Chuyển đổi dữ liệu giữa hai CSDL khác nhau qua ví dụ thực tế với Ruby
Bài đăng này đã không được cập nhật trong 6 năm
Dữ liệu khổng lồ không phải là điều mà hầu hết chúng ta phải lo lắng hàng ngày. Nhưng thỉnh thoảng, bạn có thể được cung cấp hàng tấn dữ liệu mà bạn phải import vào project của mình. Ví dụ cụ thể sau đây đặt ra vấn đề thực tế mà bạn có thể gặp bất cứ lúc nào.

Backstory
Hãy tưởng tượng chúng ta đang chạy ứng dụng Instagram-esque với Ruby on Rails. Người dùng có thể tải lên hình ảnh và video ở đó và những người dùng khác có thể để lại nhận xét. Mô hình cơ sở dữ liệu của chúng ta có thể trông như thế này:
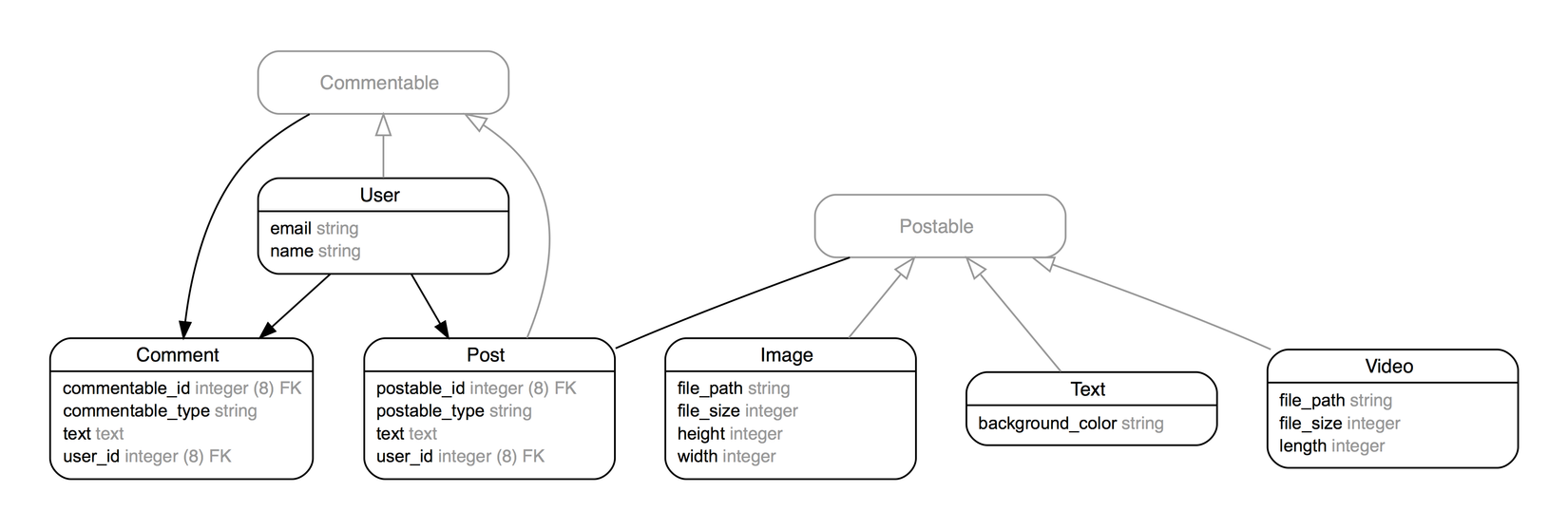
Trong khi chúng ta đang thiết kế cơ sở dữ liệu, thì đã có một project khác đã thành công và mọi người sử dụng ứng dụng của họ. Họ có 100 000 người dùng, mỗi người có 10 hình ảnh, 10 video và 10 bài viết. Mỗi bài viết đã được bình luận 10 lần. Nhưng cơ sở dữ liệu của họ trông như thế này:

Bằng cách nào đó chúng ta đã mua ứng dụng của một bên khác và bây giờ phải hợp nhất dữ liệu của họ vào dữ liệu mà chúng ta có ở trên. Vẫn đề bắt đầu phát sinh, họ đang chạy MySQL trong khi chúng ta đang sử dụng PostgreSQL. Vì hai lược đồ cơ sở dữ liệu đó có vẻ khác nhau khá nhiều và cơ sở dữ liệu của chúng ta đã có một số dữ liệu bên trong, pgloader sẽ không khả thi trong trường hợp này. Chúng tôi có thể thử viết một tác vụ đơn giản để nhập dữ liệu. Mặc dù có hàng trăm cách để làm điều này (hầu hết trong số chúng có thể không thực sự hoạt động tốt), chúng ta sẽ chỉ cùng tìm hiểu các cách được cho là đạt hiệu suất tốt nhất.
Cách tiếp cận cơ bản
Để tranfer dữ liệu, có lẽ chúng tôi muốn tạo một rake task, nhưng để làm được điều này, trước tiên chúng ta phải truy cập "foreign data". Chúng ta có thể tạo các class cho các model một cách đơn giản không? Đầu tiên, chúng ta phải cấu hình cơ sở dữ liệu thứ hai trong config/database.yml bằng cách thực hiện như thế này:
competitor:
adapter: mysql2
database: competitor_prod
username: secret_user
password: secret_password
Tiếp theo chúng ta tạo ra một số class sử dụng connection này:
class OtherUser < ApplicationRecord
establish_connection :competitor
self.table_name = :users
has_many :video_posts, class_name: 'OtherVideoPost', foreign_key: 'user_id'
has_many :image_posts, class_name: 'OtherImagePost', foreign_key: 'user_id'
has_many :text_posts, class_name: 'OtherTextPost', foreign_key: 'user_id'
has_many :profile_comments, class_name: 'OtherProfileComment', foreign_key: 'user_id'
end
Bây giờ tạo một rake task:
task :import do
OtherUser.find_each do |other_user|
user = User.create!(email: other_user.email,
name: other_user.name)
other_user.image_posts.each do |other|
image = Image.create!(file_path: other.file_path,
file_size: other.file_size,
height: other.height,
width: other.width)
Post.create!(postable: image,
user: user,
text: other.text)
...
end
...
end
end
Vấn đề bắt đầu phát sinh ở đây, Comment có liên kết với cả User và Post, làm sao để bổ sung quan hệ này trong rake task. Comment của chúng ta có thể có User và thiếu Post hoặc ngược lại. Điều này có thể được giải quyết dễ dàng bằng cách giữ ID gốc ở CSDL cũ và bổ sung chúng, vì vậy chúng không xung đột với các dữ liệu hiện có. Có thể trông như thế này:
offset = User.maximum(:id)
...
uid = comment.user_id + offset
Comment.new(commentable: postable,
text: comment.text,
user_id: uid).save(validate: false)
Warning!
Vấn đề lớn nhất ở đây là khi bạn dùng cách này, ứng dụng phải tạm dừng nếu không trong quá trình chạy, có bất kì record mới nào được tạo ra sẽ gây ra hậu quả ngiêm trọng.
Bây giờ, khi tạo Comment, chúng ta không thực sự phải chuyển User và Post, ở đó - chúng ta chỉ có thể sử dụng ID, đã tồn tại hoặc cuối cùng (khi tạo Users, chúng tôi phải đặt ID của họ theo cùng một cách).
Nhưng điều này vẫn sẽ thất bại vì Rails mặc định giữ dữ liệu của chúng ta an toàn và thêm các ràng buộc cơ sở dữ liệu. Chúng ta có thể vô hiệu hóa nó ở đầu tập lệnh với:
ALTER TABLE comments DISABLE TRIGGER ALL;
Warning!
Đừng quên bật nó lại khi quá trình kết thúc.
Bây giờ chúng ta có thể chạy rake, tuy nhiên có thể mất đến 60h để hoàn thành, việc dừng ứng dụng quá lâu thực sự có thể gây thiệt hại nên chúng ta cần cân nhắc!
Parallel batch inserts với eager loading và Sequel
Rất nhiều thứ cần phải nói qua tiêu đề trên, tốt nhất chúng ta đi vào giải quyết từng vấn đề, nhìn từ cuối đến lúc bắt đầu:
Sequel
Sequel là một trong những ORM có sẵn cho Ruby (giống ActiveRecord nhưng có dung lượng bộ nhớ ít hơn 3 lần). Với ActiveRecord, chúng tôi sẽ phải phân bổ gần 100 GB trong quá trình nhập của mình, trong khi với Sequel, chúng tôi có thể giữ mức dưới 35 GB. Ít đối tượng để xây dựng = xử lý nhanh hơn.
Eager Loading
Nếu không cẩn thận, chúng tôi có thể gặp phải vấn đề truy vấn N + 1 . Tuy nhiên, nó có thể dễ dàng tránh được với Eager Loading. Trong ActiveRecord chúng tôi làm với .includes và trong Sequel chúng tôi có .eager. Nhưng cả hai đều có cùng một kết quả, đó là giảm số lượng select mà chúng ta thực hiện.
Batch Insert
Vì chúng tôi đã giảm số lượng select, chúng ta cũng nên cố gắng giảm số lượng insert. Cách dễ nhất là tránh lưu riêng từng đối tượng, mà là lưu chúng theo lô lớn hơn. Có một Gem cho việc này, được gọi là activerecord-import . Trong activerecord-import, nó tạo ra các truy vấn SQL như thế này:
INSERT INTO `foo` (`bar`, `baz`) VALUES (1, 2), (3, 4), …
Parallel
Sau khi thực hiện các tối ưu hóa trên, chúng ta có thể xem xét logfile và thấy rằng chúng ta dành thời gian xử lý dữ liệu giữa đọc và ghi chúng vào cơ sở dữ liệu. Chúng ta có thể có thể chạy nhiệm vụ của mình trong một vài quy trình song song để sử dụng toàn bộ cơ sở dữ liệu (khi một quy trình đang viết người khác có thời gian để chuẩn bị dữ liệu). Bạn có thể chưa bao giờ thực hiện xử lý song song trong Ruby, nhưng nó thực sự khá dễ dàng:
4.times do |i|
fork do
...
end
end
Process.waitall
Bây giờ chúng tôi có thể chạy quá trình nhập vào và nó hoàn thành chỉ sau 3,6 giờ . Chỉ với một vài thay đổi dễ dàng, chúng tôi đã đạt được tốc độ tăng gấp 15 lần. Liệu còn cách nào nhanh hơn không?
Skipping Ruby
Phương pháp trước thực sự hữu ích vì nó cho phép chúng tôi thực hiện bất kỳ loại xử lý dữ liệu nào - chúng tôi có thể đã thực hiện các công việc như tạo mật khẩu cho User hoặc trích xuất một cái gì đó từ JSON trước khi lưu vào cơ sở dữ liệu. Nhưng nếu chúng ta xem xét kỹ hơn bài toán mà chúng ta đang giải quyết, chúng ta có thể thấy rằng việc xử lý duy nhất chúng ta cần là bổ sung ID. Nếu vậy chúng ta hoàn toàn có thể làm việc trực tiếp với SQL.
Vậy điều gì sẽ xảy ra nếu chúng ta có thể bỏ qua ActiveRecord, Sequel và tất cả những thứ làm giảm hiệu suất ở trên và cố gắng di chuyển dữ liệu của chúng ta bằng SQL? Để tải dữ liệu vào Postgres, chúng ta có thể sử dụng COPY, tốc độ này thậm chí còn nhanh hơn batch insert và cho phép đọc dữ liệu từ tệp văn bản. Mặt khác, chúng ta có MySQL có thể lưu kết quả được chọn vào tệp CSV. Chúng ta sẽ cố gắng làm cho chúng hoạt động cùng nhau?
file = "/tmp/#{SecureRandom.uuid}"
select = <<~MySQL
SELECT id + #{@user_offset}, email, name, created_at, updated_at
FROM users
INTO OUTFILE '#{file}_users'
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n';
MySQL
copy = <<~PostgreSQL
COPY users (id, email, name, created_at, updated_at)
FROM '#{file}_users'
WITH CSV;
SELECT setval('users_id_seq', (SELECT MAX(id) FROM users));
PostgreSQL
OLD.run(select)
ActiveRecord::Base.connection.execute(copy)
Không thể dễ dàng hơn. Và kết quả vượt sức mong đợi. Nhập tất cả dữ liệu (mất 60h cho cáchđầu tiên) hoàn thành chỉ sau 8 phút . Hơn 430 lần!
Bài viết được dịch từ tác giả Maciek Głowacki
All rights reserved
