Các phương pháp và công cụ kiểm thử dữ liệu lớn (Big Data Testing)
Bài đăng này đã không được cập nhật trong 8 năm
Các phương pháp và công cụ kiểm thử dữ liệu lớn (Big Data Testing)
Có thể nói chưa bao giờ các doanh nghiệp lại “khát” nhân lực về “Big Data” như hiện nay do ngày càng có nhiều công ty nhận ra được lợi ích to lớn từ việc khai thác và phân tích dữ liệu đối với hoạt động kinh doanh của họ. Đảo qua thị trường việc làm, sẽ không khó để bạn nhìn ra những mức lương hậu hĩnh cùng hàng tá những phụ cấp hấp dẫn khác cho công việc như “data scientist” (tạm dịch: chuyên gia dữ liệu) hay “data analyst” (phân tích dữ liệu). Đi kèm với đó chính là các chuyên gia về Big Data Testing.
Vậy Big Data là gì?
Big Data là thuật ngữ dùng để chỉ một tập hợp dữ liệu rất lớn và rất phức tạp đến nỗi những công cụ, ứng dụng xử lí dữ liệu truyền thống không thể nào đảm đương được. Tuy nhiên, Big Data lại chứa trong mình rất nhiều thông tin quý giá mà nếu trích xuất thành công, nó sẽ giúp rất nhiều cho việc kinh doanh, nghiên cứu khoa học, dự đoán các dịch bệnh sắp phát sinh và thậm chí là cả việc xác định điều kiện giao thông theo thời gian thực. Chính vì thế, những dữ liệu này phải được thu thập, tổ chức, lưu trữ, tìm kiếm, chia sẻ theo một cách khác so với bình thường. Kích cỡ của Big Data đang từng ngày tăng lên, và tính đến năm 2012 thì nó có thể nằm trong khoảng vài chục terabyte cho đến nhiều petabyte (1 petabyte = 1024 terabyte) chỉ cho một tập hợp dữ liệu mà thôi.
Vào năm 2001, nhà phân tích Doug Laney của hãng META Group (bây giờ chính là công ty nghiên cứu Gartner) đã nói rằng những thách thức và cơ hội nằm trong việc tăng trưởng dữ liệu có thể được mô tả bằng ba chiều: tăng về lượng (volume), tăng về vận tốc (velocity) và tăng về chủng loại (variety). Giờ đây, Gartner cùng với nhiều công ty và tổ chức khác trong lĩnh vực công nghệ thông tin tiếp tục sử dụng mô hình “3V” này để định nghĩa nên Big Data. Đến năm 2012, Gartner bổ sung thêm rằng Big Data ngoài ba tính chất trên thì còn phải “cần đến các dạng xử lí mới để giúp đỡ việc đưa ra quyết định, khám phá sâu vào sự vật/sự việc và tối ưu hóa các quy trình làm việc”.
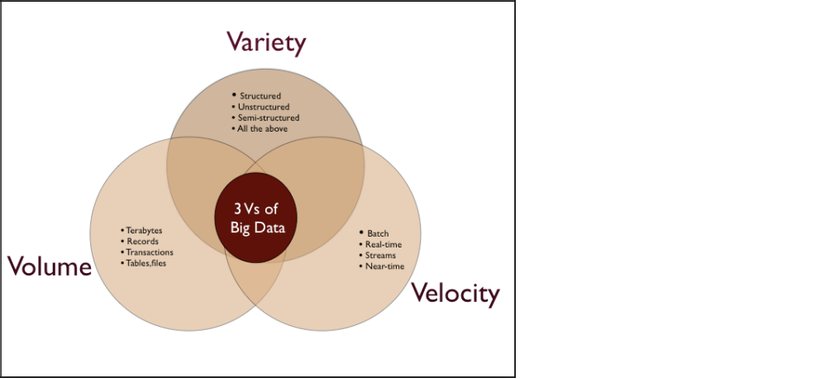 Mô hình 3V trong Big Data.
Mô hình 3V trong Big Data.
Nói tóm lại, Big Data là một tập hợp dữ liệu mà không thể phân tích/khai thác theo các phương pháp truyền thống. Do đó việc kiểm thử trên các tập dữ liệu lớn cũng cần sử dụng nhiều công cụ, kĩ thuật và nền tảng đặc thù khác nhau. Các định nghĩa chúng ta cần nắm trước khi thực hiện kiểm thử một tập dữ liệu lớn là : Big Data, Hadoop, MapReduce, ETL…
Chiến lược kiểm thử dữ liệu lớn là gì?
Việc kiểm thử một ứng dụng dữ liệu lớn sẽ tập trung vào các tiến trình xử lý/phân tích dữ liệu (process) hơn là tập trung vào các tính năng riêng lẻ của ứng dụng (features). Do đó khi nói đến kiểm thử dữ liệu lớn, chúng ta cần nghĩ ngay đến kiểm thử chức năng (functional testing) và kiểm thử hiệu năng (performance testing).
Trong kỹ thuật kiểm thử dữ liệu lớn, QA cần test luồng xử lý của hàng TeraByte dữ liệu trên các cluster khác nhau. Việc này yêu cầu các kĩ năng kiểm thử chuyên sâu, đặc biệt việc kiểm thử các tiến trình xử lý và phân tích dữ liệu. Các tiến trình này có thể phân làm 3 loại như sau :

Ngoài kĩ thuật kiểm thử các luồng xử lý dữ liệu (process) thì việc kiểm thử chất lượng dữ liệu cũng cực kì quan trọng. Việc này đòi hỏi kiểm thử nhiều đặc điểm khác nhau của dữ liệu : conformity (tính phù hợp), accuracy (tính chính xác), duplication (tính sao chép), consistency (tính nhất quán), validity (tính hợp lệ), data completeness (tính toàn vẹn)…
Các bước kiểm thử dữ liệu lớn :
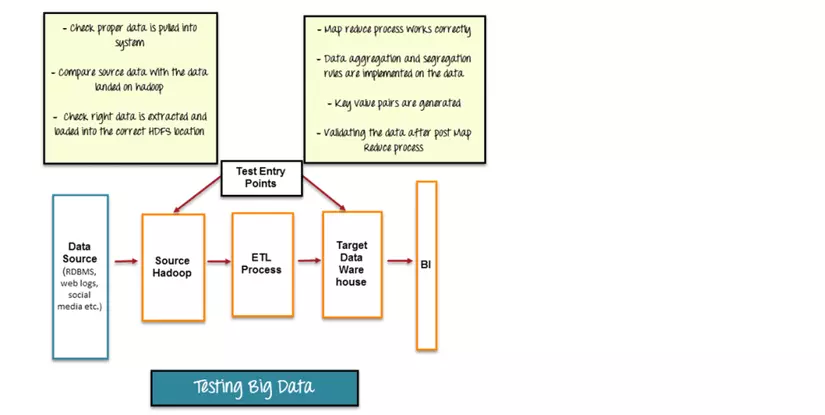 Kiểm thử dữ liệu lớn có thể tóm lược trong 3 bước như sau :
Kiểm thử dữ liệu lớn có thể tóm lược trong 3 bước như sau :
Bước 1 : Kiểm thử dữ liệu đầu vào
Bước đầu tiên của kiểm thử dữ liệu lớn là việc kiểm thử dữ liệu đầu vào, trong đó có 3 nhiệm vụ cơ bản như sau :
- Dữ liệu từ nhiều nguồn khác nhau : RDBMS, weblogs, social media… cần phải được kiểm tra để đảm bảo dữ liệu đầu vào cho hệ thống là chính xác.
- So sánh dữ liệu nguồn với dữ liệu đã được đẩy vào database hadoop
- Đảm bảo dữ liệu được bóc tách (extract) và đẩy (load) vào vị trí HDFS chính xác Các công cụ hỗ trợ nghiệp vụ này có Talend, Datameter.
Bước 2 : Kiểm thử tiến trình phân tích dữ liệu MapReduce
Bước thứ 2 là kiểm thử tiến trình phân tích dữ liệu Map Reduce. Trong bước này, tester cần kiểm thử logic của các tiến trình trên từng node khác nhau và kiểm thử sau khi chạy qua nhiều node, qua đó cần đảm bảo :
- Tiến trình phân tích dữ liệu MapReduce chạy chính xác.
- Kiểm thử các công thức tổng hợp hoặc phân tách dữ liệu
- Cặp Key-Value được sinh đầy đủ và chính xác
- Kiểm thử dữ liệu sau tiến trình MapReduce
Bước 3 : Kiểm thử kết quả đầu ra
Bước cuối cùng là kiểm thử kết quả đầu ra. File kết quả đầu ra được sinh sau bước MapReduce để đẩy vào DataWarehouse. Các nhiệm vụ như sau :
- Kiểm thử các quy tắc xử lý dữ liệu.
- Kiểm thử tính toàn vẹn dữ liệu được load vào hệ thống
- Đảm bảo không có dữ liệu bị sai lệch bằng cách so sánh dữ liệu trong hệ thống HDFS và dữ liệu đích.
Kiểm thử hiệu năng :
Việc kiểm thử hiệu năng trong Big Data bao gồm các nghiệp vụ chính như sau :
- Kiểm thử luồng xử lý dữ liệu đầu vào (ETL) : Tester thực hiện kiểm thử khả năng nhận dạng, xử lý (Get/Crawl => Extract => Convert/Decode/Filter/Combine => Load) nhiều loại dữ liệu khác nhau trong một khung thời gian cố định. Qua đó đảm bảo dữ liệu được xử lý kịp thời, không bị nghẽn luồng.
- Kiểm thử luồng phân tích dữ liệu (MapReduce) : Tester thực hiện kiểm thử tốc độ truy vấn dữ liệu, kiểm thử tốc độ các job MapReduce.
- Kiểm thử hiệu năng cho từng thành phần (Sub Component)
Phương pháp Kiểm thử hiệu năng :
Kiểm thử hiệu năng cho một ứng dụng Big Data yêu cầu việc kiểm tra khối lượng dữ liệu cực lớn với nhiều loại dữ liệu khác nhau, bao gồm cả có cấu trúc và phi cấu trúc, do đó đòi hỏi Tester phải có một phương pháp kiểm thử cụ thể :

Trong đó :
-
Quá trình bắt đầu với việc thiết lập các Cluster dữ liệu lớn để test
-
Xác định và phân tách khối lượng công việc tương ứng
-
Chuẩn bị các Script test
-
Chạy các Script test và phân tích kết quả => Nếu câu lệnh không phù hợp, thực hiện điều chỉnh và cho chạy lại
-
Tối ưu hóa các cấu hình.
Các tham số cần quan tâm trước khi kiểm thử hiệu năng :
- Data Storage : cách lưu trữ dữ liệu trên các node khác nhau.
- Commit log : dung lượng tối đa của commit log trong cấu hình
- Concurrency : số lượng tiến trình đọc/ghi đồng thời
- Caching : cấu hình cache cho Row và Key
- Timeout : các tham số timeout kết nối, timeout câu lệnh…
- JVM Heapsize : các tham số cấu hình của java như heap size, GC maximum…
- Các tham số Map Reduce : sort, merge… **Môi trường Test : **
Môi trường test phụ thuộc vào từng loại ứng dụng, với kiểm thử dữ liệu lớn, môi trường test bao gồm :
- Yêu cầu đảm bảo đủ dung lượng lưu trữ và xử lý khối lượng dữ liệu lớn
- Thiết lập cụm lưu trữ và xử lý dữ liệu lớn với nhiều node phân tán
- Đảm bảo đủ CPU và RAM để kiểm thử hiệu năng
**Công cụ: **
| Big Data Cluster | Big Data Tools |
|---|---|
| NoSQL: | CouchDB, DatabasesMongoDB, Cassandra, Redis, ZooKeeper, Hbase |
| MapReduce: | Hadoop, Hive, Pig, Cascading, Oozie, Kafka, S4, MapR, Flume |
| Storage: | S3, HDFS ( Hadoop Distributed File System) |
| Servers: | Elastic, Heroku, Elastic, Google App Engine, EC2 |
| Processing: | R, Yahoo! Pipes, Mechanical Turk, BigSheets, Datameer |
Kết luận :
- Việc kiểm thử dữ liệu lớn là xu hướng trong thời gian tới, đặc biệt khi các công nghệ về Big Data đang ngày càng phát triển.
- Các tiến trình xử lý dữ liệu lớn có thể chia làm 3 loại chính : Batch, RealTime, Interactive
- Kiểm thử ứng dụng BigData có 3 phần chính : kiểm thử dữ liệu; kiểm thử tiến trình MapReduce; kiểm thử kết quả đầu ra
- Kiểm thử hiệu năng BigData bao gồm : kiểm thử xử lý dữ liệu (ETL); kiểm thử phân tích dữ liệu (MapReduce); kiểm thử hiệu năng của từng thành phần (Sub Component)
All rights reserved
