Cách hoạt động của Unicorn
Bài đăng này đã không được cập nhật trong 8 năm
Sau tìm hiểu và đọc bài viết trong blog của GitHub nói về Unicorn, nay mình viết lại để ghi nhớ cũng như giới thiệu cho mọi người về cách hoạt động của Unicorn.
Unicorn là gì?
Unicorn là một máy chủ HTTP cho Ruby, tương tự như Mongrel hoặc Thin. Nó sử dụng bộ phân tích cú pháp Ragel HTTP của Mongrel nhưng có một kiến trúc rất khác.
Trong thiết lập thông thường, bạn có nginx gửi request đến một pool của mongrels sử dụng cân bằng tải (load balancer ). Bạn muốn hiển thị và độ tin cậy tốt hơn trong tình huống cân bằng tải, vì vậy bạn hãy đưa haproxy đến tập hợp mongrels. Hình minh họa bên dưới.
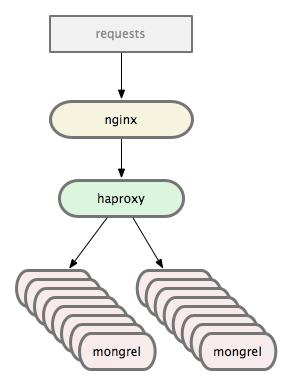
Load balancing
Cái hay đầu tiên là việc cân bằng tải. Về cơ bản việc cân bằng tải của Unicorn được đảm nhiệm bởi OS Kernel, và việc quản lý các process được thực hiện bằng cách gửi signal.
Khi khởi chạy, Unicorn master được sinh ra và load ứng dụng vào bộ nhớ và bắt đầu fork ra các worker phục vụ cho việc xử lý request.
Việc cân bằng tải các worker process như đã nói bên trên, được quyết định bởi OS Kernel, khi các worker process đang rảnh, chúng tập trung hóng Unix socket đã được tạo từ trước, và tranh nhau để nhận request, tất nhiên OS Kernel sẽ quyết định trao request cho worker nào. Tóm lại là thay vì bị động bị đẩy request, các worker luôn có xu hướng xin request để làm việc một khi nó đã sẵn sàng.
Lưu ý nhỏ : Unicorn master sẽ quản lý vòng đời của worker trong khi OS Kernel sẽ quản lý việc cân bằng tải. Và tất nhiên, thằng Unicorn master sẽ không tương tác với bất cứ request nào.
Xử lý worker chậm chạp
Unicorn master biết chính xác thời gian worker xử lý request. Dựa vào config thời gian timeout, Unicorn master sẽ ngay lập tức kill worker đó và fork ra worker mới, việc fork ra worker diễn ra cực nhanh, nên sẽ không có mất mát khi trong thời gian kill worker và fork ra worker mới. Khi worker bị kill, client sẽ nhận được lỗi 502.
Xử lý worker tiêu tốn bộ nhớ
Việc worker tồn lại lâu lượng bộ nhớ tăng lên theo thời gian là không tránh khỏi, chưa nói tới việc xử lý ở code, ta vẫn có thể xử lý chúng bằng cách thịt worker đó và sinh ra cái mới. Tất nhiên việc này ta không nên kill worker đó như bên trên, vì nó vẫn chạy bình thường, chẳng qua là lượng bộ nhớ đang chiếm giữ tăng cao thôi. Thay vì đó ta sẽ gửi QUIT signal tới worker process đó, nôm na là bảo worker đó xử lý nốt request đang dang dở đi ( nếu nó đang xử lý request ) và sau đó là sẽ chết. Như vậy sẽ đảm bảo được request đang xử lý không bị gián đoạn.
Restart Unicorn master
Việc này khá là thường xuyên, điển hình khi bạn deploy code mới.
- Đầu tiên sẽ gửi USR2 signal tới Unicorn master hiện tại, để báo nó sinh ra một Unicorn master mới, và tất nhiên thằng Unicorn master mới này sẽ load code mới nhất của bạn.
- Ngay khi Unicorn master mới được khởi tạo và đã load xong code, nó sẽ bắt đầu sinh ra các worker. Tới đây bạn có thể hình dung cấu trúc của chúng như sau unicorn master (old) _ unicorn worker[0] _ unicorn worker[1] _ unicorn worker[2] _ unicorn worker[3] _ unicorn master _ unicorn worker[0] _ unicorn worker[1] _ unicorn worker[2] _ unicorn worker[3]
- Ngay từ các worker đầu tiên được sinh ra, nó nhận thấy đang có thằng Unicorn master cũ đang hoạt động, nó sẽ gửi QUIT signal tới thằng đó.
- Unicorn master cũ nhận được QUIT signal, nó sẽ bắt đầu quá trình tắt các worker của nó, khi tất cả các worker của nó hoàn tất việc xử lý request đang dang dở, chúng sẽ chết.
- Tới đây thì chỉ có Unicorn master mới và worker của nó với code mới nhất của bạn hoạt động.
Với flow hoạt động như vậy, sẽ không có downtime hệ thống của bạn trong quá trình deploy. Và vì worker cũ lẫn mới đểu dùng chung một Unix Domain Socket nên Web server ( ví dụ Nginx ) không cần quan tâm tới quá trình chuyển đổi khi deploy này.
Tham khảo
All rights reserved
