Chức năng tự động suggest tag sử dụng Cosine similarity
Bài đăng này đã không được cập nhật trong 7 năm
Giới thiệu
Lại là mình và bài toán suggest tag, hy vọng các bạn đọc về chủ để này không thấy chán vì để hoàn thành được 1 chức năng hoàn chỉnh và có độ phức tạp cao, thì không thể dừng lại ở một hoặc hai bài viết được.
Do đó ở bài viết này mình sẽ cùng bàn về bài toán so sánh độ tương đồng giữa các văn bản. Đây là một bài toán được nhiều người nghiên cứu và cũng có rất nhiều bài luận văn, luận án viết về đề tài này. Ước lượng độ tương đồng đóng vài trò ngày một quan trọng trong quá trình nghiên cứu, ứng dụng liên quan đến văn bản:
- Phân loại văn bản
- Tìm kiếm (google search)
- Phát hiện chủ đề
- Trích xuất thông tin
Việc so sánh độ tương đồng có thể suggest tag được không thì mình xin trả lời là có. Giả sử bạn có một tập các văn bản đã được phân loại với các tag tương ứng, sau đó khi thêm mới một văn bản việc bạn cần làm là so sánh độ tương đồng giữa các văn bản, cuối cùng văn bản mới được thêm vào sẽ được phân loại tag tương ứng với văn bản có độ tương đồng lớn nhất trong master data đưa vào.
Tiếp theo là các thuật toán được dùng để so sánh độ tương đồng
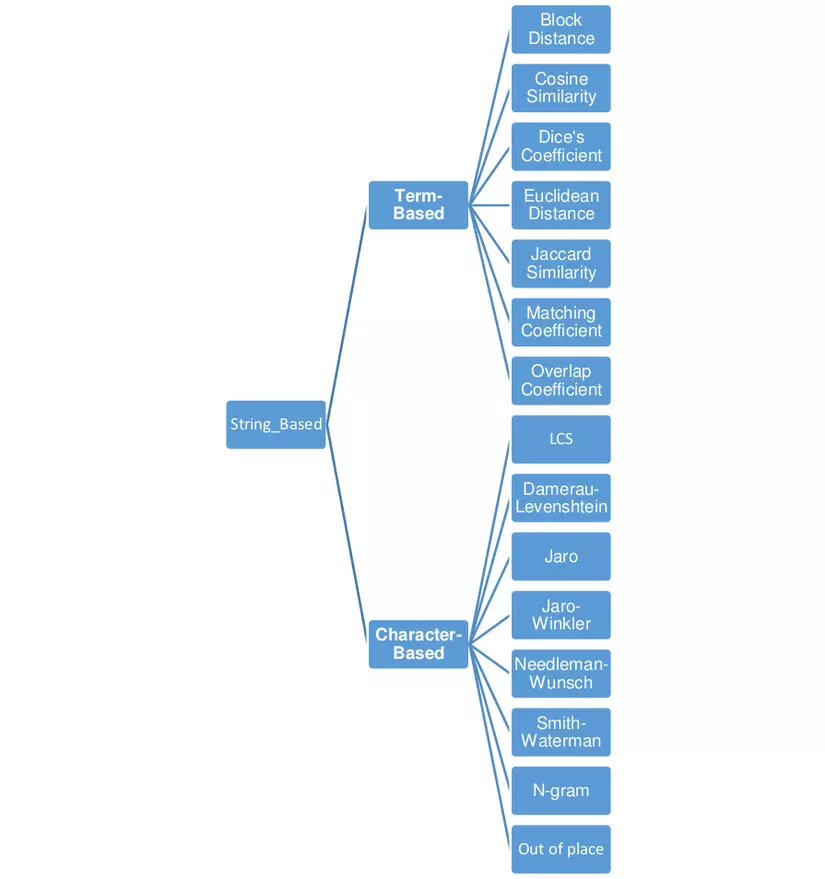
Trên đây mới chỉ là những thuật toán so sánh độ tương đồng dựa vào phân tích cấu trúc ngữ pháp trong câu. Ngoài ra còn có 1 hướng nghiên cứu nữa đó là phân tích ngôn ngữ tự nhiên sử dụng mạng ngữ nghĩa giữa các từ VD:
- Wordnet corpus
- Brown corpus
Trong bài viết này mình sẽ giới thiệu thuật toán Cosine similarity(nằm ở nhánh term base trong ảnh phía trên) từ đó áp dụng vào nhiệm vụ cụ thể là suggest task
Vector Space Model – Cosine Similarity
Ý tưởng của bài toán này là việc biến 2 văn bản cần so sánh thành 2 vector rồi từ đó tính toán khoảng cách giữa 2 vector đó. Công thức để tính khoảng cách của 2 vector trong không gian như sau:
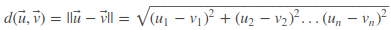
Ví dụ, ta có 2 vecctor như sau: u⃗ =(2,3,4,2) and v⃗ =(1,−2,1,3). Như vậy ta sẽ tính khoảng cách Euclidean như sau:

Tạm thời dừng lại ở đây nhé và quay trở lại với vấn đề làm thế nào để đưa văn bản thành vector model để tính toán như ví dụ trên được. Có 1 cách rất đơn gian đó là sử dụng kỹ thuật cơ bản tf-idf để đưa văn bản về dạng vector như sau
Cách tính tf-idf mình đã giới thiệu ở các bài viết trước của mình, các bạn có thể tham khảo ở đây. Sau đây là ví dụ mình thực hiện chuyển đổi văn bản về dạng vector:
Văn bản 1: A snake attacks a frog. A crocodile also attacks the frog.The crocodile wins. It then eats the frog while the snake changes his target to a toad.
Văn bản 2: A snake follows a frog. It then eats the frog. And a crocodile follows the snake. Then It eats the snake. It continues to follow an other toad.
Master data: A snake attacks a frog. A crocodile also attacks the frog.The snake losses. It updates his target to a toad while the crocodile eats the frog.
Áp dụng tf-idf ta sẽ có kết quả như sau :
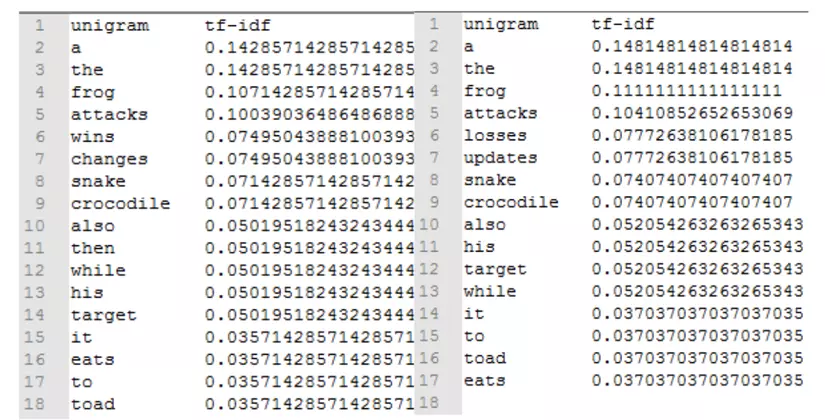
Tiếp theo ta sẽ xây dựng vector cho 2 văn bản dựa vào các từ xuất hiện ở cả 2 văn bản: a, the, snake, attacks, frog, crocodile, also, losses, it, updates, his, target, while, toad, eats, to, follows, wins, changes, then. Văn bản không chứa các từ trên sẽ để tọa độ là 0
Do đó ta sẽ xây dựng được vector có tọa đô như sau:
| a | the | snake | attacks | frog | crocodile | also | losses | it | updates | his | target | while | toad | eats | to | wins | changes | then | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| V1 | 0.14 | 0.14 | 0.071 | 0.1 | 0.1 | 0.07 | 0.05 | 0 | 0.035 | 0 | 0.05 | 0.05 | 0.05 | 0.035 | 0.035 | 0.035 | 0.07 | 0.07 | 0.05 |
| V2 | 0.14 | 0.14 | 0.074 | 0.1 | 0.11 | 0.07 | 0.05 | 0.07 | 0.037 | 0.07 | 0.052 | 0.052 | 0.052 | 0.037 | 0.037 | 0.037 | 0 | 0 | 0 |
Sau khi đã có vector tọa độ của các 2 văn bản cần so sánh, áp dụng công thức tính khoảng cách như sau:
Cosine Similarity (d1, d2) = Dot product(d1, d2) / ||d1|| * ||d2||
Trong đó
Dot product(d1, d2) = d1[0]*d2[0] + d1[1]*d2[1] + ....d1[n]*d2[n]
||d1|| = square root( d1[0]^2 + d1[1]^2 + ... + d1[n]^2 )
||d2|| = square root( d2[0]^2 + d2[1]^2 + ... + d2[n]^2 )
Sau khi tính toán ta sẽ có kết quả như sau: Cosine Similarity (V1, V2) = 0.8853377409
Ý nghĩa của kết quả trên cho ta biết rằng cosine của góc θ giữa 2 vector(v1, v2) có giá trị là 0.88 ngoài ra cos 0° = 1 và cos 90° = 0

Như vậy nếu giá trị Cosine Similarity tiệm cận về 1 có nghĩa rằng 2 vector có độ tương đồng lớn và ngược lại. Do vậy 2 văn bản v1 và v2 giống nhau.
Áp dụng vào bài toán suggest tag
Quay về với bài toán thực tế suggest tag. Giả sử trong DB hiện tại đã có những câu hỏi, hoặc đoạn text đã được gán nhãn từ trước rồi. Như vậy nhiệm bây giờ của bạn là
- Khi có một câu hỏi mới hoặc một đoạn text mới được nhập vào.
- So sánh input mới nhập vào với master data đã được tạo sẵn.
- Sau đó lấy ra 5 câu hỏi có độ tương đồng lớn nhất.
- Trả về nhãn đã được gán của 5 câu
Để kết quả trả về tốt hơn, bạn có thể đặt ngưỡng cho kết quả phải lớn hơn 0.5
Mình chảy thử trên rails console trước để xem kết quả trả về sau khi implement service cosine similarity
~/workspace/react_rails/suggest-api$ rails c
Running via Spring preloader in process 32330
Loading development environment (Rails 5.2.1)
[1] pry(main)> a = AutoSuggestService.new
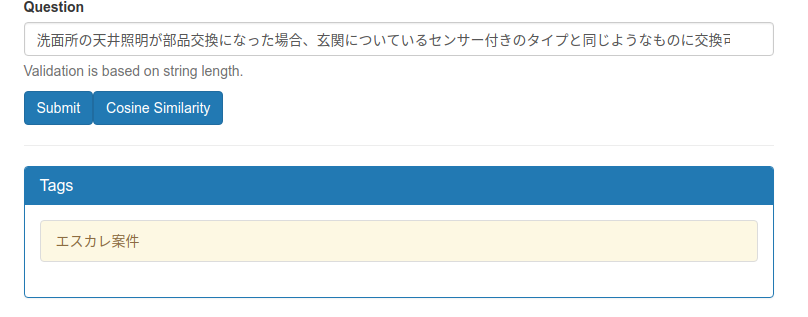
[2] pry(main)> hash_tag = a.make_tag("洗面所の天井照明が部品交換になった場合、玄関についているセンサー付きのタイプと同じようなものに交換可能か。")
[3] pry(main)> a.read_corpus(hash_tag)
=> ["エスカレ案件"]
Thử kiểm tra xem đoạn text được gán nhãn ở phía trên có tương đồng với input đầu vào không?
[1] pry(main)> a = AutoSuggestService.new
[2] pry(main)> hash_tag = a.make_tag("洗面所の天井照明が部品交換になった場合、玄関についているセンサー付きのタイプと同じようなものに交換可能か。")
[3] pry(main)> a.read_corpus(hash_tag)
=> [{"洗面所の天井照明が部品交換となった場合、玄関についているセンサー付きのタイプと同じようなものに交換可能か。"=>"エスカレ案件"}]
Gía trị cosine similarity của 2 đoạn text trên là 0.9287512759928362. Như vậy các bạn có thể thấy độ chính xác của thuật toán cũng khá cao
Việc còn lại bây giờ là implemt thử trên front-end:
Kết luận
Cảm ơn các bạn đã đọc bài viết của mình. Có thể bài viết của mình còn những chỗ chưa chính xác nhưng mà mình cũng cố gắng để đảm bảo nội dung được đầy đủ và chính xác nhất, các bạn có thể comment ở phía dưới để mình cải thiện nhé.
Trong bài này mình show source code lên bởi vì có nhiều đoạn mình viết ẩu chưa kịp refactor. Tuy nhiện nếu bạn mà thích nghiên cứu thì cứ xem ở trên github của mình nhé(project mình viết trên nền tàng ruby on rails)
https://github.com/duongpham910/suggest-api
Tài liệu tham khảo:
All rights reserved
