Chỉ mục(index) trong cơ sở dữ liệu (Phần 1)
Bài đăng này đã không được cập nhật trong 8 năm
Tối ưu câu truy vấn có thể hiểu đơn giản là việc cải thiện tốc độ truy vấn tới cơ sở dữ liệu bằng cách thay đổi các câu truy vấn sang một kiểu khác. Có nhiều phương pháp đã được đưa vào sử dụng như phá truy vấn lồng, sử dụng bảng tạm thời,… Nhưng trong số đó thì sử dụng đánh chỉ mục (index) được sử dụng rất phổ biến. Bài viết này sẽ đưa ra một cái nhìn khái quát về chỉ mục cũng như việc sử dụng chỉ mục một cách hiệu quả trong một số trường hợp thường gặp.
Chú ý: Ở đây chỉ đề cập tới kiểu chỉ mục cây cân bằng (B-Tree Index)
Khái quát về chỉ mục
"Chỉ mục (index) làm tăng tốc độ của câu truy vấn” đó sẽ là hầu hết suy nghĩ ban đầu của mọi người khi nhắc đến chỉ mục. Tuy nhiên nó chưa hẳn là đúng đắn. Vì vậy, trước khi đưa ra các cách để sử dụng chỉ mục một cách hiệu quả, ta nên biết một cách tổng quát về cấu trúc của chỉ mục.
1. Cấu trúc của một chỉ mục
Một chỉ mục là một cấu trúc riêng biệt trong cơ sở dữ liệu, nó được tạo ra bằng câu lệnh CREATE INDEX. Nó cần có không gian lưu trữ riêng trên thiết bị lưu trữ (đĩa cứng) và có một phần bản sao của dữ liệu của bảng được lập chỉ mục. Điều này có nghĩa rằng việc tạo ra một chỉ mục là có sự dư thừa về dữ liệu. Tạo một chỉ mục không thay đổi dữ liệu của các bảng; nó chỉ tạo một cấu trúc dữ liệu mới và nó trỏ đến bảng ban đầu.
Tìm kiếm trong chỉ mục giống như là tìm kiếm trong một danh mục điện thoại. Điểm mấu chốt ở đây là tất các mục được sắp xếp theo một thứ tự được định nghĩa trước. Thực hiện tìm dữ liệu trong một tập dữ liệu đã được sắp xếp là nhanh và dễ dàng hơn bởi vì đã có thứ hạng sắp xếp cho các phần tử.
Chính vì lí do các mục được sắp xếp theo một thứ tự nào đó nên khi thực hiện các hành động như UPDATE, INSERT, DELETE bảng được đánh chỉ mục thì chi phí thời gian sẽ tiêu tốn hơn rất nhiều vì có thêm cả việc xây dựng lại chỉ mục. Vì vậy, ta cũng nên xem xét tần suất sử dụng các câu truy vấn làm thay đổi bảng dữ liệu ban đầu để quyết định xem có nên sử dụng đánh chỉ mục cho bảng đó hay không.
Một cơ sở dữ liệu (CSDL) thông thường sử dụng kết hợp hai cấu trúc dữ liệu để làm nên một chỉ mục: danh sách liên kết đôi (a doubly linked list) và một cây tìm kiếm (a search tree). Hai cấu trúc dữ liệu này giải quyết hầu như tất cả các vấn đề về hiệu suất của cơ sở dữ liệu.
Có 2 khía cạnh cần xem xét ở cấu trúc của một chỉ mục. Đó là: Nút lá chỉ mục (The index leaf node) và Cây tìm kiếm cân bằng (B – Tree)
1.1. Nút lá chỉ mục (The index leaf node)
Nút lá chỉ mục sẽ sử dụng danh sách liên kết đôi nhằm tối ưu các câu truy vấn làm thay đổi dữ liệu bảng (insert, delete, update) dẫn đến thay đổi cấu trúc của chỉ mục. Mỗi nút lá được lưu trữ trong một đơn vị lưu trữ gọi là block hay page. Tất cả các block có cùng kích thước và chỉ khoảng một vài Kilobytes (thông thường là 4KB, bằng với kích thước trang lưu trữ page trên đĩa cứng). Cơ sở dữ liệu sử dụng không gian trong mỗi block để lưu trữ càng nhiều phần tử chỉ mục càng tốt. Điều này có nghĩa rằng trật tự sắp xếp của chỉ mục được duy trì trên hai mức khác nhau: thứ tự sắp xếp của các phần tử chỉ mục trong mỗi nút lá và giữa các nút lá bằng cách sử dụng danh sách liên kết đôi.

Hình 1. Nút lá chỉ mục và dữ liệu bảng tương ứng
Đây là hình ảnh minh họa các nút lá chỉ mục và các kết nối của chúng tới bảng dữ liệu. Mỗi phần tử chỉ mục bao gồm một cột được đánh chỉ mục (column 2) và một tham chiếu tới bản ghi tương ứng trên bảng dữ liệu (ROWID hay RID).
1.2. Cây tìm kiếm cân bằng (B – Tree)
Các nút lá chỉ mục được lưu trữ theo một thứ tự tuỳ ý tức là vị trí trên ổ đĩa không tương ứng với vị trí logic khi đánh chỉ mục. Cơ sở dữ liệu cần một cấu trúc dữ liệu thứ hai để có thể tìm được một mục trong các trang bị xáo trộn một cách nhanh nhất đó là một cây tìm kiếm cân bằng – gọi tắt là B-tree.
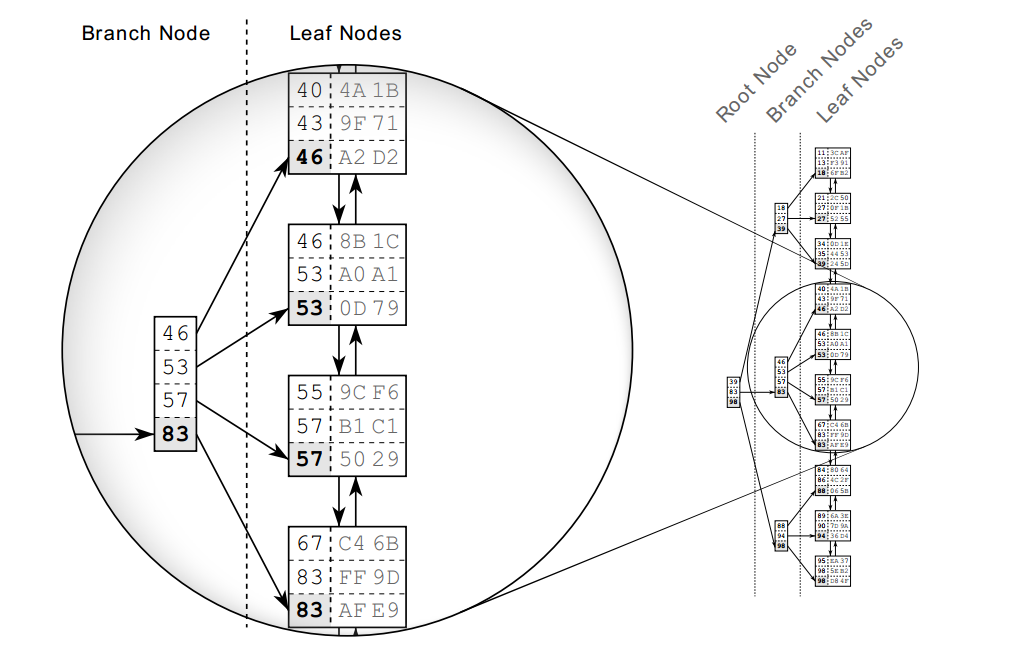
Hình 2. Cấu trúc của B-tree
Hình 2 là ví dụ về một index với 30 phần tử. Danh sách liên kết đôi thiết lập các thứ tự logic giữa các nút lá. Các nút gốc (root nodes) và các nút nhánh (branh nodes) hỗ trợ tìm kiếm nhanh chóng các nút lá.
Sau khi được tạo, cơ sở dữ liệu phải duy trì index một cách tự động. Mọi thao tác insert, delete, update đều phải cập nhật index và giữ cho cây luôn ở trạng thái cân bằng.
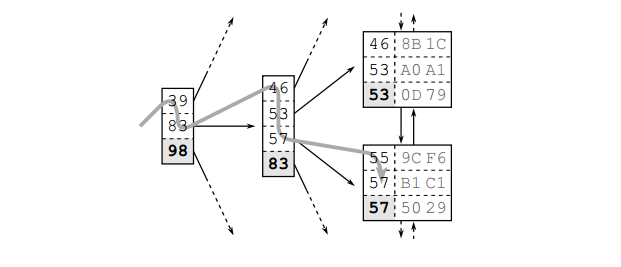
Hình 3. Quá trình duyệt B-tree
Hình 3 mô tả quá trình tìm kiếm cho từ khoá là “57”. Quá trình duyệt cây bắt đầu từ nút gốc phía bên trái. Khoá sẽ được so sánh lần lượt với các phần tử trong nút theo thứ tự tăng dần cho đến khi có phần tử lớn hơn hoặc bằng (>=) với khoá (57). Như trong hình thì phần tử đó chính là 83. Từ đó cơ sở dữ liệu sẽ được trỏ tới nút nhánh tương ứng và lặp lại quá trình như trên cho đến khi tới nút lá.
2. Ưu điểm của việc sử dụng chỉ mục
Đầu tiên, ta có thể nhận thấy rằng việc sử dụng chỉ mục sẽ không ảnh hưởng tới dữ liệu ban đầu. Mọi hành động xóa hay tạo chỉ đơn giản là thực hiện trên một bản dữ liệu khác tham chiếu tới dữ liệu của bảng, mà nó chỉ liên quan đến bộ nhớ. Do đó, ta không phải lo lắng đến việc mất hay hỏng dữ liệu.
Việc sử dụng chỉ mục giúp cải thiện tốc độ cho các câu lệnh SELECT hay JOIN có các mệnh đề WHERE. Có được điều đó là bởi chỉ mục sử dụng cấu trúc cây cân bằng. Duyệt cây là một thao tác khá hiệu quả, nó thể hiện sức mạnh của cấu trúc đánh chỉ mục. Sử dụng chỉ mục trả về kết quả rất nhanh ngay cả khi với một tập dữ liệu rất lớn. Điều này bởi vì cây cân bằng cho phép truy cập tất cả các phần tử với số lượng các bước như nhau và độ sâu của cây chỉ tăng theo hàm logarit. Độ sâu của cây tăng rât chậm so với số lượng các nút lá. Trong thực tế quá trình đánh chỉ mục thực hiện trên hàng triệu bản ghi thì độ sâu của cây cũng chỉ là 4 hoặc 5.
3. Một số vấn đề gặp phải khiến sử dụng chỉ mục bị chậm
Như đã nói thì chỉ mục sẽ làm tốn chi phí thời gian cho các hoạt động như UPDATE, DELETE, INSERT. Tuy nhiên, ở đây sẽ tập trung nói về việc sử dụng chỉ mục cho các hoạt động khác (như SELECT, JOIN) mà tưởng chừng như là cải thiện tốc độ nhưng vô tình làm giảm tốc độ của câu truy vấn.
Một quá trình tra cứu chỉ mục gồm 3 bước: (1) quá trình duyệt cây; (2) duyệt các nút lá kế tiếp; (3) lấy dữ liệu từ bảng. Quá trình duyệt cây là bước duy nhất có giới hạn trên cho số lần truy cập các block – độ sâu của cây. Hai bước còn lại có thể truy cập nhiều block – chúng là nguyên nhân tại sao quá trình tra cứu chỉ mục chậm đi.
Điều đầu tiên khiến cho một tra cứu chỉ mục chậm đi là do chuỗi các nút lá. Ta xem xét lại ví dụ trong Hình 3 với quá trình tìm kiếm “57”. Rõ ràng ta thấy có hai phần tử khớp trong chỉ mục. Có ít nhất 2 phần tử giống nhau hay nói chính xác hơn là: có thể có nhiều phần tử ở các nút là tiếp theo cũng có giá trị là “57”. Cơ sở dữ liệu phải đọc các nút lá tiếp theo để xem nếu có bất kỳ phần tử nào khớp với giá trị cần tìm kiếm. Điều này có nghĩa rằng một quá trình tra cứu chỉ mục không chỉ cần thực hiện việc duyệt cây mà cũng cần thực hiện việc duyệt trên chuỗi các nút lá.
Điều thứ hai có thể làm một tra cứu chỉ mục chậm đi là quá trình truy cập bảng. Một nút lá bao gồm nhiều nút chỉ mục, thường hàng trăm, mỗi nút chỉ mục trỏ tới một dòng dữ liệu trong bảng ở những vị trí lưu trữ khác nhau. Bảng dữ liệu tương ứng thường nằm rải rác trên nhiều block (Hình 1).
Kết luận: Từ những vấn đề trên, một số cách sử dụng chỉ mục hiệu quả sẽ được đề xuất trong phần tiếp theo của bài viết.
Tài liệu tham khảo: SQL Performance Explained - MARKUS WINAND
All rights reserved
