Các thông số trong file config của postgresSQL cần lưu ý
Bài đăng này đã không được cập nhật trong 2 năm
Sau khi đã tìm hiều qua về các kiểu dữ liệu trong postgresSQL, hôm nay mình sẽ giới thiệu cho các bạn các thông số cơ bản trong file config của postgresSQL và một số lưu ý nhé Các bạn nên xem qua bài này để hiểu hơn về cơ sở dữ liệu này nhé.
Sau khi các bạn đã cài đặt thành công postgresSQL với docker (mình có hướng dẫn ở bài trước, bạn nào chưa đọc có thể quay lại để cài đặt nhé https://viblo.asia/p/cai-dat-he-quan-tri-co-so-du-lieu-postgressql-y37LdAX2Vov) chúng ta sẽ có folder data cùng cấp với docker-compose.yml mà đã được mount từ container ra ngoài.
Ở đây chúng ta sẽ chú ý đến file postgresql.conf, đây là file còn chứa config chính của postgresSQL, chúng ta sẽ mò xem trong này có gì nhé.
1. listen_addresses
Thông số đầu tiên các bạn cần chú ý đó là listen_addresses thông số này sẽ quyết định những ai có thể connect tới database này.

Khi các bạn mới cài đặt xong, giá trị mặc định của nó sẽ là localhost có nghĩa chỉ có máy được cài mới có thể kết nối tới nó, để public ra ngoài các bạn có thể sửa giá trị localhost thành * hoặc list các ip mà các bạn muốn.
2. port
Đây là thông số cổng mà PostgreSQL sẽ lắng nghe các kết nối. Với giá trị mặc định là 5432 , mình khuyên các bạn nên đổi sang giá trị khác để tăng tính bảo mật các bạn nhé.
![]()
3. max_connections
Thông số này có nghĩa là chúng ta sẽ xét cho database có thể kết nối đồng thời tới với số lượng bao nhiêu, giá trị mặc định ở đây là 100, tùy vào mục đích sử dụng mà các bạn sẽ để giá trị phù hợp nhé

4. shared_buffers
Với config này chắc hẳn các bạn đã sử dụng qua nhưng không quan tâm đến nó lắm, mình sẽ giải thích về tầm quan trọng của nó nhé

Vậy với thông số này thì nó có ý nghĩa gì ? Giá trị của thông số này sẽ quyết định postgresSQL sẽ được sử dụng bao nhiêu ram để lưu trữ dữ liệu và xử lý
Để hiểu rõ hơn phần này, mình sẽ giải thích một chút về workflow của postgresSQL sử dụng ram và ổ cứng như thế nào với hình sau
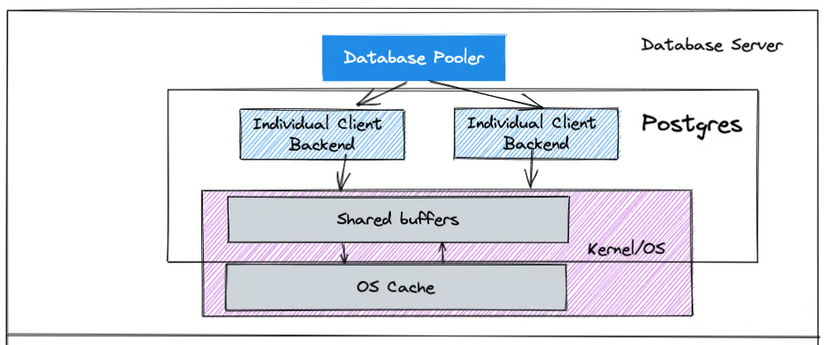
Như hình chúng ta thấy khi có 1 câu query read dữ liệu, dữ liệu sẽ được lấy từ disk cache, lôi lên ram(shared buffer) và xử lý.
Vậy để tăng hiệu suất xử lý dữ liệu và giảm số lượng I/O (Input/Output) đọc và ghi và đĩa, chúng ta sẽ tăng giá trị của thông số shared_buffers này lên, từ đó postgresSQL có thể sử dụng nhiều hơn.
Để sử dụng hiệu quả, tránh xung đột về việc sử dụng ram của các ứng dụng trên máy, chúng ta nên thử nghiệm và cho nó 1 thông số tốt nhất để đạt hiểu quả cao nhé.
5. wal_level
Tiếp theo đó là wal_level

Thông số này có 3 giá trị mặc định: minimal, replica, logical
Với các giá trị trên nó sẽ quyết định mức độ chi tiết của thông tin ghi vào logs (Write-Ahead Logging - WAL)
Minimal: Với giá trị này, nó là giá trị tối thiểu, khi cài đặt nó sẽ chỉ ghi các thông số cần thiết để phục hồi cơ sở dữ liệu khi có sự số xảy ra, nó là mức ít chi tiết nhất.
Replica: Ngoài những thông số được ghi như minimal, với replica nó sẽ thêm các thông tin cần thiết để tạo ra thêm các bản sao.
Logical: Ngoài những thông số được ghi như replica, với logical nó sẽ sao chép dữ liệu một cách chi tiết hơn.
Tùy vào mục đích sử dụng mà các bạn lựa chọn cho phù hợp nhé, phần này mình sẽ nói chi tiết hơn ở 1 bài khác có sử dụng đến config này.
**Trên đây là một số config các bạn cần lưu ý, cảm ơn các bạn đã đọc tới đây, anh em có thắc mắc thì comment bên dưới, thấy hay cho mình 1 vote để có động lực thêm các bài hay ho cho series này 😁 **
All rights reserved
