn text bề mặt, câu hỏi còn được phân tích ngữ nghĩa để hiểu ý định thật sự (semantic parsing).
Mục tiêu: đưa query về dạng “sạch” và “dễ hiểu cho máy”.

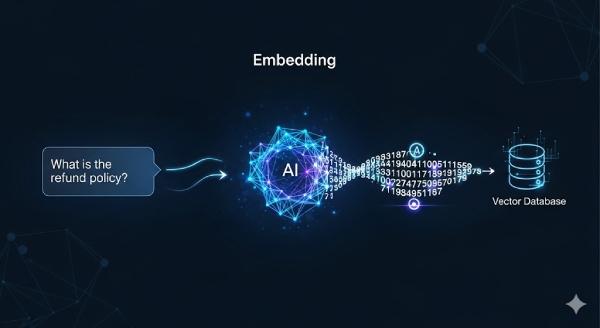
Bước 2: Embedding – biến câu hỏi thành vector số
LLM không tự đi đọc từng tài liệu để đối chiếu. Thay vào đó, ta dùng mô hình embedding để chuyển câu hỏi thành một vector số có nhiều chiều (ví dụ 384, 768, 1536 chiều… tùy model).
- Query → embedding vector.
- Mỗi chunk trong kho tri thức cũng đã được chuyển thành embedding từ trước và lưu trong một vector database (FAISS, Milvus, Pinecone, v.v.).
Ví dụ rất giản lược:
- Câu hỏi: “Chính sách hoàn tiền như thế nào?”
- Embedding đầu ra:
[0.12, -0.44, 0.78, ...](một vector n chiều)
Tức là: thay vì so chuỗi ký tự, chúng ta so “độ gần về ý nghĩa”.
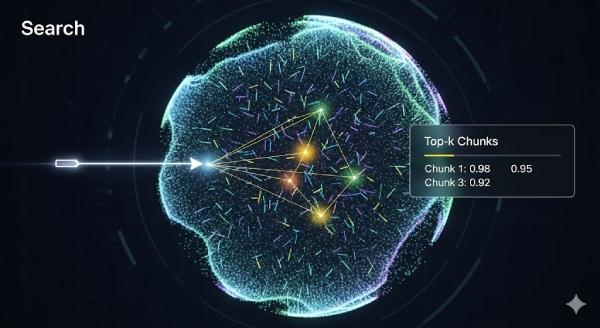
Bước 3: Vector Search – tìm các chunk phù hợp nhất
Đây là khâu truy hồi (retrieval). Hệ thống sẽ:
- Lấy embedding của câu hỏi.
- So khớp nó với embedding của tất cả các chunk đã lưu.
- Đo độ tương đồng bằng cosine similarity, dot product hoặc Euclidean distance.
Kết quả trả về là danh sách top-k chunk có ý nghĩa gần nhất với câu hỏi.
Ví dụ top 3 kết quả:
- Chunk A (score 0.92): phần nói về quy tắc đổi trả sản phẩm.
- Chunk B (score 0.87): hướng dẫn quy trình hoàn tiền.
- Chunk C (score 0.83): thời gian xử lý sau khi xác nhận lỗi.
Điểm số càng cao ⇒ nội dung càng “ăn khớp” với câu hỏi.
Lưu ý: k (số chunk lấy về) thường là 3, 5, 10… tùy bài toán và giới hạn token sau đó.
Bước 4: Lắp ghép Context – xây khối ngữ cảnh cho model
Các chunk truy hồi được sẽ không gửi thẳng từng mảnh rời rạc cho model. Ta cần “đóng gói” chúng thành một khối context có thể đưa vào prompt. Yêu cầu khi dựng context:
- Ngắn vừa đủ: Không vượt quá giới hạn token mà LLM cho phép.
- Giàu thông tin: Phải bao gồm các đoạn thực sự liên quan đến câu hỏi, không lan man.
Có hai kỹ thuật hay dùng:
- Top-k retrieval: Chỉ lấy k chunk có điểm cao nhất.
- Re-ranking: Cho một mô hình khác (ví dụ cross-encoder) chấm điểm lại để chọn ra các đoạn thực sự quan trọng, tránh tình trạng chunk có vẻ giống ngôn ngữ nhưng không trả lời đúng vấn đề.
Ví dụ context đã lắp xong có thể trông như sau (rút gọn):
- “Chính sách hoàn tiền áp dụng cho sản phẩm lỗi kỹ thuật trong vòng 7 ngày kể từ ngày mua.”
- “Quy trình hoàn tiền gồm 3 bước: (1) Gửi yêu cầu xác nhận lỗi, (2) Kiểm tra và phê duyệt, (3) Chuyển hoàn qua phương thức thanh toán ban đầu.”
- “Thời gian xử lý thông thường: 3–5 ngày làm việc.”
Bây giờ ta đã có “nền kiến thức” phù hợp cho câu hỏi cụ thể đó.

Bước 5: Tạo Prompt cuối cùng gửi vào LLM
Đây là lúc ghép tất cả lại: vai trò trợ lý, context tìm được, câu hỏi gốc của người dùng.
Một prompt điển hình sẽ có dạng:
Bạn là trợ lý hỗ trợ khách hàng. Dựa trên thông tin trong phần Context bên dưới, hãy trả lời chính xác và ngắn gọn.
Context:
[ghép các chunk đã chọn]
Câu hỏi của người dùng:
[chính là query ban đầu]
Trả lời:
Lưu ý quan trọng:
- LLM không cần phải “tự tưởng tượng” vì đã có ngữ liệu cần thiết trong Context.
- Đồng thời, vì prompt có cấu trúc rõ ràng, câu trả lời thường bám sát chính sách/tài liệu nội bộ thay vì bịa.
Toàn bộ pipeline nhìn từ trên xuống
Ta có thể hình dung cả dòng chảy như sau:
Query
↓
Embedding câu hỏi
↓
Vector Search / Retrieval (top-k chunk)
↓
Ghép Context từ các chunk phù hợp
↓
Tạo Prompt hoàn chỉnh và gửi vào LLM
Ở mỗi nấc, hệ thống hoàn toàn có thể ghi log:
- Log phiên bản query sau khi normalize.
- Log kích thước embedding (bao nhiêu chiều).
- Log danh sách top-k chunk + điểm tương đồng.
- Log tổng số token của context sau khi ghép.
- Log prompt cuối cùng gửi vào model.
Việc này cực kỳ hữu ích cho việc kiểm tra chất lượng, audit, và debug khi câu trả lời sai lệch.
Kết luận
Pipeline xây dựng context từ dữ liệu đã được chunk không chỉ là một thủ thuật tối ưu truy vấn. Nó chính là nền tảng của các kiến trúc RAG (Retrieval-Augmented Generation), nơi LLM được “tiêm” đúng kiến thức đúng lúc.
Hiểu rõ chuỗi xử lý
Query → Embedding → Retrieval → Context Assembly → Prompt
giúp đội kỹ thuật:
- Triển khai chatbot/assistant có tri thức nội bộ đáng tin cậy.
- Giảm chi phí và tránh lãng phí token không cần thiết.
- Dễ mở rộng kho dữ liệu khi doanh nghiệp lớn dần.
- Tối ưu, giám sát và debug một cách có phương pháp, thay vì cảm tính.
Nói cách khác: bạn không chỉ gọi API LLM để “xin câu trả lời”, bạn đang xây một pipeline kiểm soát tri thức. Và đó mới là sự khác biệt giữa demo AI và hệ thống AI có thể mang ra vận hành thật.
Nguồn tham khảo: https://bizfly.vn/techblog/co-che-xay-dung-context-tu-du-lieu-chunked.html
All rights reserved
