Cách tạo index và một số truy vấn phổ biến trong Elasticsearch
Bài đăng này đã không được cập nhật trong 6 năm

Index Elasticsearch là gì?
Theo định nghĩa trên ES thì một index Elasticsearch là một tập (collection) các document được liên kết với nhau. ES lưu trữ dữ liệu dưới dạng document JSON. Mỗi document tương ứng với một tập các khóa (key - tên của các trường hoặc thuộc tính) với giá trị tương ứng với chúng (strings, numbers, booleans, dates, giá trị tùy chọn, ...).
Index được định danh bằng tên, tên này sẽ được sử dụng để thực hiện các hoạt động lập chỉ mục, tìm kiếm, cập nhật hoặc xóa các document trong index.
Một số quy tắc khi định danh cho index:
- Chỉ có chữ thường.
- Không chứa các ký tự đặc biệt , /, *,?, ", <,>, | , ` , space, dấu phẩy (,), #
-
- Trước 7.0, tên index có thể chứa dấu hai chấm ( : ),
- Trong 7.0+, không được hỗ trợ.
- Không bắt đầu bằng -, _ , +
- Không là . hoặc ..
- Không dài hơn 255 bytes. Lưu ý là byte, do vậy các ký tự multi-byte sẽ bị tính vào giới hạn 255 nhanh hơn.
Inverted index
ES sử dụng cấu trúc dữ liệu được gọi là reverse index (hay Inverted index) và được thiết kế để có thể thực hiện tìm kiếm full-text một cách nhanh chóng.
Một Inverted index chứa danh sách từng từ đơn duy nhất (unique work) xuất hiện trong bất kỳ một document nào, ứng với mỗi từ đó sẽ là một danh sách các document mà từ này xuất hiện (mapping). Inverted index được tạo ra từ document và được lưu trữ trong Shard, sau đó được dùng cho searching document.
Trong quá trình lập chỉ mục (indexing), ES lưu trữ document và build một reverse index cho phép dữ liệu document có thể được tìm kiếm trong thời gian thực (near real-time). Lập chỉ mục bắt đầu với index API, sau đó có thể thêm hoặc cập nhật một document JSON trong một index cụ thể.
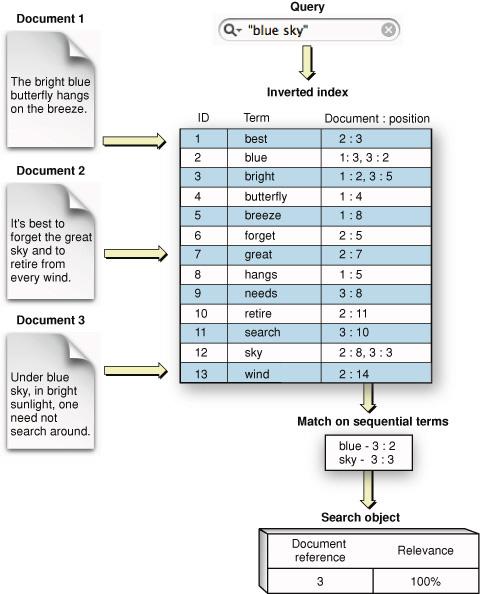
Các bạn có thể tìm hiểu chi tiết hơn về Inverted index trong ES tại Inverted index, Understanding Inverted Index ES.
Tạo index với API
Chúng ta tương tác với ES qua REST APIs với các phương thức HTTP như GET, POST, PUT, DELETE.
Để add thêm một index mới vào cluster, sử dụng API tạo index với phương thức PUT.
PUT /{index_name}
Ngoài ra, có thể chỉ định các mục sau trong Request body:
- Settings: tùy chọn cấu hình cho index.
Ví dụ,
PUT /framgia
{
"settings" : {
"index" : {
"number_of_shards" : 3, # số lượng mặc định Shard
"number_of_replicas" : 2 # số lượng mặc định Replica
}
}
}
ngắn gọn hơn
PUT /framgia
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
- Mappings cho các trường trong index.
Ví dụ,
PUT /framgia
{
"settings" : {
"number_of_shards" : 3
},
"mappings" : {
"properties" : {
"name" : { "type" : "text" }
}
}
}
- Aliases bí danh.
Ví dụ,
PUT /framgia
{
"aliases" : {
"digital" : {},
"sun" : {
"filter" : {
"term" : {"staff" : "thomct" }
},
"routing" : "thomct"
}
}
}
Nhiều hơn về ES REST APIs.
Một số truy vấn phổ biến trong Elasticsearch
Basic Match Query
- Tìm kiếm một keyword trong tất cả các trường.
GET /_search?q={keyword}
- Tìm kiếm trong một trường.
GET /_search?q={field_name}:{keyword}
- Để query trong body của request.
GET /_search
{
"query": {
"multi_match" : {
"query" : {keyword},
"fields" : ["_all"]
}
}
}
Match All Query
Truy vấn đơn giản nhất, match với tất cả các documents, _score 1.0.
GET /_search
{
"query": {
"match_all": {}
}
}
Match None Query
Nghịch đảo của truy vấn match_all, không khớp với document nào.
GET /_search
{
"query": {
"match_none": {}
}
}
Match Phrase Query
Yêu cầu tất cả các term trong query string phải xuất hiện trong document, theo đúng thứ tự tìm kiếm và nằm gần nhau.
Tham số slop dùng để điều chỉnh khoảng cách mặc định giữa các term .
GET /_search
{
"query": {
"multi_match" : {
"query": "23 cau giay",
"fields": ["name", "address"],
"type": "phrase",
"slop": 3
}
},
"_source": [ "name", "address", "author" ]
}
Multi-fields Query
Tìm kiếm truy vấn trong nhiều trường.
GET /_search
{
"query": {
"multi_match" : {
"query" : {keyword},
"fields": [field1, field2, ....]
}
}
}
Boolean Query
Truy vấn match document dựa trên việc kết hợp các kết quả boolean của các truy vấn khác. Truy vấn bool ánh xạ tới Lucene BooleanQuery, sử dụng nhiều mệnh đề như must, should, must_not, filter. Chúng ta có thể hiểu đơn giản,
- must ~ AND
- must_not ~ NOT
- should ~ OR
trong truy vấn cơ sở dữ liệu quan hệ. Ví dụ,
GET /_search
{
"query": {
"bool": {
"must": {
"bool" : { "should": [
{ "match": { field_name: {keyword1} }},
{ "match": { field_name: {keyword2} }} ] }
},
"must": { "match": { field_name: {keyword3} }},
"must_not": { "match": {field_name: {keyword4} }}
...
}
}
}
Boosting Query
Tăng trọng số ở một số trường cụ thể. Ví dụ,
GET /_search
{
"query": {
"multi_match" : {
"query" : {keyword},
"fields": [field1, field2^{weight}, ....]
}
},
"_source": [field1, field2, ....]
}
Fuzzy Query
Trả về kết quả tương tự như tìm kiếm term dựa trên việc sử dụng khoảng cách Levenshtein.
Khoảng cách Levenshtein là số bước thay đổi cần thiết để biến một term (string) này thành một term khác. Những thay đổi này có thể gồm:
- Thay đổi một ký tự.
- Xóa một ký tự.
- Chèn một ký tự.
- Chuyển đổi hai ký tự liền kề.
Để tìm các term tương tự, fuzzy tạo ra một tập hợp tất cả các biến thể hoặc mở rộng có thể của cụm từ cần tìm kiếm trong một khoảng cách được chỉ định. Truy vấn sau đó trả về kết quả khớp chính xác cho mỗi lần mở rộng.
Chúng ta có thể config tham số fuzziness của truy vấn.
- 0, 1, 2: khoảng cách Levenshtein lớn nhất được chấp thuận.
- AUTO: tự động điều chỉnh kết quả dựa trên độ dài của term.
- 0..2: bắt buộc match chính xác, khoảng cách lớn nhất là 0.
- 3..5: khoảng cách lớn nhất là 1.
>5 : khoảng cách lớn nhất là 2.
Ví dụ,
GET /_search
{
"query": {
"fuzzy": {
"staff": {
"value": "thomct",
"fuzziness": "AUTO",
"max_expansions": 50,
"prefix_length": 0,
"transpositions": true,
"rewrite": "constant_score"
}
}
}
}
Exists Query
Trả về các documents có chứa một giá trị được lập chỉ mục cho một trường. Ví dụ,
GET /_search
{
"query": {
"exists": {
"field": "staff"
}
}
}
IDs Query
Sử dụng ID document được lưu trong trường _id.
GET /_search
{
"query": {
"ids" : {
"values" : ["1", "6"]
}
}
}
Wildcard Query
Truy vấn theo pattern, toán tử ký tự đại diện là một placeholder khớp với một hoặc nhiều ký tự.
- Toán tử
*ký tự đại diện khớp với 0 hoặc nhiều ký tự, bao gồm một empty. - Toán tử
?match bất cứ kí tự nào.
Có thể kết hợp các toán tử ký tự đại diện với các ký tự khác để tạo ra một mẫu ký tự đại diện.
GET /_search
{
"query": {
"wildcard": {
"staff": {
"value": "th*m",
"boost": 1.0,
"rewrite": "constant_score"
}
}
}
}
Regexp Query
Truy vấn kết hợp với các biểu thức chính quy (regular expression) để tạo thành các pattern phức tạp hơn so với wildcard query.
Regex là một cách để match các mẫu trong dữ liệu bằng các ký tự placeholder, được gọi là toán tử.
GET /_search
{
"query": {
"regexp": {
"staff": {
"value": "t[a-z]*m.t",
"flags" : "ALL",
"max_determinized_states": 10000,
"rewrite": "constant_score"
}
}
}
}
Tham khảo thêm tại Query DSL.
Đây là một số tìm hiểu của mình khi học Elasticsearch, nó có thể còn một số thiếu sót, mình mong có thể nhận được nhiều góp ý từ bạn đọc 
Thanks all 
All rights reserved
