Cách LMAX xử lý 6 triệu giao dịch mỗi giây trên một luồng đơn (Single Thread)
Bài đăng này đã không được cập nhật trong 2 năm
LMAX là một nền tảng giao dịch tài chính bán lẻ. Do đó, nó phải xử lý nhiều giao dịch với độ trễ thấp. Hệ thống được xây dựng trên nền tảng JVM và tập trung vào Bộ xử lý logic kinh doanh (Business Logic Processor) có thể xử lý 6 triệu lệnh mỗi giây trên một luồng đơn. Bộ xử lý Logic kinh doanh chạy hoàn toàn trong bộ nhớ memory bằng cách sử dụng nguồn sự kiện (event sourcing). Bộ xử lý Logic kinh doanh được bao quanh bởi Disruptor - một thành phần đồng thời thực hiện một mạng lưới các hàng đợi hoạt động mà không cần khóa. Trong quá trình thiết kế, nhóm đã kết luận rằng các định hướng gần đây trong các mô hình đồng thời hiệu suất cao sử dụng hàng đợi về cơ bản là mâu thuẫn với thiết kế CPU hiện đại.
Lời mở đầu
Trong vài năm gần đây, chúng ta thường nghe thấy cụm từ "the free lunch is over" - nghĩa là chúng ta không thể mong đợi tốc độ của từng CPU riêng lẻ tăng lên. Do đó, để viết code nhanh, chúng ta cần sử dụng nhiều bộ xử lý cùng với phần mềm đồng thời một cách hiệu quả. Đây không phải là tin tốt - viết code đồng thời rất khó. Khóa và semaphore rất khó để debug và kiểm thử - điều này có nghĩa là chúng ta dành nhiều thời gian hơn để lo lắng về việc giải quyết các vấn đề về máy tính hơn là giải quyết vấn đề theo nghiệp vụ. Các mô hình đồng thời khác nhau, chẳng hạn như Actors và Software Transactional Memory,, nhằm mục đích giúp việc này dễ dàng hơn - nhưng vẫn có gánh nặng dẫn đến lỗi và phức tạp.
Vì vậy, tôi rất thích thú khi nghe về một bài nói chuyện tại QCon London từ LMAX. LMAX là một nền tảng giao dịch tài chính bán lẻ mới. Sự đổi mới trong kinh doanh của họ là một nền tảng bán lẻ cho phép bất kỳ ai giao dịch trong một loạt các sản phẩm phái sinh tài chính. Một nền tảng giao dịch như thế này cần độ trễ rất thấp - các giao dịch phải được xử lý nhanh chóng vì thị trường đang biến động nhanh. Một nền tảng bán lẻ làm tăng thêm tính phức tạp vì nó phải thực hiện điều này cho nhiều người. Vì vậy, kết quả là nhiều người dùng hơn, với nhiều giao dịch, tất cả đều cần được xử lý nhanh chóng.
Xét đến sự chuyển đổi sang suy nghĩ đa lõi, hiệu suất khắt khe kiểu này theo tự nhiên sẽ gợi ý đến một mô hình lập trình đồng thời (concurrency) - và trên thực tế, đây là điểm khởi đầu của họ. Nhưng điều khiến mọi người chú ý tại QCon là họ không dừng lại ở đó. Trên thực tế, họ đã kết thúc bằng cách thực hiện tất cả logic kinh doanh cho nền tảng của mình: tất cả các giao dịch, từ tất cả khách hàng, trên tất cả các thị trường - chỉ trên một luồng. Một luồng sẽ xử lý 6 triệu lệnh mỗi giây bằng phần cứng thông dụng.
Xử lý nhiều giao dịch với độ trễ thấp và không có bất kỳ phức tạp nào của code đồng thời - làm sao tôi có thể cưỡng lại việc đào sâu vào điều đó? May mắn thay, một điểm khác biệt của LMAX so với các công ty tài chính khác là họ khá vui lòng nói về các quyết định công nghệ của mình. Vì vậy, bây giờ LMAX đã đi vào sản xuất một thời gian, đã đến lúc khám phá thiết kế hấp dẫn của họ.
Kiến trúc tổng thể
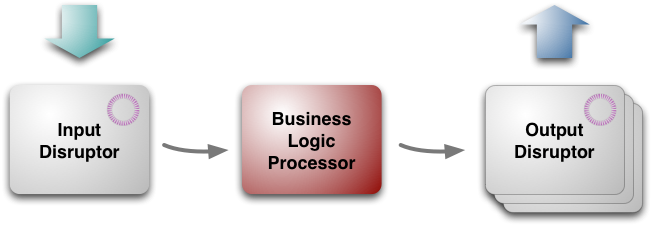
Ở cấp độ cao nhất, kiến trúc này có ba phần:
- Bộ xử lý logic kinh doanh (business logic processor)
- Disruptor đầu vào (input disruptor)
- Disruptor đầu ra (output disruptors)
Như tên gọi của nó, bộ xử lý logic kinh doanh xử lý tất cả logic kinh doanh trong ứng dụng. Như tôi đã đề cập ở trên, nó thực hiện điều này dưới dạng một chương trình Java đơn luồng phản ứng với các cuộc gọi phương thức và tạo ra các sự kiện đầu ra. Do đó, nó là một chương trình Java đơn giản không yêu cầu bất kỳ framework nào để chạy ngoài chính JVM, cho phép nó dễ dàng chạy trong môi trường kiểm thử.
Mặc dù Bộ xử lý Logic nghiệp vụ có thể chạy trong một môi trường đơn giản để kiểm thử, nhưng có nhiều thứ phức tạp hơn để chạy nó trong môi trường sản xuất. Tin nhắn đầu vào cần được lấy ra khỏi cổng mạng và giải mã, sao chép và ghi nhật ký. Tin nhắn đầu ra cần được mã hóa cho mạng. Các tác vụ này được xử lý bởi các disruptor đầu vào và đầu ra. Không giống như Bộ xử lý Logic nghiệp vụ, đây là các thành phần đồng thời, vì chúng liên quan đến các hoạt động IO vừa chậm vừa độc lập. Chúng được thiết kế và xây dựng đặc biệt cho LMAX, nhưng chúng (giống như kiến trúc tổng thể) có thể áp dụng ở những nơi khác.
Business Logic Processor
Keeping it all in memory
Bộ xử lý Logic nghiệp vụ lấy tin nhắn đầu vào tuần tự (dưới dạng gọi phương thức), chạy logic kinh doanh trên chúng và phát ra các sự kiện đầu ra. Nó hoạt động hoàn toàn trong bộ nhớ memory, không có cơ sở dữ liệu hoặc lưu trữ bền vững nào khác. Giữ tất cả dữ liệu trong bộ nhớ mang lại hai lợi ích quan trọng. Thứ nhất là nhanh - không có cơ sở dữ liệu => không cần thực hiện IO chậm chạp để truy cập, cũng không cần có bất kỳ hành vi giao dịch(transaction) nào để thực hiện vì tất cả các xử lý được thực hiện tuần tự. Lợi thế thứ hai là nó đơn giản hóa lập trình - không cần ánh xạ đối tượng/quan hệ. Tất cả code có thể được viết bằng mô hình đối tượng của Java mà không cần phải thực hiện bất kỳ thỏa hiệp nào cho việc ánh xạ sang cơ sở dữ liệu.
Sử dụng cấu trúc trong bộ nhớ có một hậu quả quan trọng - điều gì xảy ra nếu mọi thứ bị sập? Ngay cả những hệ thống kiên cường nhất cũng dễ bị tổn thương bởi việc ai đó rút phích cắm. Trái tim của việc xử lý vấn đề này là Event Sourcing (Nguồn sự kiện) - có nghĩa là trạng thái hiện tại của Bộ xử lý Logic Doanh nghiệp hoàn toàn có thể được suy ra bằng cách xử lý các sự kiện đầu vào. Miễn là luồng sự kiện đầu vào được lưu trữ trong một kho lưu trữ bền vững (đó là một trong những công việc của disruptor đầu vào), bạn luôn có thể tạo lại trạng thái hiện tại của engine logic kinh doanh bằng cách phát lại các sự kiện.
Một cách tốt để hiểu điều này là nghĩ về một hệ thống kiểm soát phiên bản. Hệ thống kiểm soát phiên bản là một chuỗi các commit (gửi lên), bất cứ lúc nào bạn cũng có thể xây dựng một bản sao working copy (bản làm việc) bằng cách áp dụng các commit đó. VCS phức tạp hơn Bộ xử lý Logic Doanh nghiệp vì chúng phải hỗ trợ phân nhánh, trong khi Bộ xử lý Logic Doanh nghiệp là một chuỗi đơn giản.
Vì vậy, về mặt lý thuyết, bạn luôn có thể xây dựng lại trạng thái của Bộ xử lý Logic Doanh nghiệp bằng cách xử lý lại tất cả các sự kiện. Tuy nhiên, trong thực tế, việc này sẽ mất quá nhiều thời gian nếu bạn cần khởi động lại. Vì vậy, giống như với các hệ thống kiểm soát phiên bản, LMAX có thể tạo snapshot (ảnh chụp) của trạng thái Bộ xử lý Logic Doanh nghiệp và khôi phục từ các snapshot. Họ thực hiện snapshot mỗi đêm trong các khoảng thời gian hoạt động thấp. Khởi động lại Bộ xử lý Logic Doanh nghiệp diễn ra nhanh chóng, khởi động lại hoàn toàn - bao gồm khởi động lại JVM, tải snapshot gần đây và phát lại các nhật ký trong một ngày - mất chưa đến một phút.
Snapshot giúp khởi động một Bộ xử lý Logic Doanh nghiệp mới nhanh hơn, nhưng không đủ nhanh nếu Bộ xử lý Logic Doanh nghiệp bị crash vào lúc 2 giờ chiều. Do đó, LMAX luôn duy trì nhiều Bộ xử lý Logic Doanh nghiệp chạy cùng một lúc [6]. Mỗi sự kiện đầu vào được xử lý bởi nhiều bộ xử lý, nhưng tất cả các bộ xử lý (ngoại trừ một bộ xử lý chính) sẽ bị bỏ qua kết quả đầu ra. Nếu bộ xử lý đang hoạt động bị lỗi, hệ thống sẽ chuyển sang bộ xử lý khác. Khả năng xử lý fail-over (thất bại chuyển giao) này là một lợi ích khác của việc sử dụng Event Sourcing.
Bằng cách sử dụng nguồn sự kiện vào các bản sao, họ có thể chuyển đổi giữa các bộ xử lý chỉ trong vài micro giây. Cũng như snapshot mỗi đêm, họ cũng khởi động lại Bộ xử lý Logic Doanh nghiệp mỗi đêm. Bản sao cho phép họ thực hiện việc này mà không bị downtime (thời gian ngừng hoạt động), vì vậy họ có thể tiếp tục xử lý các giao dịch 24/7.
Event Sourcing (Nguồn sự kiện) có giá trị vì nó cho phép bộ xử lý chạy hoàn toàn trong bộ nhớ, nhưng nó còn có một lợi thế đáng kể khác cho việc debug. Nếu một số hành vi bất ngờ xảy ra, nhóm sẽ sao chép chuỗi sự kiện vào môi trường phát triển của họ và phát lại chúng ở đó. Điều này cho phép họ kiểm tra những gì đã xảy ra dễ dàng hơn nhiều so với hầu hết các môi trường.
Khả năng chẩn đoán này mở rộng sang chẩn đoán doanh nghiệp. Có một số nhiệm vụ kinh doanh, chẳng hạn như quản lý rủi ro, yêu cầu tính toán đáng kể mà không cần thiết cho việc xử lý các lệnh. Ví dụ: lấy danh sách 20 khách hàng hàng đầu theo hồ sơ rủi ro dựa trên các vị thế giao dịch hiện tại của họ. Nhóm xử lý việc này bằng cách tạo một mô hình miền sao chép và thực hiện tính toán ở đó, nơi nó sẽ không ảnh hưởng đến việc xử lý đơn hàng cốt lõi. Các mô hình miền phân tích này có thể có các mô hình dữ liệu biến thể, giữ các tập dữ liệu khác nhau trong bộ nhớ và chạy trên các máy khác nhau.
Tuning performance
Cho đến nay, tôi đã giải thích rằng chìa khóa cho tốc độ của Bộ xử lý Logic Doanh nghiệp là thực hiện mọi thứ theo tuần tự, trong bộ nhớ. Chỉ cần thực hiện việc này (và không thực sự ngu ngốc) cho phép các nhà phát triển viết code có thể xử lý 10.000 TPS. Sau đó, họ nhận thấy rằng tập trung vào các yếu tố đơn giản của code tốt có thể đưa con số này lên khoảng 100.000 TPS. Điều này chỉ cần code được xây dựng tốt và các phương thức nhỏ - về bản chất, điều này cho phép Hotspot tối ưu hóa tốt hơn và CPU hoạt động hiệu quả hơn trong việc lưu trữ cache code khi nó đang chạy.
Cần thêm một chút thông minh hơn để tăng thêm một bậc. Có một số điều mà nhóm LMAX thấy hữu ích để đạt được điều đó. Một là viết các triển khai tùy chỉnh của các bộ sưu tập Java được thiết kế để thân thiện với cache và cẩn thận với garbage collection. Ví dụ về điều này là sử dụng các giá trị long nguyên thủy của Java làm khóa hashmap với triển khai Map được hỗ trợ bởi một mảng được viết đặc biệt (LongToObjectHashMap). Nhìn chung, họ thấy rằng việc lựa chọn các cấu trúc dữ liệu thường tạo ra sự khác biệt lớn. Hầu hết các lập trình viên chỉ lấy bất kỳ List nào họ đã sử dụng lần trước thay vì suy nghĩ triển khai nào là phù hợp cho ngữ cảnh này.
Một kỹ thuật khác để đạt được hiệu suất hàng đầu là chú ý đến việc kiểm thử hiệu suất. Tôi đã nhận thấy từ lâu rằng mọi người nói rất nhiều về các kỹ thuật để cải thiện hiệu suất, nhưng điều thực sự tạo nên sự khác biệt là kiểm thử nó. Ngay cả những lập trình viên giỏi cũng rất giỏi trong việc xây dựng các đối số về hiệu suất mà cuối cùng lại sai, vì vậy các lập trình viên giỏi nhất thích sử dụng profiler và các trường hợp kiểm thử hơn là suy đoán. Nhóm LMAX cũng nhận thấy rằng việc viết các bài kiểm thử trước tiên là một kỷ luật rất hiệu quả cho các bài kiểm thử hiệu suất.
Programming Model
Kiểu xử lý này mang lại một số hạn chế nhất định vào cách bạn viết và tổ chức logic kinh doanh. Điều đầu tiên trong số này là bạn phải loại bỏ bất kỳ sự tương tác nào với các dịch vụ bên ngoài. Một cuộc gọi dịch vụ bên ngoài sẽ diễn ra chậm và với một luồng duy nhất sẽ làm gián đoạn toàn bộ máy xử lý đơn hàng. Kết quả là bạn không thể thực hiện các cuộc gọi đến các dịch vụ bên ngoài trong logic kinh doanh. Thay vào đó, bạn cần hoàn thành tương tác đó bằng một sự kiện đầu ra và đợi một sự kiện đầu vào khác để tiếp tục xử lý lại.
Tôi sẽ sử dụng một ví dụ đơn giản không thuộc LMAX để minh họa. Hãy tưởng tượng bạn đang đặt hàng sữa đậu nành bằng thẻ tín dụng. Một hệ thống bán lẻ đơn giản sẽ lấy thông tin đặt hàng của bạn, sử dụng dịch vụ xác thực thẻ tín dụng để kiểm tra số thẻ tín dụng của bạn và sau đó xác nhận đơn hàng của bạn - tất cả đều nằm trong một thao tác duy nhất. Luồng xử lý đơn hàng của bạn sẽ bị chặn trong khi chờ kiểm tra thẻ tín dụng, nhưng sự chặn đó sẽ không quá lâu đối với người dùng và máy chủ luôn có thể chạy một luồng khác trên bộ xử lý trong khi đang chờ đợi.
Trong kiến trúc LMAX, bạn sẽ chia hoạt động này thành hai. Hoạt động đầu tiên sẽ ghi lại thông tin đặt hàng và kết thúc bằng việc xuất ra một sự kiện (yêu cầu xác thực thẻ tín dụng) cho công ty thẻ tín dụng. Bộ xử lý Logic Doanh nghiệp sau đó sẽ tiếp tục xử lý các sự kiện cho các khách hàng khác cho đến khi nó nhận được một sự kiện được xác thực bằng thẻ tín dụng trong luồng sự kiện đầu vào của nó. Khi xử lý sự kiện đó, nó sẽ thực hiện các nhiệm vụ xác nhận cho đơn hàng đó.
Làm việc theo phong cách theo sự kiện, không đồng bộ này có phần khác thường - mặc dù sử dụng tính không đồng bộ để cải thiện khả năng phản hồi của ứng dụng là một kỹ thuật quen thuộc. Nó cũng giúp quy trình kinh doanh linh hoạt hơn, vì bạn phải suy nghĩ rõ ràng hơn về những điều khác nhau có thể xảy ra với ứng dụng.
Một tính năng thứ hai của mô hình lập trình nằm ở việc xử lý lỗi. Mô hình truyền thống của các phiên và giao dịch cơ sở dữ liệu cung cấp khả năng xử lý lỗi hữu ích. Nếu có bất kỳ sự sai sót nào xảy ra, bạn có thể dễ dàng loại bỏ mọi thứ đã xảy ra cho đến thời điểm hiện tại trong tương tác. Dữ liệu phiên là tạm thời và có thể loại bỏ, đổi lại gây ra một số phiền toái cho người dùng nếu đang ở giữa một việc phức tạp. Nếu xảy ra lỗi ở phía cơ sở dữ liệu, bạn có thể khôi phục lại giao dịch.
Các cấu trúc trong bộ nhớ của LMAX vẫn tồn tại giữa các sự kiện đầu vào, vì vậy nếu có lỗi, điều quan trọng là không để bộ nhớ đó ở trạng thái không nhất quán (be in an inconsistent state). Tuy nhiên, không có tiện ích khôi phục tự động nào. Do đó, nhóm LMAX rất chú ý đến việc đảm bảo các sự kiện đầu vào hoàn toàn hợp lệ trước khi thực hiện bất kỳ thay đổi nào đối với trạng thái lưu trữ trong bộ nhớ. Họ nhận thấy rằng kiểm thử là một công cụ then chốt để loại bỏ những vấn đề này trước khi đưa vào sản xuất.
Input and Output Disruptors
Mặc dù logic kinh doanh diễn ra trong một luồng đơn, nhưng có một số nhiệm vụ cần được thực hiện trước khi chúng ta có thể gọi một phương thức của đối tượng kinh doanh. Đầu vào ban đầu để xử lý đến từ mạng dưới dạng tin nhắn, tin nhắn này cần được giải mã thành một dạng thuận tiện để Bộ xử lý Logic Doanh nghiệp sử dụng. Event Sourcing dựa vào việc duy trì một nhật ký bền vững của tất cả các sự kiện đầu vào, vì vậy mỗi tin nhắn đầu vào cần được ghi vào một kho lưu trữ bền vững. Cuối cùng, kiến trúc dựa vào một cụm Bộ xử lý Logic Doanh nghiệp, vì vậy chúng ta phải sao chép các tin nhắn đầu vào trên cụm này. Tương tự ở phía đầu ra, các sự kiện đầu ra cần được mã hóa để truyền qua mạng.
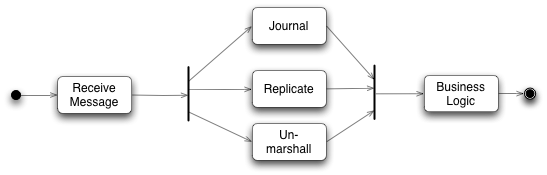
Bản sao lưu (replicator) và nhật ký (journaler) liên quan đến IO và do đó tương đối chậm. Xét cho cùng, ý tưởng cốt lõi của Bộ xử lý Logic Doanh nghiệp là tránh thực hiện bất kỳ IO nào. Ngoài ra, cả ba nhiệm vụ này tương đối độc lập, tất cả đều cần được thực hiện trước khi Bộ xử lý Logic Doanh nghiệp hoạt động trên một tin nhắn, nhưng chúng có thể được thực hiện theo bất kỳ thứ tự nào. Vì vậy, không giống như Bộ xử lý Logic Doanh nghiệp, nơi mỗi giao dịch thay đổi thị trường cho các giao dịch tiếp theo, có một sự phù hợp tự nhiên cho tính đồng thời.
Để xử lý tính đồng thời này, nhóm LMAX đã phát triển một thành phần đồng thời đặc biệt, mà họ gọi là Disruptor. Nhóm LMAX đã phát hành mã nguồn cho Disruptor với giấy phép mã nguồn mở.
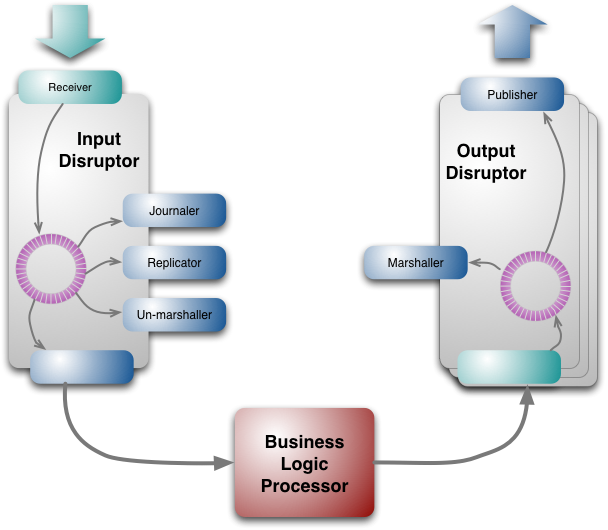
Ở cấp độ thô sơ, bạn có thể coi Disruptor như một biểu đồ đa hướng của các hàng đợi, nơi các nhà sản xuất đặt các đối tượng lên đó được gửi đến tất cả người tiêu dùng để tiêu thụ song song thông qua các hàng đợi riêng biệt phía hạ lưu. Khi bạn nhìn vào bên trong, bạn sẽ thấy rằng mạng lưới các hàng đợi này thực sự là một cấu trúc dữ liệu duy nhất - một vùng đệm hình vành khuyên (ring buffer). Mỗi nhà sản xuất và người tiêu dùng đều có một bộ đếm chuỗi để chỉ ra vị trí trong vùng đệm mà nó hiện đang hoạt động. Mỗi nhà sản xuất/người tiêu dùng ghi bộ đếm chuỗi của riêng mình nhưng có thể đọc bộ đếm chuỗi của những người khác. Bằng cách này, nhà sản xuất có thể đọc các bộ đếm của người tiêu dùng để đảm bảo vị trí nó muốn ghi vào có sẵn mà không cần bất kỳ khóa nào trên các bộ đếm. Tương tự, người tiêu dùng có thể đảm bảo chỉ xử lý các tin nhắn một lần sau khi người tiêu dùng khác hoàn thành việc đó bằng cách theo dõi các bộ đếm.
Disruptor đầu ra tương tự nhưng chỉ có hai người tiêu dùng tuần tự để mã hóa và xuất ra [12]. Các sự kiện đầu ra được tổ chức thành nhiều topic, để tin nhắn chỉ có thể được gửi đến những người nhận quan tâm đến chúng. Mỗi topic có một disruptor riêng.
Các disruptor tôi đã mô tả được sử dụng theo phong cách với một nhà sản xuất và nhiều người tiêu dùng, nhưng đây không phải là hạn chế của thiết kế disruptor. Disruptor cũng có thể hoạt động với nhiều nhà sản xuất, trong trường hợp này nó vẫn không cần khóa [13].
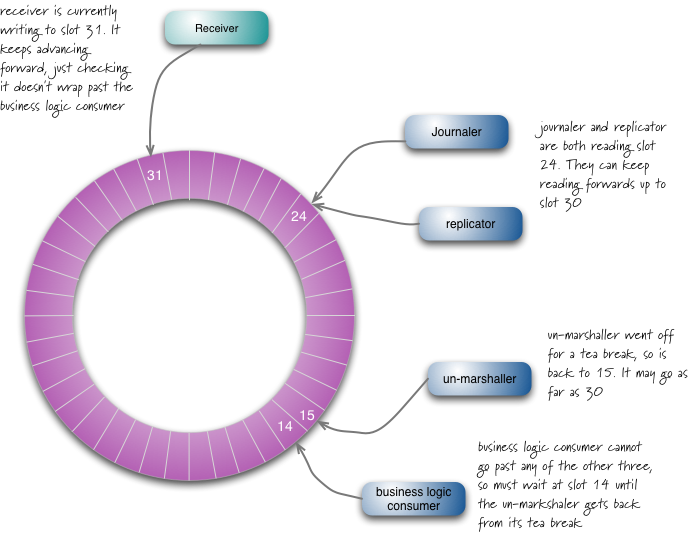
Một lợi ích của thiết kế disruptor là nó giúp người tiêu dùng dễ dàng bắt kịp nhanh chóng nếu họ gặp vấn đề và bị tụt hậu. Nếu bộ gỡ mã hóa gặp vấn đề khi xử lý trên slot 15 và trả về khi bộ thu nhận đang ở slot 31, nó có thể đọc dữ liệu từ các slot 16-30 trong một batch để bắt kịp. Việc đọc dữ liệu theo batch này từ disruptor giúp người tiêu dùng chậm trễ bắt kịp nhanh hơn, do đó giảm độ trễ tổng thể.
Tôi đã mô tả mọi thứ ở đây, với một cho mỗi journaler, replicator và unmarshaler - đây thực sự là những gì LMAX làm. Nhưng thiết kế cho phép chạy nhiều thành phần này. Nếu bạn chạy hai journaler thì một cái sẽ lấy các slot chẵn và journaler khác sẽ lấy các slot lẻ. Điều này cho phép đồng thời hơn nữa các hoạt động IO này nếu cần thiết.
Vùng đệm hình vành khuyên (ring buffer) có kích thước lớn: 20 triệu slot cho vùng đệm đầu vào và 4 triệu slot cho mỗi vùng đệm đầu ra. Bộ đếm chuỗi là các số nguyên 64 bit tăng đơn điệu ngay cả khi các slot vòng lặp lại. Vùng đệm được đặt thành kích thước là lũy thừa của hai để trình biên dịch có thể thực hiện phép toán modulo hiệu quả để ánh xạ từ số bộ đếm chuỗi sang số slot. Giống như phần còn lại của hệ thống, các disruptor được khởi động lại qua đêm. Việc khởi động lại này chủ yếu được thực hiện để xóa sạch bộ nhớ để giảm thiểu khả năng xảy ra sự kiện thu gom rác tốn kém trong quá trình giao dịch. (Tôi cũng nghĩ đây là một thói quen tốt để khởi động lại thường xuyên, để bạn diễn tập cách thực hiện trong trường hợp khẩn cấp.)
Công việc của journaler là lưu trữ tất cả các sự kiện ở dạng bền vững, để chúng có thể được phát lại nếu có bất kỳ sự sai sót nào xảy ra. LMAX không sử dụng cơ sở dữ liệu cho việc này, chỉ sử dụng hệ thống file. Họ truyền các sự kiện vào đĩa. Theo thuật ngữ hiện đại, các đĩa cơ học cực kỳ chậm đối với truy cập ngẫu nhiên, nhưng rất nhanh đối với truyền phát - do đó có khẩu hiệu "disk is the new tape".
Trước đó tôi đã đề cập rằng LMAX chạy nhiều bản sao của hệ thống của họ trong một cụm để hỗ trợ chuyển đổi dự phòng nhanh chóng. Bộ nhân bản giúp các nút này đồng bộ. Tất cả giao tiếp trong LMAX sử dụng IP đa hướng (multicasting), vì vậy client không cần biết địa chỉ IP nào là nút leader. Chỉ có nút leader mới trực tiếp lắng nghe các sự kiện đầu vào và chạy một bộ nhân bản. Bộ nhân bản phát đa hướng các sự kiện đầu vào tới các nút theo dõi (follower node). Nếu nút leader bị sập, nhịp tim của nó không được nhận thấy, một nút khác trở thành leader, bắt đầu xử lý các sự kiện đầu vào và bắt đầu bộ nhân bản của nó. Mỗi nút có disruptor đầu vào riêng và do đó có nhật ký riêng và thực hiện việc giải mã riêng.
Ngay cả với IP đa hướng, việc sao chép vẫn cần thiết vì các tin nhắn IP có thể đến theo thứ tự khác nhau trên các nút khác nhau. Nút leader cung cấp một trình tự xác định cho phần còn lại của quá trình xử lý.
Bộ gỡ mã hóa chuyển đổi dữ liệu sự kiện từ trên mạng thành một đối tượng Java có thể được sử dụng để kích hoạt hành vi trên Bộ xử lý Logic Doanh nghiệp. Do đó, không giống như những người tiêu dùng khác, nó cần sửa đổi dữ liệu trong vùng đệm hình vành khuyên để có thể lưu trữ đối tượng được giải mã này. Quy tắc ở đây là người tiêu dùng được phép ghi vào vùng đệm hình vành khuyên, nhưng mỗi trường có thể ghi chỉ có một người tiêu dùng song song được phép ghi vào đó. Điều này bảo vệ nguyên tắc chỉ có một writer duy nhất.
Disruptor là một thành phần đa năng có thể được sử dụng bên ngoài hệ thống LMAX. Thông thường các công ty tài chính rất kín tiếng về hệ thống của họ, giữ im lặng ngay cả những thứ không liên quan đến hoạt động kinh doanh của họ. LMAX không chỉ cởi mở về kiến trúc tổng thể của mình mà còn cung cấp mã nguồn mở của disruptor - một hành động khiến tôi rất vui. Điều này không chỉ cho phép các tổ chức khác sử dụng disruptor mà còn cho phép kiểm tra nhiều hơn các thuộc tính đồng thời của nó.
Hàng đợi và sự thiếu đồng cảm máy học
Kiến trúc LMAX thu hút sự chú ý của mọi người bởi vì nó là một cách tiếp cận rất khác biệt đối với một hệ thống hiệu suất cao so với những gì hầu hết mọi người đang nghĩ đến. Cho đến nay tôi đã nói về cách thức hoạt động của nó, nhưng chưa đi sâu quá nhiều vào lý do tại sao nó được phát triển theo cách này. Câu chuyện này thú vị, bởi vì kiến trúc này không chỉ đơn giản là xuất hiện. Phải mất một thời gian dài để thử các lựa chọn thay thế thông thường hơn và nhận ra những điểm yếu của chúng trước khi nhóm nghiên cứu quyết định sử dụng giải pháp này.
Hầu hết các hệ thống kinh doanh hiện nay đều có kiến trúc cốt lõi dựa trên nhiều phiên hoạt động được phối hợp thông qua một cơ sở dữ liệu giao dịch. Nhóm LMAX đã quen thuộc với cách tiếp cận này và tin chắc rằng nó sẽ không hiệu quả cho LMAX. Đánh giá này được thành lập dựa trên kinh nghiệm của Betfair - công ty mẹ thành lập LMAX. Betfair là một trang web cá cược cho phép mọi người đặt cược vào các sự kiện thể thao. Nó xử lý khối lượng truy cập rất cao với rất nhiều tranh chấp - cá cược thể thao có xu hướng bùng nổ xung quanh các sự kiện cụ thể. Để làm cho việc này hoạt động, họ có một trong những cài đặt cơ sở dữ liệu hot nhất và phải thực hiện nhiều hành động không tự nhiên để làm cho nó hoạt động. Dựa trên kinh nghiệm này, họ biết việc duy trì hiệu suất của Betfair khó khăn như thế nào và chắc chắn rằng loại kiến trúc này sẽ không phù hợp với độ trễ rất thấp mà một trang web giao dịch yêu cầu. Kết quả là họ phải tìm một cách tiếp cận khác.
Cách tiếp cận ban đầu của họ là tuân theo những gì mà nhiều người đang nói trong những ngày này - rằng để có hiệu suất cao, bạn cần sử dụng concurrency. Đối với tình huống này, điều này có nghĩa là cho phép các lệnh được xử lý bởi nhiều luồng song song. Tuy nhiên, như thường xảy ra với tính đồng thời, khó khăn đến vì các luồng này phải giao tiếp với nhau. Xử lý một lệnh sẽ thay đổi điều kiện thị trường và những điều kiện này cần được truyền đạt lại.
Cách tiếp cận mà họ khám phá ngay từ đầu là mô hình Actor và người anh em họ SEDA của nó. Mô hình Actor dựa trên các đối tượng hoạt động độc lập, có luồng riêng của chúng giao tiếp với nhau thông qua các hàng đợi. Nhiều người thấy mô hình đồng thời loại này dễ xử lý hơn nhiều so với việc cố gắng làm điều gì đó dựa trên các khóa nguyên thủy.
Nhóm đã xây dựng một sàn giao dịch nguyên mẫu sử dụng mô hình actor và thực hiện các bài kiểm tra hiệu suất trên nó. Những gì họ phát hiện ra là bộ xử lý dành nhiều thời gian hơn để quản lý các hàng đợi hơn là thực hiện logic thực tế của ứng dụng. Truy cập hàng đợi là một nút thắt cổ chai.
Khi đẩy hiệu suất như thế này, việc tính đến cách phần cứng hiện đại được xây dựng bắt đầu trở nên quan trọng. Cụm từ mà Martin Thompson thích sử dụng là "sự đồng cảm cơ học". Thuật ngữ này xuất phát từ môn đua xe và nó phản ánh việc người lái xe có cảm giác bẩm sinh đối với chiếc xe, vì vậy họ có thể cảm nhận được cách để khai thác tốt nhất từ nó. Nhiều lập trình viên, và tôi thú nhận rằng tôi thuộc nhóm này, không có nhiều thiện cảm về mặt cơ học đối với cách lập trình tương tác với phần cứng. Điều tồi tệ hơn là nhiều lập trình viên nghĩ rằng họ có sự đồng cảm về mặt cơ học, nhưng nó được xây dựng trên những khái niệm về cách phần cứng hoạt động ngày nay đã lỗi thời nhiều năm.
Một trong những yếu tố chi phối của CPU hiện đại ảnh hưởng đến độ trễ là cách CPU tương tác với bộ nhớ. Ngày nay, việc truy cập vào bộ nhớ chính là một hoạt động rất chậm theo thuật ngữ CPU. CPU có nhiều cấp độ cache, mỗi cấp độ đều nhanh hơn đáng kể. Vì vậy, để tăng tốc độ, bạn muốn đưa mã và dữ liệu của mình vào các cache đó.
Ở một cấp độ nào đó, mô hình actor hữu ích ở đây. Bạn có thể coi một actor là đối tượng riêng của nó, nhóm mã và dữ liệu, đây là một đơn vị tự nhiên để lưu trữ. Nhưng các actor cần phải giao tiếp, chúng thực hiện điều này thông qua các hàng đợi - và nhóm LMAX nhận thấy rằng chính các hàng đợi là thứ cản trở việc lưu trữ dữ liệu vào bộ nhớ đệm.
Giải thích diễn ra như sau: để đưa một số dữ liệu vào hàng đợi, bạn cần phải ghi vào hàng đợi đó. Tương tự, để lấy dữ liệu ra khỏi hàng đợi, bạn cần phải ghi vào hàng đợi để thực hiện việc xóa. Đây là tranh chấp ghi - nhiều client hơn một có thể cần ghi vào cùng một cấu trúc dữ liệu. Để giải quyết tranh chấp ghi, hàng đợi thường sử dụng khóa. Nhưng nếu sử dụng khóa, điều đó có thể gây ra chuyển đổi ngữ cảnh sang nhân. Khi điều này xảy ra, bộ xử lý liên quan có khả năng mất dữ liệu trong các cache của nó.
Kết luận mà họ đưa ra là để có được hành vi lưu trữ cache tốt nhất, bạn cần một thiết kế chỉ có một core ghi vào bất kỳ vị trí nhớ nào [17]. Nhiều reader không sao, bộ xử lý thường sử dụng các liên kết tốc độ cao đặc biệt giữa các cache của chúng. Nhưng các hàng đợi không đáp ứng được nguyên tắc single-writer (chỉ một người ghi).
Phân tích này dẫn dắt nhóm LMAX đến một vài kết luận. Thứ nhất, nó dẫn đến thiết kế của disruptor, tuân theo một cách kiên định ràng buộc single-writer. Thứ hai, nó dẫn đến ý tưởng khám phá cách tiếp cận logic kinh doanh single-threaded (chỉ một luồng), đặt ra câu hỏi một luồng đơn có thể chạy nhanh như thế nào nếu nó được giải phóng khỏi việc quản lý đồng thời.
Bản chất của việc làm việc trên một luồng đơn là đảm bảo bạn có một luồng chạy trên một core, các cache nóng lên và truy cập bộ nhớ càng nhiều càng tốt vào các cache thay vì vào bộ nhớ chính. Điều này có nghĩa là cả mã và bộ dữ liệu làm việc cần được truy cập một cách nhất quán nhất có thể. Ngoài ra, giữ các đối tượng nhỏ với mã và dữ liệu cùng nhau cho phép chúng được hoán đổi giữa các cache như một đơn vị, đơn giản hóa việc quản lý cache và một lần nữa cải thiện hiệu suất.
Một phần thiết yếu trên con đường dẫn đến kiến trúc LMAX là việc sử dụng các bài kiểm tra hiệu suất. Việc xem xét và từ bỏ cách tiếp cận dựa trên actor xuất phát từ việc xây dựng và kiểm tra hiệu suất của một nguyên mẫu. Tương tự, nhiều bước cải thiện hiệu suất của các thành phần khác nhau được kích hoạt bởi các bài kiểm tra hiệu suất. Sự đồng cảm cơ học rất có giá trị - nó giúp hình thành các giả thuyết về những cải tiến bạn có thể thực hiện và hướng dẫn bạn tiến về phía trước chứ không phải thụt lùi - nhưng cuối cùng, chính việc kiểm tra mới cung cấp cho bạn bằng chứng thuyết phục.
Tuy nhiên, kiểm tra hiệu suất theo phong cách này không phải là một chủ đề được hiểu rõ. Đội ngũ LMAX thường xuyên nhấn mạnh rằng việc đưa ra các bài kiểm tra hiệu suất có ý nghĩa thường khó hơn phát triển mã sản xuất. Một lần nữa, sự đồng cảm cơ học rất quan trọng để phát triển các bài kiểm tra phù hợp. Kiểm tra một thành phần đồng thời cấp thấp là vô nghĩa trừ khi bạn tính đến hành vi lưu trữ cache của CPU.
Một bài học cụ thể là tầm quan trọng của việc viết các bài kiểm tra đối với các thành phần để đảm bảo bài kiểm tra hiệu suất đủ nhanh để thực sự đo lường những gì các thành phần thực tế đang làm. Viết mã kiểm tra nhanh không dễ hơn viết mã sản xuất nhanh và việc nhận được kết quả sai là quá dễ dàng vì bài kiểm tra không nhanh bằng thành phần mà nó đang cố gắng đo lường.
Khi nào nên sử dụng kiến trúc này
Nhìn thoáng qua, kiến trúc này có vẻ dành cho một phân khúc rất nhỏ. Rốt cuộc, trình điều khiển dẫn đến nó là để có thể chạy nhiều giao dịch phức tạp với độ trễ rất thấp - hầu hết các ứng dụng không cần chạy ở mức 6 triệu TPS (giao dịch mỗi giây).
Nhưng điều khiến tôi say mê về ứng dụng này là họ đã đưa ra được một thiết kế loại bỏ phần lớn sự phức tạp về lập trình gây ra nhiều rắc rối cho các dự án phần mềm. Mô hình truyền thống của các phiên đồng thời xung quanh một cơ sở dữ liệu giao dịch không phải là không có rắc rối. Thông thường, mối quan hệ với cơ sở dữ liệu đòi hỏi nỗ lực không nhỏ. Các công cụ ánh xạ quan hệ đối tượng có thể giúp ích rất nhiều cho việc xử lý cơ sở dữ liệu, nhưng nó không giải quyết được tất cả. Hầu hết việc điều chỉnh hiệu suất của các ứng dụng doanh nghiệp liên quan đến việc chỉnh sửa SQL.
Ngày nay, bạn có thể đưa nhiều bộ nhớ chính hơn vào máy chủ của mình có thể nhận được dung lượng đĩa. Ngày càng nhiều ứng dụng có khả năng đặt toàn bộ tập làm việc của chúng vào bộ nhớ chính - do đó loại bỏ nguồn gốc của cả sự phức tạp và chậm chạp. Event Sourcing cung cấp một cách để giải quyết vấn đề độ bền cho hệ thống trong bộ nhớ, chạy mọi thứ trong một luồng đơn giải quyết vấn đề đồng thời. Trải nghiệm của LMAX cho thấy rằng miễn là bạn cần ít hơn vài triệu TPS, bạn sẽ có đủ khoảng trống về hiệu suất.
Có một sự trùng lặp đáng kể ở đây với sự quan tâm ngày càng tăng đối với CQRS (Command Query Responsibility Segregation - Phân tách trách nhiệm truy vấn lệnh). Bộ xử lý trong bộ nhớ, được cung cấp nguồn sự kiện là một lựa chọn tự nhiên cho phía lệnh của hệ thống CQRS. (Mặc dù nhóm LMAX hiện không sử dụng CQRS.)
Vậy điều gì cho thấy bạn không nên đi theo con đường này? Đây luôn là một câu hỏi khó đối với các kỹ thuật ít được biết đến như thế này, vì ngành nghề cần thêm thời gian để khám phá các ranh giới của nó. Tuy nhiên, một điểm bắt đầu là suy nghĩ về các đặc điểm khuyến khích kiến trúc.
Một đặc điểm là đây là một miền được kết nối, trong đó việc xử lý một giao dịch luôn có khả năng thay đổi cách xử lý các giao dịch tiếp theo. Với các giao dịch độc lập hơn với nhau, nhu cầu phối hợp ít hơn, do đó việc sử dụng các bộ xử lý riêng biệt chạy song song trở nên hấp dẫn hơn.
LMAX tập trung vào việc tìm ra những kết quả của việc các sự kiện thay đổi thế giới như thế nào. Nhiều trang web tập trung hơn vào việc lấy một kho thông tin hiện có và hiển thị các tổ hợp khác nhau của thông tin đó cho càng nhiều người dùng càng tốt - ví dụ như bất kỳ trang media nào. Ở đây, thách thức về kiến trúc thường tập trung vào việc thiết lập bộ nhớ cache của bạn một cách chính xác.
Một đặc điểm khác của LMAX là đây là một hệ thống back-end, vì vậy cần cân nhắc xem nó có thể áp dụng như thế nào cho thứ gì đó hoạt động ở chế độ tương tác. Ngày càng có nhiều ứng dụng web giúp chúng tôi quen với các hệ thống máy chủ phản hồi theo yêu cầu, một khía cạnh phù hợp với kiến trúc này. Kiến trúc này đi xa hơn hầu hết các hệ thống đó là việc sử dụng tuyệt đối giao tiếp không đồng bộ, dẫn đến những thay đổi đối với mô hình lập trình mà tôi đã trình bày trước đó.
Những thay đổi này sẽ cần một số nhóm để làm quen. Hầu hết mọi người có xu hướng nghĩ về lập trình theo thuật ngữ đồng bộ và không quen xử lý bất đồng bộ. Tuy nhiên, từ lâu, giao tiếp không đồng bộ đã trở thành một công cụ thiết yếu để phản hồi. Sẽ rất thú vị để xem liệu việc sử dụng rộng rãi hơn giao tiếp không đồng bộ trong thế giới javascript, với AJAX và node.js, có khuyến khích nhiều người hơn tìm hiểu phong cách này không. Nhóm LMAX nhận thấy rằng mặc dù mất một chút thời gian để điều chỉnh theo phong cách không đồng bộ, nhưng nó nhanh chóng trở nên tự nhiên và thường dễ dàng hơn. Cụ thể, việc xử lý lỗi dễ dàng hơn nhiều theo cách tiếp cận này.
Nhóm LMAX chắc chắn cảm thấy rằng những ngày của cơ sở dữ liệu giao dịch sắp được đánh số. Thực tế là bạn có thể viết phần mềm dễ dàng hơn bằng cách sử dụng kiến trúc này và nó chạy nhanh hơn loại bỏ phần lớn sự biện minh cho cơ sở dữ liệu trung tâm truyền thống.
All rights reserved
