Cassandra DB - P1 - Overview
Bài đăng này đã không được cập nhật trong 4 năm
Đây là bài viết trong một series mình giới thiệu về CSDL Cassandra, nhằm hướng tới các bạn làm Devops/SRE bao gồm các nội dung:
- Giới thiệu tổng quan về CSDL Cassandra
- Hướng dẫn cài đặt cấu hình một hệ thống lab
- Hướng dẫn tạo dữ liệu cơ bản và kiểm tra các thông số hoạt động của hệ thống
- Hướng dẫn thực hiện backup/restore một hệ thống CSDL Cassandra
- Các thao tác quản trị hệ CSDL Cassandra
Tổng quan về CSDL Cassandra
Cassandra là gì
Apache Cassandra (Cassandra) là một CSDL NoSQL tương tự như MongoDB hay Amazon Dynamo được phát triển bởi Facebook.
Cassandra là hệ cơ sở dữ liệu phân tán, dữ liệu được lưu trữ trên nhiều node của nhiều máy khác nhau, theo cơ chế P2P. Hiệu năng xử lý của hệ thống cũng tăng theo số node (Performance tăng theo số node có trong cluster).
Hiệu năng của nó cũng rất lớn với throughput có thể đạt tới hàng triệu write/s với cấu hình 288 nodes theo kết quả thử nghiệm của Netflix. Các bạn có thể tham khảo thêm ở đây: https://medium.com/netflix-techblog/benchmarking-cassandra-scalability-on-aws-over-a-million-writes-per-second-39f45f066c9e
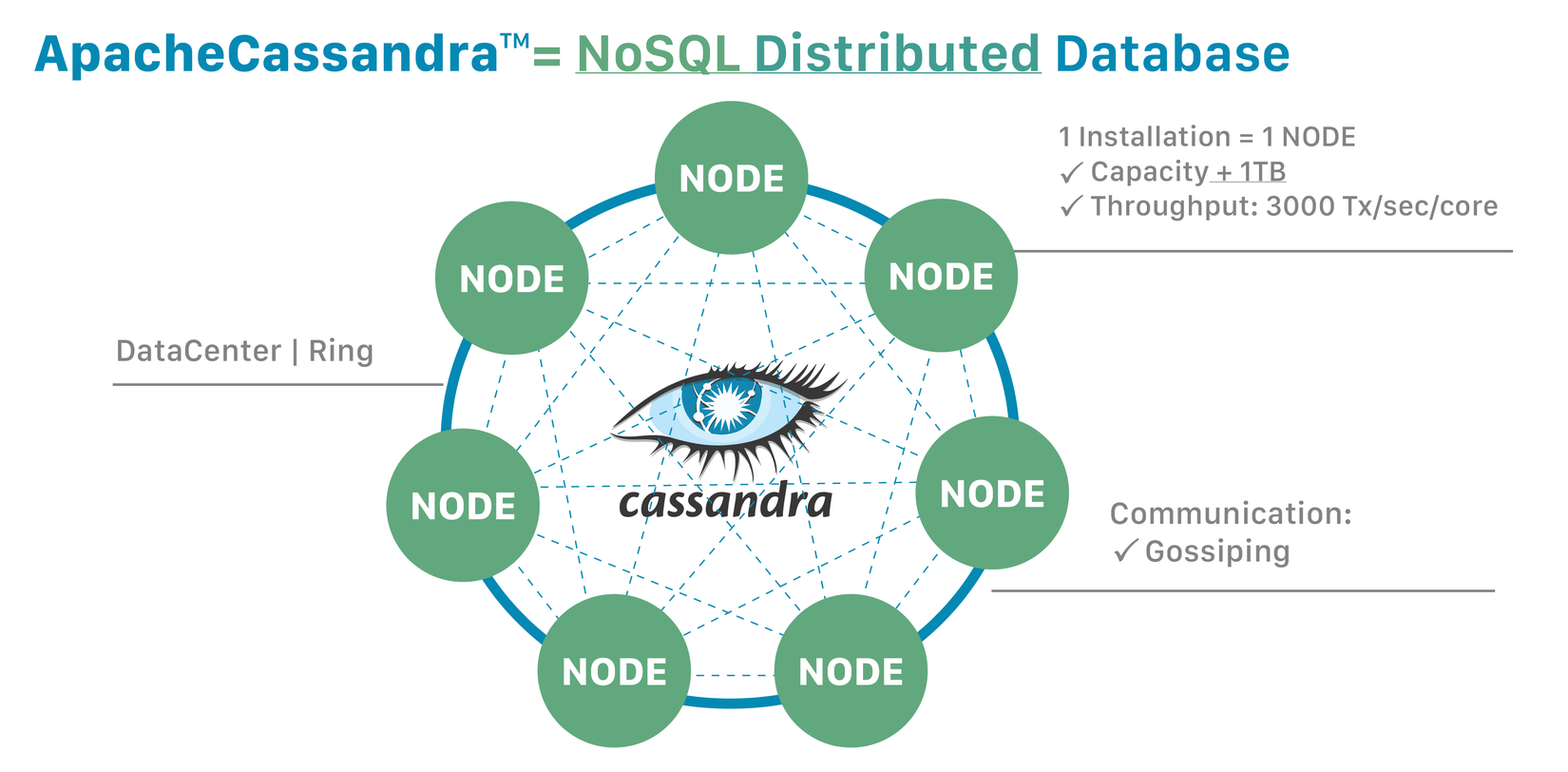
Cơ chế ghi dữ liệu được phân tán dựa trên một hash function giúp phân chia xử lý tới các node trong cluster. Mội node sẽ chịu trách nhiệm xử lý một phần của dữ liệu, gọi là Data Partitioning. Kết hợp với tính năng Replica của các Partition, thì khi một node bị lỗi sẽ không gây ảnh hưởng tới hoạt động của cả hệ thống.
Một số đặc tính nổi bật của Cassandra bao gồm:
- Scalability: Khả năng mở rộng cao
- Availability: Tính sẵn sàng cao
- Reliability: Độ tin cậy cao
- Distributed: Là CSDL phân tán
- Masterless: Không sử dụng cơ chế Master-Slave mà các node đều đóng vai trò như nhau trong xử lý dữ liệu
Các khái niệm chính của Cassandra
- Node: Là một thực thể thực hiện xử lý và lưu trữ dữ liệu. Bạn có thể cài nhiều node trên cùng một server nhưng thực tế thì là điều không khuyến nghị vì khi server bị down sẽ gây ảnh hưởng nhiều hơn 1 node
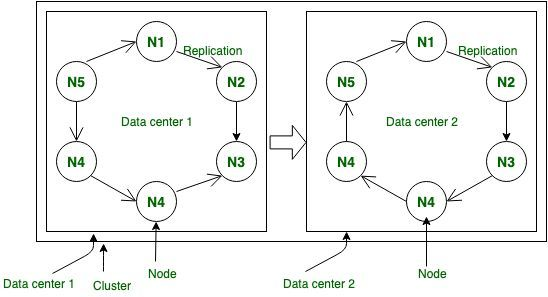
- Rack: Đây là một khái niệm logic chỉ một nhóm các node có chung nguy cơ bị lỗi. Ta hiểu như các node này là các server cài chung một rack thì sẽ có chung nguy cơ khi rack đó bị sập (về nguồn/mạng..)
- Datacenter: Là một tập hợp các node mà chứa đủ thông tin dữ liệu. Như mô tả bên trên, các node sẽ xử lý một phần của dữ liệu. Một tập các node xử lý đủ 100% dữ liệu gọi là một datacenter.
- Cluster: Là thành phần mà có thể chứa một hoặc nhiều datacenter
![image.png]()
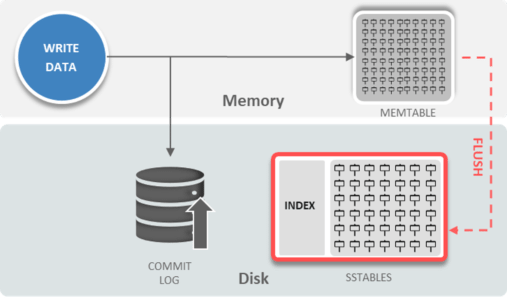
- Commitlog: Là cơ chế để xử lý khôi phục sự cố (crash-recovery mechanism). Mọi thao tác ghi dữ liệu (write operation) đều được ghi vào commitlog
- Memtable: Là một kiến trúc dữ liệu lưu trên bộ nhớ (In-memory data). Là nơi chứa thông tin dữ liệu được update trên memory mà chưa được update xuống disk.
- SStable (Sorted String Table): Là một bảng ánh xạ của các cặp key-value đã được sắp xếp và không thay đổi. Đây là một cách hiệu quả để lưu một đoạn dữ liệu lớn đã được sắp xếp trong file. Chúng ta sẽ làm rõ hơn về SSTable ở các phần sau.
- Bloom Filter: Là một cách cực nhanh để phát hiện sự tồn tại của kiến trúc dữ liệu trong một tập dữ liệu, giúp đánh giá dữ liệu có tồn tại trong một partition hay không. Việc này giúp tiết kiệm được băng thông I/O cho các thao tác đọc/ghi.
Cơ chế ghi dữ liệu
Cassandra thực hiện ghi dữ liệu theo trình tự như sau:
- Lưu các thay đổi gần đây vào bộ nhớ (lưu vào Memtable)
- Khi các thay đổi đủ nhiều, Cassandra thực hiện đẩy các dữ liệu này xuống đĩa cứng (disk). Dữ liệu trên disk được lưu tại các SSTable
- Trước khi ghi một SSTable mới, Cassandra trộn dữ liệu đã được sắp xếp trong Memtable bởi khóa chính (primary key).
- SSTable được ghi xuống đía cứng (disk) dưới dạng một thao tác ghi dữ liệu liên tiếp (ghi tuần tự). Dữ liệu SSTable là bất biến, một khi dữ liệu đã được ghi xuống disk thì sẽ không bị thay đổi. Mọi thay đổi (update/delete) của một dữ liệu trong SSTable sẽ được ghi vào một SSTable mới. Nếu dữ liệu được update thường xuyên thì Cassandra có thể sẽ phải đọc từ nhiều SSTable để lấy được thông tin của một bản ghi.
- Compaction: Là tiến trình nén dữ liệu để giảm bớt dư thừa thông tin. Như bên trên, một bản ghi có thể được update liên tục và do đó sẽ được lưu trên nhiều SSTable sẽ gây tốn dung lượng lưu trữ. Compaction sẽ làm nhiệm vụ ghép các dữ liệu từ nhiều SSTable vào một SSTable mới để giảm dung lượng lưu trữ và tối ưu được thao tác đọc ghi vào dữ liệu
![image.png]()
Cơ chế nén dữ liệu - Compaction Strategies
Compaction là gì
Compaction là cơ chế nén dữ liệu, giúp loại bỏ các dữ liệu dư thừa. Việc ghi dữ liệu vào các SSTable là một thao tác ghi thêm vào các file chứ không update các bản ghi đã có của SSTable (như đã mô tả bên trên SSTable là không chỉnh sửa được). SSTable do đó chưa các dữ liệu mới được thêm gần đây (insert) hay các thay đổi gần đây update/delete) của các dữ liệu đã được thêm vào trước đó. Compaction là tiến trình giúp thống nhất lại các bản copy khác nhau của cùng một dữ liệu giữa các SSTable để giảm số lượng bản ghi cần thiết để lưu trữ dữ liệu đó.
Cơ chế compaction gồm 2 loại
- SizeTiered Compaction Strategy (STCS)
- Leveled Compaction Strategy (LCS)
Các bạn có thể tìm hiểu thêm về các cơ chế này ở đây: https://www.instaclustr.com/blog/apache-cassandra-compaction/#:~:text=Cassandra Compaction is a process,compactions improving its read performance.
Qua bài viết này hy vọng mọi người có những cài nhìn đầu tiên về hệ CSDL Cassandra và các thành phần cũng như cơ chế hoạt động của nó. Trong phần tiếp theo mình sẽ hướng dẫn mọi người dựng một cụm cluster để bắt đầu thực hành các thao tác liên quan tới CSDL này cũng như làm rõ hơn các khái niệm bên trên qua các ví dụ thực tế
All rights reserved
