Cách tải về tất cả các bài viết Viblo bạn đã đăng
Bài đăng này đã không được cập nhật trong 4 năm
Mở bài
Xin chào các bạn, mình đã trở lại với bài đầu tiên sau khi nghỉ việc tại Sun*  Tuần vừa rồi, trong lúc nghiên cứu, mình cần tìm lại tóm tắt paper mình đã viết trên Viblo của mình, nhưng úi dồi ôi 503 nó không cho phép. Thế là mình đã uất ức phải viết luôn code để lần tiếp theo Viblo online có thể kéo được toàn bộ content của mình về xài offline.
Tuần vừa rồi, trong lúc nghiên cứu, mình cần tìm lại tóm tắt paper mình đã viết trên Viblo của mình, nhưng úi dồi ôi 503 nó không cho phép. Thế là mình đã uất ức phải viết luôn code để lần tiếp theo Viblo online có thể kéo được toàn bộ content của mình về xài offline.
Dành cho các bạn lười đọc và chỉ muốn sử dụng thôi:
- Phiên bản working: https://kwkt.ml/viblo
- Static page, host trên GitHub Pages, chỉ cần tải file
htmlvề là có thể tái sử dụng - Không hỗ trợ tải cả ảnh embedded trong file Markdown mà chỉ có source code (do CORS)
- Source là file
viblo.htmltrong GitHub repo ở dưới.
- Static page, host trên GitHub Pages, chỉ cần tải file
- Phiên bản not working: https://viblo-exporter.herokuapp.com
- Cần webserver để tải resource về (bypass CORS)
- Host trên Heroku (duh), có khả năng tải cả Markdown source và các ảnh trong bài để view offline
- Hiện tại không chạy do server Heroku bị CloudFlare anti-DDoS filter chặn
- Source code tại đây: https://github.com/ngoctnq/viblo-exporter
How it works
Đơn giản là mình xài Viblo API thôi Đào ra API của Viblo không khó, bạn chỉ cần monitor traffic lúc vào trang Viblo là được; có thể sử dụng Burp nếu pr0 hoặc F12 ra vào tab Sources nếu bạn dân chơi. Prefix của Viblo API thì bạn có thể dùng https://api.viblo.asia hay https://viblo.asia/api đều ra kết quả giống nhau. Mình không để ý nó khác nhau gì nên cũng không biết đâu. Cụ thể thì API endpoint quan trọng nhất là đây:
https://viblo.asia/api/users/<username>/posts?limit=20
Đây là endpoint mà Viblo website sử dụng để load content của bạn lên khi bạn truy cập vào userpage của một ai đó. Format của API đó như sau:
{
"data":[
{
"title": "Cách tải về tất cả các bài viết Viblo bạn đã đăng",
"slug": "924lJ8qbKPM",
"transliterated": "cach-tai-ve-tat-ca-cac-bai-viet-viblo-ban-da-dang",
"contents": <content>,
...
},
...
],
...
}
Đây là kết quả bạn sẽ có được khi truy cập nội dung bài này. Hiện mình đã cắt bớt những trường mình không sử dụng và chỉ để lại những gì quan trọng thôi:
title: tiêu đề bài viếtslug: UUID, có thể dùng làm key để tìm bài viết, và được nối vào cuối URL mỗi bài để tránh trường hợp một người đặt tên 2 bài giống nhau trùng URLtransliterated: tên bài đã được escape các loại, dùng trong URL để có thể lướt tên bài viết trước khi accesscontents: toàn bộ Markdown source của bài viết.
Thế là xong rồi đúng không Khônggggg, vì nếu bạn không cung cấp ?limit= thì nó sẽ default về 20 bài gần nhất tương ứng với trang đầu tiên thôi, quá khổ. Vì vậy mình đã sử dụng thêm API cho biết thông tin về user và cho biết luôn user đó có bao nhiêu bài viết. API endpoint đó là:
https://viblo.asia/api/users/<username>
Tương tự, sau khi bỏ đa số các trường mình không sử dụng thì format của output của API này là:
{
"data":{
"name":"Ngoc N Tran",
"username":"ngoctnq",
"posts_count":58,
...
},
...
}
Đó, thêm vài thông tin hay ho để frontend hiện cho người dùng đỡ mất kiên nhẫn. Với giá trị posts_count kia, cho nó vào làm query value trong endpoint /posts request, và bạn sẽ có source của toàn bộ tất cả các bài bạn đã đăng. EZ phải không?
Chú ý: Viblo API cho phép bạn đọc các Viblo CTF writeup mà bình thường bạn không được phép truy cập Mình đã báo bug này cho Viblo admin rồi, còn bao giờ nó được fix thì phụ thuộc vào việc bao nhiêu bạn xem được bao nhiêu bài writeup mình đã viết trên profile
Ngoài lề: Thực ra các API cũng cung cấp các thông tin trùng lặp nhiều, ví dụ như API cho posts cũng có bao gồm user information. Tuy nhiên, output của endpoint đó trả về data rất lớn nên mất thời gian và bộ nhớ, còn endpoint cho users content khá ngắn gọn. Ngoài ra còn khá nhiều API khác cho các mục đích khác nhau, bạn có thể tạo hẳn một cái Viblo clone với giao diện đẹp hơn nếu server của bạn có thể truy cập được Viblo API mà không bị Cloudflare chặn
Phiên bản server
Một điều khá vui vẻ là Viblo API có cài đặt CORS là same-origin Thế nên để truy cập vào API thì bạn phải có một server riêng để request.
Phần server nó nhiều code nhưng thực ra lại rất dễ viết, nên bạn có thể tham khảo repo của mình là ok. Cụ thể thì tech stack của project này như sau:
- Flask webserver để serve content và Python
requestsmodule để request API - Sử dụng
threadingđể kéo các file cần thiết về song song, kèm trả về ticket để lúc chuẩn bị xong content người dùng có thể request tải- Ban đầu mình định dùng Celery, nhưng mà học module này + tự config quá khổ, nên là lại thôi
ticket = os.urandom(8).hex() threading.Thread(target=prepDownload, args=(username, posts_count, ticket)).start() return {'ticket': ticket}, 202 - Ban đầu mình định dùng Celery, nhưng mà học module này + tự config quá khổ, nên là lại thôi
- Sử dụng module có sẵn
zipfileđể gói tất cả content đã tải về vào một file cho người dùng- Dùng
BytesIOclass để tạo sau này có thể lấy zip binary trong bộ nhớ và lưu trong database, và dùng functionwritestrđể thêm file vào zip:
memory_file = BytesIO() # do stuff and then save it in the zip file with zipfile.ZipFile(memory_file, 'w') as zf: zf.writestr(<save_directory_in_zip_file>, <binary_content>) # binary content to store into database binary_content = memory_file.read()- Vì một lý do nào đó file tải về không mở được bằng builtin zip handler của Windows, nhưng WinRar hay 7-Zip chơi được tất.
- Dùng
- Dùng regex để tìm các ảnh có trong bài, tải chúng về bằng
requestsmodule, và patch lại Markdown source để trỏ về đúng vị trí của các file ảnh đã lưu- Lưu dictionary của các mapping từ URL ảnh tới offline URL để tránh tải về 1 ảnh được sử dụng 2 lần
- Nếu tải bất thành thì không patch và giữ nguyên URL gốc.
replacements = {} for match in re.finditer(r'!\[[^\]]*\]\(([^\)]+)\)', post['contents']): url = match.group(1) if url in replacements: continue ... try: # get and save image zf.writestr(prefix + '_files/' + fname, requests.get(url, stream=True).raw.data) replacements[url] = fname except: # if unable to fetch image, don't patch image URL pass for k, v in replacements.items(): re.sub( r'!\[([^\]]*)\]\(' + re.escape(k) + r'\)', r'!\[\g<1>\]\(' + re.escape(prefix + '_files/' + v) + r'\)', post['contents'] ) - Sử dụng SQLite để lưu luôn file download mà không cần lưu explicit vào ổ cứng
- Khi người dùng cần thì lấy luôn binary content từ SQLite database ra và serve, thay vì serve file từ ổ cứng.
- Khi người dùng request download file đó, load lại binary content vào RAM để serve người dùng, và xóa luôn entry đó khỏi database cho đỡ tốn dung lượng
- Lưu thời gian ticket được xử lý xong (download content sẵn sàng trong database) và chạy một thread check định kỳ (mỗi 10') chuyên đi expire các download content 1h sau khi available.
- Trước mình sử dụng Redis làm database backend, tuy nhiên Heroku free tier không support sử dụng Redis, và nếu giữ data trong RAM thì chục người request là toang.
- Có khá nhiều code hay ho trong phần xử lý database, mọi người có thể tham khảo ở file
db.pycủa mình.
- SocketIO để truyền progress tải về cho người sử dụng
- Mỗi người dùng được issue một cái download ticket, và ticket đó là tên phòng mà SocketIO sẽ broadcast download progress cho người dùng
- Ban đầu mình không để phần này vào đâu, nhưng mà một bài có nhiều ảnh thì kéo ảnh về khá lâu, nên mình thêm cái này vào cho đỡ mất bình tĩnh
- Chú ý cần monkey patch
eventletnếu bạn sử dụng backend đó cho SocketIO. Author của package này bảo không cần monkey patch nếu sử dụngasyncrunner của họ, nhưng mình không sử dụng được function của họ, nên mình cứ monkey patch rồi sử dụngthreadingmodule; miễn sao code chạy là được.
import eventlet eventlet.monkey_patch() socketio = SocketIO(app, async_mod='eventlet') socketio.send({'current': count, 'total': len(req)}, namespace='/'+ticket)
Và lúc SocketIO báo client file chuẩn bị đã sẵn sàng thì frontend request tải file đó về thôi
Thế nhưng server Heroku của mình bị anti-DDoS chặn Vậy thì biết làm sao bây giờ?
Phiên bản static
Nếu như không cho XHR hay fetch thì chúng ta nhờ người dùng load lên và gửi output content cho mình để xử lý! Nghe đơn giản đúng không? Đơn giản thật, mỗi cái là thiết kế như thế nào cho người dùng có thể theo usage flow một cách dễ dàng thôi: cụ thể, mình sử dụng iframe!
<iframe id="box1" src=""></iframe>
<textarea id="box2"></textarea>
Giờ sau khi người dùng cung cấp username, chúng ta sẽ update iframe src bằng API endpoint tương ứng, và yêu cầu người dùng copy output của iframe đó vô textarea ngay bên cạnh. Tương tự với API posts cũng vậy, chúng ta yêu cầu họ copy 1 lần nữa. Để người dùng đỡ mất kiên nhẫn lúc API load chưa xong (và có thể họ sẽ copy chưa hết output), chúng ta tạo thêm vài visual cues và sử dụng onload event để thông báo cho người dùng lúc nào API iframe load xong hoàn toàn và họ có thể bắt đầu copy.
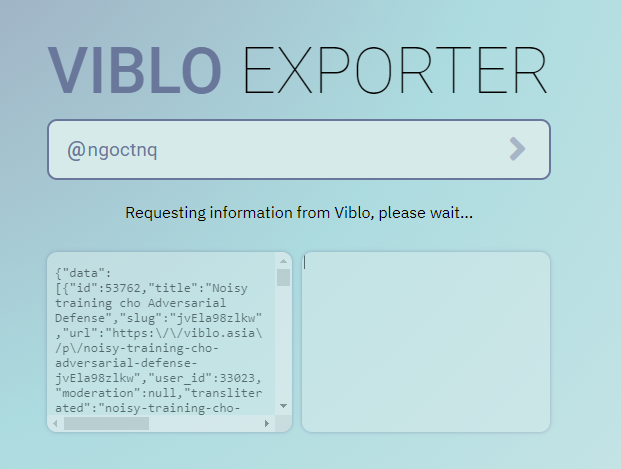
Ngoài ra, do chúng ta cũng không thể tải được ảnh do CORS nên phiên bản này chỉ cần đọc toàn bộ Markdown source trong API call là xong, không phải xử lý lằng nhằng gì hết. Để lưu dữ liệu chúng ta sử dụng thư viện client-zip, siêu bé siêu nhẹ chỉ mấy chục kB. Các bạn có thể sử dụng phiên bản đã compile trên release của họ bằng cú pháp:
<script src="https://github.com/Touffy/client-zip/releases/download/v2.0.0/worker.js"></script>
Nhớ sử dụng bản worker.js chứ không phải index.js nhé, cái kia là module và nếu chúng ta sử dụng thì cái module này sẽ nằm ở namespace khác và không dùng được client-side 
Cách sử dụng module này có trên file README của GitHub repo đó, nhưng để mình tóm tắt lại syntax mình đã sử dụng:
function downloadZip(
[
{
'name': <directory_in_zip_file>
'input': <markdown_content>
}
]
): Response
Cụ thể phần code quan trọng là:
filelist = [];
for ([idx, post] of data.entries()) filelist.push({
name: post.transliterated + '-' + post.slug + '.md',
input: post.contents
});
Và cuối cùng thì mình sử dụng trick tạo <a> tag rồi tự click để download blob mà downloadZip trả về:
downloadZip(filelist).blob().then(blob => {
url = URL.createObjectURL(blob);
let element = document.createElement('a');
element.setAttribute('href', url);
element.setAttribute('download', username + '.zip');
element.style.display = 'none';
document.body.appendChild(element);
element.click();
});
Kết bài
Đến đây là hết rồi! Chúc các bạn tải toàn bộ content của mình về thành công!
Ngoài ra, nếu ai biết cách bypass DDoS prevention của CloudFlare (ví dụ, cho người dùng xác thực thay server) thì hãy liên hệ với mình nhé Hoặc contribute thẳng vào repo trên, xin cảm ơn nhiều và hẹn gặp lại!
Make awesome things that matter.
All rights reserved
