Các Phương Pháp Triển Khai Database MySQL - Từ Cơ Bản Đến Enterprise
Chào các bạn! Trong thế giới phát triển phần mềm hiện đại, việc triển khai database không chỉ đơn thuần là cài đặt và chạy. Nó còn liên quan đến việc đảm bảo High Availability (HA), Scalability, Data Consistency và khả năng tự động phục hồi. Hôm nay chúng ta sẽ cùng khám phá hành trình tiến hóa của triển khai MySQL Database - từ mô hình truyền thống đơn giản đến các giải pháp enterprise phức tạp! 🗄️
Tại Sao Cần Quan Tâm Đến Cách Triển Khai Database?
Thách Thức Của Hệ Thống Hiện Đại
Trong các hệ thống hiện đại, cơ sở dữ liệu không chỉ cần lưu trữ dữ liệu đúng mà còn phải:
🎯 Các Yêu Cầu Cốt Lõi:
- High Availability (HA): Hoạt động liên tục 24/7, downtime gần như bằng 0
- Scalability: Mở rộng được khi tải tăng lên (cả đọc và ghi)
- Consistency: Đảm bảo toàn vẹn và nhất quán dữ liệu
- Performance: Phản hồi nhanh với khối lượng truy vấn lớn
- Disaster Recovery: Khả năng phục hồi nhanh khi gặp sự cố
- Cost Efficiency: Tối ưu chi phí vận hành và mở rộng
💡 Thực Tế Trong Doanh Nghiệp:
- 1 giây downtime của Amazon = mất $220,318 doanh thu
- 1 phút downtime của Google = mất $500,000 doanh thu
- Database outage là nguyên nhân chính gây ra downtime (35% các trường hợp)
MySQL – một trong những hệ quản trị cơ sở dữ liệu phổ biến nhất thế giới – cung cấp bốn cấp độ triển khai từ cơ bản đến nâng cao để đáp ứng những nhu cầu này.
I. Single Instance - Triển Khai Truyền Thống Đơn Giản
Bản Chất và Đặc Điểm
Single Instance là mô hình triển khai cơ bản nhất: một máy chủ MySQL duy nhất phục vụ tất cả các requests (cả đọc và ghi).
🏗️ Kiến Trúc Đơn Giản:
┌─────────────────┐
│ Application │
└────────┬────────┘
│
▼
┌─────────────────┐
│ MySQL Server │
│ (Single Node) │
└─────────────────┘
📊 Đặc Điểm Chính:
- Một điểm xử lý: Tất cả operations đều đi qua một server duy nhất
- Đơn giản nhất: Dễ cài đặt, cấu hình và quản lý
- Chi phí thấp: Chỉ cần một server, không cần infrastructure phức tạp
- Không có redundancy: Không có backup node tự động
Ưu Điểm của Single Instance
✅ Đơn Giản và Dễ Quản Lý:
- Setup nhanh chóng, không cần configuration phức tạp
- Troubleshooting dễ dàng vì chỉ có một node
- Không cần lo về data synchronization
✅ Chi Phí Thấp:
- Chỉ cần một server
- Không tốn bandwidth cho data replication
- Maintenance đơn giản, ít nhân lực
✅ Performance Tốt Cho Hệ Thống Nhỏ:
-- Với traffic nhỏ, single instance hoạt động rất tốt
-- Ví dụ: Website blog cá nhân, startup giai đoạn đầu
SELECT * FROM posts WHERE status = 'published'
ORDER BY created_at DESC LIMIT 10;
-- Response time: < 10ms với proper indexing
✅ Consistency Tuyệt Đối:
- Không có eventual consistency issues
- Mọi transaction đều ACID compliant
- Không có replica lag
Nhược Điểm và Hạn Chế
❌ Single Point of Failure (SPOF):
Server hỏng = Toàn bộ ứng dụng ngừng hoạt động
├── Hardware failure (ổ cứng, RAM, CPU)
├── Network issues
├── Software crash
└── Human errors (cấu hình sai, xóa nhầm data)
❌ Không Có High Availability:
- Downtime khi maintenance (update, patching)
- Không tự động failover
- Recovery time phụ thuộc vào kỹ năng admin
❌ Giới Hạn Về Scalability:
-- Khi traffic tăng, single instance gặp bottleneck
-- Ví dụ: 10,000 concurrent connections
SHOW STATUS LIKE 'Threads_connected';
-- Nếu vượt max_connections → từ chối kết nối mới
-- Error: "Too many connections"
❌ Limited Performance:
- Vertical scaling đắt đỏ (tăng RAM, CPU có giới hạn)
- Không thể phân tán tải đọc
- Một query chậm ảnh hưởng toàn bộ hệ thống
Khi Nào Nên Dùng Single Instance?
| Tình Huống | Lý Do Phù Hợp |
|---|---|
| Startup/MVP | Chi phí thấp, triển khai nhanh, traffic nhỏ |
| Development Environment | Môi trường test, không cần HA |
| Small Applications | Blog cá nhân, website nội bộ, < 1000 users |
| Budget Limited | Không đủ ngân sách cho infrastructure phức tạp |
| Simple Requirements | Không có yêu cầu uptime 99.9% |
💼 Ví Dụ Thực Tế:
- Blog WordPress cá nhân: 1,000 visitors/ngày
- Tool nội bộ công ty: 50-100 users
- Portfolio website: Static content chủ yếu
- Prototype/Demo application
II. MySQL Replication - Sao Chép Dữ Liệu Truyền Thống
Bản Chất và Mục Tiêu
Replication trong MySQL là cơ chế sao chép dữ liệu từ một máy chủ chính (Master) sang một hoặc nhiều máy chủ phụ (Slave).
🎯 Mục Tiêu Chính:
- Phân tán tải đọc: Ghi vào Master, đọc từ Slave
- Tạo bản sao dữ liệu dự phòng: Backup realtime
- Dễ dàng khôi phục: Promote Slave thành Master khi cần
- Geographic distribution: Đặt replica ở nhiều vùng địa lý
Replication là giải pháp "cổ điển" nhất, tồn tại từ những phiên bản MySQL đầu tiên, và vẫn được dùng rộng rãi trong hệ thống có nhu cầu mở rộng đọc.
Kiến Trúc Replication

🏗️ Master-Slave Architecture:
┌─────────────────┐
│ Application │
└────────┬────────┘
│
Write│Read
│
┌────▼─────┐ Binary Log
│ Master │─────────────────┐
│ (Write) │ │
└──────────┘ │
│
┌───────────────────────┴─────────────────────┐
│ │ │
┌────▼─────┐ ┌────▼─────┐ ┌────▼─────┐
│ Slave 1 │ │ Slave 2 │ │ Slave 3 │
│ (Read) │ │ (Read) │ │ (Read) │
└──────────┘ └──────────┘ └──────────┘
Cơ Chế Hoạt Động
Replication dựa trên Binary Log (binlog) – file ghi lại mọi thay đổi dữ liệu.
📝 Quy Trình Sao Chép:
1. Master thực hiện thay đổi (INSERT/UPDATE/DELETE)
↓
2. Master ghi thay đổi vào Binary Log
↓
3. Slave đọc Binary Log từ Master (IO Thread)
↓
4. Slave ghi vào Relay Log (trung gian)
↓
5. Slave replay các thay đổi từ Relay Log (SQL Thread)
↓
6. Dữ liệu trên Slave được cập nhật
🔄 Hai Mô Hình Đồng Bộ:
Asynchronous Replication (Bất đồng bộ):
-- Master không chờ Slave xác nhận
-- Giao dịch commit ngay lập tức
BEGIN;
INSERT INTO orders (user_id, amount) VALUES (1, 100);
COMMIT; -- ✓ Xong ngay, không đợi Slave
-- Rủi ro: Nếu Master chết trước khi Slave đọc binlog
-- → Mất dữ liệu giao dịch cuối cùng
Semi-Synchronous Replication (Bán đồng bộ):
-- Master chờ ít nhất 1 Slave xác nhận đã nhận binlog
-- An toàn hơn nhưng chậm hơn một chút
-- Cấu hình trên Master:
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
SET GLOBAL rpl_semi_sync_master_enabled = 1;
SET GLOBAL rpl_semi_sync_master_timeout = 1000; -- 1 second
-- Cấu hình trên Slave:
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
SET GLOBAL rpl_semi_sync_slave_enabled = 1;
Ưu Điểm của Replication
✅ Đơn Giản và Dễ Triển Khai:
# Setup nhanh, cấu hình nhẹ
# Chỉ cần thêm vài dòng config và vài câu SQL
✅ Hiệu Quả Cho Việc Mở Rộng Đọc:
// Application code - Phân tách đọc/ghi
const mysql = require('mysql2');
// Master connection (for writes)
const masterPool = mysql.createPool({
host: '192.168.1.100',
user: 'app_user',
password: 'password',
database: 'myapp_db'
});
// Slave connections (for reads)
const slavePool = mysql.createPool({
host: '192.168.1.101',
user: 'app_user',
password: 'password',
database: 'myapp_db'
});
// Ghi dữ liệu → Master
function createOrder(userId, amount) {
return masterPool.execute(
'INSERT INTO orders (user_id, amount, created_at) VALUES (?, ?, NOW())',
[userId, amount]
);
}
// Đọc dữ liệu → Slave
function getOrders(userId) {
return slavePool.execute(
'SELECT * FROM orders WHERE user_id = ? ORDER BY created_at DESC',
[userId]
);
}
✅ Backup Realtime:
- Slave luôn có bản copy gần như realtime của Master
- Có thể dump từ Slave mà không ảnh hưởng Master
✅ Geographic Distribution:
Master (US East)
│
├─→ Slave 1 (US West) - Phục vụ users West Coast
├─→ Slave 2 (EU) - Phục vụ users châu Âu
└─→ Slave 3 (Asia) - Phục vụ users châu Á
Nhược Điểm và Hạn Chế
❌ Không Có Tự Động Failover:
-- Khi Master chết, cần thao tác thủ công:
-- 1. Chọn Slave để promote
-- 2. Stop replication trên Slave đó
STOP SLAVE;
-- 3. Promote Slave thành Master
RESET MASTER;
SET GLOBAL read_only = 0;
-- 4. Cấu hình các Slave khác trỏ đến Master mới
-- 5. Update application config
-- → Downtime 5-30 phút tùy kỹ năng
❌ Replication Lag - Độ Trễ Sao Chép:
-- Slave có thể chậm hơn Master
SHOW SLAVE STATUS\G
-- Seconds_Behind_Master: 5 → Slave chậm 5 giây
-- Vấn đề: User vừa tạo order trên Master
-- Nhưng đọc từ Slave → chưa thấy order mới
-- Solution: Read-after-Write Consistency
-- → Sau khi ghi, đọc từ Master trong vài giây
❌ Chỉ Một Node Ghi:
- Không thể scale writes (ghi)
- Master có thể trở thành bottleneck khi write traffic cao
❌ Dễ Mất Dữ Liệu (Async Mode):
Master crash sau khi commit nhưng trước khi Slave đọc binlog
→ Mất transactions cuối cùng
Khi Nào Nên Dùng Replication?
| Tình Huống | Lý Do Phù Hợp |
|---|---|
| Hệ thống đọc nhiều - ghi ít | Dùng nhiều Slave để scale đọc, giảm tải Master |
| Cần backup realtime | Slave giữ bản sao an toàn để restore |
| Geographic distribution | Đặt replica gần users để giảm latency |
| Analytics/Reporting | Chạy heavy queries trên Slave, không ảnh hưởng production |
| Triển khai đơn giản | Hạ tầng nhỏ, dễ vận hành, chi phí thấp |
💼 Ví Dụ Thực Tế:
- Website tin tức: 90% đọc, 10% ghi (đăng bài)
- E-commerce: Đọc sản phẩm từ Slave, ghi order vào Master
- Social media feed: Đọc timeline từ nhiều Slave
- Blog platform: WordPress Multisite với read replicas
III. MySQL Group Replication - Đồng Bộ Nhiều Node, Tự Động Phục Hồi

Lý Do Ra Đời
Replication truyền thống tuy hiệu quả nhưng không đáp ứng được nhu cầu:
- ❌ Tự động phát hiện lỗi và chuyển vai trò (failover)
- ❌ Giữ tính nhất quán dữ liệu mạnh (strong consistency)
- ❌ Hỗ trợ ghi trên nhiều node (multi-master)
→ Group Replication ra đời để biến cụm MySQL thành một hệ thống phân tán có tính sẵn sàng cao (HA) và đồng bộ giao dịch theo nhóm.
🎯 Mục Tiêu của Group Replication:
- Automatic Failover: Tự động phát hiện node hỏng và bầu Primary mới
- Strong Consistency: Dữ liệu đồng nhất trên tất cả nodes
- Flexible Configuration: Hỗ trợ cả Single-Primary và Multi-Primary mode
- Built-in Conflict Detection: Phát hiện và xử lý xung đột giao dịch
Nguyên Lý Hoạt Động
🔄 Group Communication và Consensus:
Group Replication sử dụng cơ chế "group communication" và consensus protocol (dựa trên Paxos).
Giao dịch được gửi đến nhóm
↓
Tất cả nodes trong group nhận được
↓
Nodes bỏ phiếu (voting) để chấp nhận
↓
Đạt quorum (đa số > 50%) → Commit
↓
Tất cả nodes apply transaction
🏗️ Kiến Trúc Group Replication:
┌─────────────────────────────────────────────────────┐
│ MySQL Group Replication │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐│
│ │ Member 1 │◄────►│ Member 2 │◄────►│ Member 3 ││
│ │(Primary) │ │(Secondary)│ │(Secondary)││
│ └──────────┘ └──────────┘ └──────────┘│
│ ▲ ▲ ▲ │
│ └─────────────────┴─────────────────┘ │
│ Group Communication Layer │
└─────────────────────────────────────────────────────┘
Hai Chế Độ Vận Hành
1️⃣ Single-Primary Mode (Khuyến Nghị):
- 1 node PRIMARY (ghi + đọc)
- N nodes SECONDARY (chỉ đọc)
- Khi Primary chết → Tự động bầu Secondary thành Primary mới
- Đơn giản hơn, ít xung đột hơn
2️⃣ Multi-Primary Mode:
- Tất cả nodes đều có thể ghi
- Hệ thống tự động phát hiện xung đột (Conflict Detection)
- Phức tạp hơn, yêu cầu application xử lý conflicts
- Phù hợp cho write scaling
Automatic Failover Demo
🔄 Kịch Bản Failover Tự Động:
-- Giả sử Primary node (Node 1) bị crash
-- 1. Group phát hiện Node 1 không phản hồi (heartbeat timeout)
-- 2. Các Secondary nodes tự động bầu chọn Primary mới
-- 3. Ví dụ Node 2 được chọn làm Primary
-- 4. Application có thể tiếp tục ghi vào Node 2
-- Kiểm tra sau khi failover:
SELECT * FROM performance_schema.replication_group_members;
-- Node 2 giờ có MEMBER_ROLE = PRIMARY
-- Node 3 vẫn là SECONDARY
-- Node 1 không còn trong list (hoặc UNREACHABLE)
-- Downtime: ~5-10 giây (thời gian phát hiện + bầu chọn)
Ưu Điểm của Group Replication
✅ Automatic Failover:
Primary crash → Group tự động bầu Primary mới
Không cần manual intervention
Downtime tối thiểu (~5-10 giây)
✅ Strong Consistency:
-- Transaction chỉ commit khi đạt quorum (đa số chấp nhận)
BEGIN;
INSERT INTO orders (user_id, amount) VALUES (1, 1000);
COMMIT;
-- ✓ Commit thành công = dữ liệu đã an toàn trên đa số nodes
-- Không lo mất dữ liệu như Async Replication
✅ Tự Động Thêm/Bỏ Node:
-- Thêm node mới vào group
-- Node tự động sync data từ group
START GROUP_REPLICATION;
-- Node tự động join và đồng bộ dữ liệu
-- Bỏ node ra khỏi group
STOP GROUP_REPLICATION;
-- Group tự động điều chỉnh quorum
✅ Built-in Conflict Detection (Multi-Primary Mode):
-- Phát hiện xung đột ghi đồng thời
-- Node 1: UPDATE accounts SET balance = balance - 100 WHERE id = 1;
-- Node 2: UPDATE accounts SET balance = balance - 50 WHERE id = 1;
-- → Hệ thống phát hiện conflict và rollback 1 trong 2
Nhược Điểm và Hạn Chế
❌ Cấu Hình Phức Tạp:
- Yêu cầu GTID (Global Transaction ID)
- Nhiều parameters cần tune
- Learning curve cao hơn Replication
❌ Hiệu Năng Ghi Thấp Hơn:
Async Replication: commit ngay lập tức
Group Replication: chờ quorum (đa số) xác nhận
→ Latency cao hơn ~10-30ms per transaction
❌ Yêu Cầu Mạng Ổn Định:
- Network latency cao → performance giảm
- Network partition → có thể split-brain
- Khuyến nghị: latency < 5ms giữa các nodes
❌ Giới Hạn Về Số Node:
- Khuyến nghị tối đa 9 nodes
- Càng nhiều nodes → consensus càng chậm
❌ Không Phù Hợp Write-Heavy Workload:
-- Workload ghi cực lớn (1000+ writes/sec)
-- Group Replication có thể không theo kịp
-- → Xem xét sharding hoặc giải pháp khác
❌ Application Phải Tự Quản Lý Connection:
- ⚠️ Vấn đề chính: Mặc dù Group tự động bầu Primary mới, nhưng application vẫn phải TỰ CẬP NHẬT connection string
- Khi Primary chết và node mới được bầu → Application phải tự detect và reconnect đến IP mới
- Không transparent như InnoDB Cluster + Router (Router tự động routing, application không cần biết)
Khi Nào Nên Dùng Group Replication?
| Tình Huống | Lý Do Phù Hợp |
|---|---|
| Cần HA và auto failover | Group tự động phát hiện lỗi và chuyển Primary |
| Đảm bảo data consistency | Giao dịch đồng bộ, không mất dữ liệu |
| Môi trường cloud/container | Nodes có thể tự động scale up/down |
| Giảm downtime gần 0 | Failover tự động trong vài giây |
| Write moderate, read high | Phù hợp với workload cân bằng |
💼 Ví Dụ Thực Tế:
- Banking/Finance: Giao dịch tài chính không thể mất dữ liệu
- Payment Gateway: Cổng thanh toán cần HA và consistency
- Healthcare Systems: Dữ liệu bệnh nhân quan trọng
- E-commerce Checkout: Đặt hàng cần đảm bảo không mất
- Internal Business Apps: ERP, CRM cần uptime cao
⚠️ Lưu Ý Quan Trọng:
Group Replication có auto failover, NHƯNG application vẫn phải tự update connection đến Primary mới!
Muốn 100% transparent (application không cần làm gì) → Dùng InnoDB Cluster + Router
Group Replication phù hợp khi: có thể implement connection logic trong app, hoặc dùng proxy (ProxySQL, HAProxy)
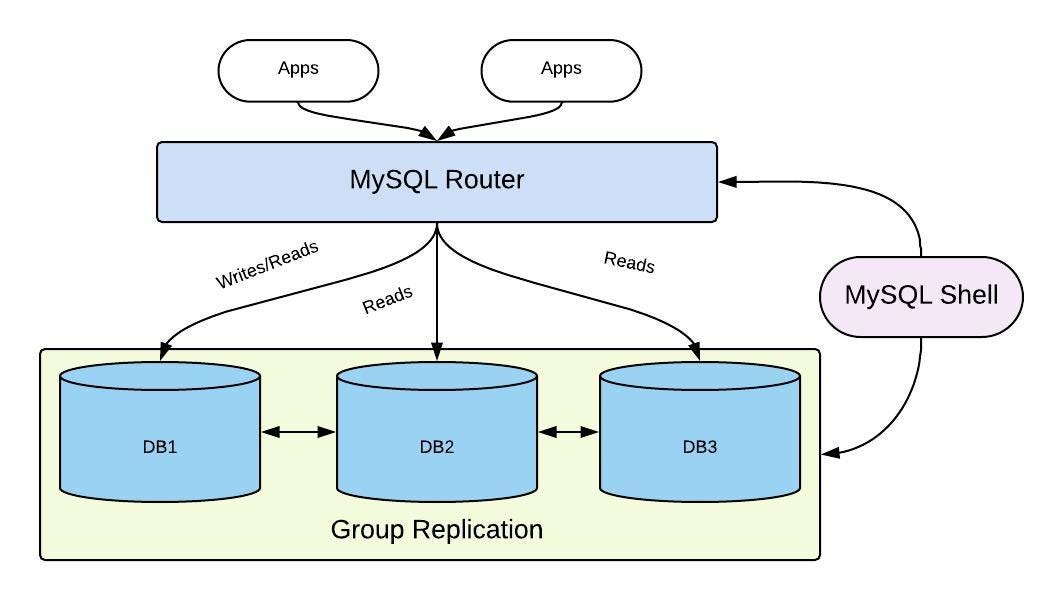
IV. InnoDB Cluster + MySQL Router - Giải Pháp HA Hoàn Chỉnh

Tổng Quan
InnoDB Cluster là giải pháp "all-in-one" của MySQL, kết hợp ba thành phần:
1️⃣ Group Replication:
- Cung cấp đồng bộ dữ liệu và automatic failover
- Nền tảng của toàn bộ cluster
2️⃣ MySQL Shell:
- Tool quản trị cluster dễ dàng
- AdminAPI để tạo và quản lý cluster
- Hỗ trợ scripting (JavaScript, Python, SQL)
3️⃣ MySQL Router:
- Reverse proxy thông minh
- Tự động điều hướng kết nối đến node phù hợp
- Application không cần biết topology của cluster
🎯 Mục Tiêu:
"Ứng dụng không cần biết node nào là Primary – Router sẽ tự động chọn và điều hướng kết nối phù hợp."
Kiến Trúc InnoDB Cluster
🏗️ Complete Architecture:
┌──────────────────────────────────────────────────────────┐
│ Applications │
└────────────────────┬─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ MySQL Router (Port 6446/6447) │
│ - Điều hướng Write → Primary │
│ - Điều hướng Read → Secondary (load balance) │
│ - Tự động failover khi topology thay đổi │
└────────┬────────────────────────┬────────────────────────┘
│ │
Write│ │Read
│ │
┌────▼────────┐ ┌────▼─────────┐
│ │ │ │
│ Primary │◄────────►│ Secondary │
│ (R/W) │ │ (Read) │
│ │ │ │
└──────┬──────┘ └──────┬───────┘
│ │
│ ┌──────────────┐ │
└───►│ Secondary │◄───┘
│ (Read) │
└──────────────┘
Group Replication Communication
MySQL Router - Trái Tim Của InnoDB Cluster
🎯 Chức Năng Chính của Router:
1. Automatic Connection Routing:
// Application chỉ cần connect đến Router
// Không cần biết node nào là Primary
// Read-Write Connection (Port 6446) → Tự động đến Primary
const writePool = mysql.createPool({
host: '192.168.1.100', // Router IP
port: 6446, // Router Read-Write port
user: 'app_user',
password: 'password',
database: 'myapp_db'
});
// Read-Only Connection (Port 6447) → Load balance giữa Secondaries
const readPool = mysql.createPool({
host: '192.168.1.100', // Router IP
port: 6447, // Router Read-Only port
user: 'app_user',
password: 'password',
database: 'myapp_db'
});
// Write operation
await writePool.execute('INSERT INTO orders (user_id, amount) VALUES (?, ?)', [1, 100]);
// Read operation - Router tự động load balance
await readPool.execute('SELECT * FROM orders WHERE user_id = ?', [1]);
2. Transparent Failover:
Primary (Node 1) crash
↓
Group Replication bầu Primary mới (Node 2)
↓
Router phát hiện topology thay đổi
↓
Router cập nhật routing table
↓
Kết nối mới tự động đến Node 2
↓
Application không bị gián đoạn (chỉ retry connection)
3. Load Balancing:
Read Query → Router
↓
Router phân phối Round-Robin hoặc Least-Connections
│
├─→ Secondary 1 (40% traffic)
├─→ Secondary 2 (40% traffic)
└─→ Secondary 3 (20% traffic)
Ưu Điểm của InnoDB Cluster
✅ Tự Động Hoàn Toàn:
- Cluster tự giám sát, tự bầu Primary mới
- Router tự động cập nhật routing
- Không cần manual intervention
✅ Transparent cho Application (Khác Biệt Lớn Với Group Replication):
- ✨ Ưu điểm lớn nhất: Application chỉ cần trỏ đến Router (IP cố định), Router tự động routing đến Primary
- Connection string KHÔNG BAO GIỜ thay đổi - dù Primary có failover bao nhiêu lần
- So sánh Group Replication: Phải tự detect Primary mới và update connection → Phức tạp
- Với Router: 100% transparent, application không cần biết topology thay đổi
✅ High Availability Thực Sự:
Downtime: < 10 giây (failover + Router update)
Uptime target: 99.95% - 99.99%
Application: Chỉ cần retry failed connections
✅ Quản Lý Tập Trung:
// MySQL Shell AdminAPI
cluster.status() // Xem trạng thái
cluster.describe() // Xem cấu hình
cluster.addInstance(uri) // Thêm node
cluster.removeInstance(uri) // Xóa node
cluster.setPrimaryInstance(uri) // Chuyển Primary thủ công
cluster.rejoinInstance(uri) // Join lại node bị disconnect
✅ Load Balancing Thông Minh:
- Read queries tự động phân tán đều
- Write queries luôn đến Primary
- Health check tự động loại bỏ node unhealthy
Nhược Điểm và Hạn Chế
❌ Yêu Cầu Tài Nguyên Cao:
- Tối thiểu 3 MySQL nodes + 1 Router
- RAM, CPU, Network bandwidth cao
- Chi phí infrastructure lớn
❌ Độ Phức Tạp Cao:
- Cần hiểu sâu về Group Replication, Router, Shell
- Troubleshooting khó hơn nhiều
- Yêu cầu team có experience
❌ Cấu Hình Ban Đầu Phức Tạp:
- Setup cluster không đơn giản như Replication
- Nhiều components cần configure đúng
- Testing và validation mất thời gian
❌ Yêu Cầu Mạng Tốt:
- Latency thấp giữa nodes (< 5ms)
- Bandwidth cao cho Group Replication
- Network partition = rủi ro split-brain
Khi Nào Nên Dùng InnoDB Cluster?
| Tình Huống | Lý Do Phù Hợp |
|---|---|
| Enterprise Applications | Doanh nghiệp cần HA thực sự, downtime = thiệt hại lớn |
| Critical Systems | Banking, Finance, Healthcare - không thể ngắt dịch vụ |
| Cloud-Native Apps | Kubernetes, Docker - tự động scale và recover |
| Multi-Application Environment | Nhiều apps dùng chung DB, Router phân phối tối ưu |
| Global Services | Dịch vụ phục vụ toàn cầu, cần uptime 99.99% |
| Budget Sufficient | Đủ ngân sách cho infrastructure và nhân lực |
💼 Ví Dụ Thực Tế:
- Banking Core System: Giao dịch ngân hàng 24/7
- E-commerce Platform: Amazon, Shopee - checkout không thể downtime
- Fintech: Payment gateway, crypto exchange
- SaaS Platform: Enterprise SaaS với SLA 99.95%+
- Healthcare Records: Hệ thống bệnh án điện tử
- ERP/CRM: SAP, Salesforce-like systems
IV.2 So Sánh: Group Replication vs InnoDB Cluster
Khác Biệt Quan Trọng: Connection Management
🔴 Group Replication (Không có Router):
- Application connect trực tiếp đến Primary node (IP cố định: 192.168.1.100)
- Khi Primary chết:
- Group tự động bầu Primary mới (192.168.1.101)
- ❌ Application phải tự detect Primary mới
- ❌ Phải update connection string (đổi IP)
- ❌ Phải implement retry logic phức tạp
- Kết quả: Code phức tạp, nhiều edge cases
🟢 InnoDB Cluster + Router (Transparent):
- Application connect đến Router (IP cố định: mysql-router-ip)
- Khi Primary chết:
- Group tự động bầu Primary mới
- ✅ Router tự động phát hiện topology thay đổi
- ✅ Router tự động route connection mới đến Primary mới
- ✅ Application chỉ cần retry connection (như bình thường)
- Kết quả: 100% transparent, code đơn giản
📊 So Sánh Trực Quan:
┌──────────────────────────────────────────────────────────────┐
│ GROUP REPLICATION (Không Router) │
├──────────────────────────────────────────────────────────────┤
│ Application │
│ ↓ ↓ ↓ │
│ [Complex Connection Logic] │
│ - Detect failure │
│ - Query metadata │
│ - Find new Primary │
│ - Update connection │
│ ↓ │
│ MySQL Nodes (Primary + Secondaries) │
│ │
│ ❌ Application PHẢI biết về topology │
│ ❌ Phải implement failover logic │
│ ❌ Hard-coded IPs hoặc phức tạp │
└──────────────────────────────────────────────────────────────┘
┌──────────────────────────────────────────────────────────────┐
│ INNODB CLUSTER + ROUTER │
├──────────────────────────────────────────────────────────────┤
│ Application │
│ ↓ │
│ [Simple Connection - Fixed IP] │
│ ↓ │
│ MySQL Router ← Monitors topology │
│ ↓ ↓ ↓ │
│ [Auto Routing Logic] │
│ - Detects Primary │
│ - Load balances Secondaries │
│ - Auto failover │
│ ↓ │
│ MySQL Nodes (Primary + Secondaries) │
│ │
│ ✅ Application KHÔNG cần biết topology │
│ ✅ Router xử lý tất cả │
│ ✅ Connection string KHÔNG BAO GIỜ đổi │
└──────────────────────────────────────────────────────────────┘
💡 Kết Luận:
- Group Replication = Tự động failover ở database layer, nhưng application phải tự update connection
- InnoDB Cluster = Group Replication + Router = Transparent HA hoàn chỉnh (application không cần làm gì)
V. So Sánh Tổng Thể Bốn Mô Hình
Bảng So Sánh Chi Tiết
| Tiêu Chí | Single Instance | Replication | Group Replication | InnoDB Cluster |
|---|---|---|---|---|
| 🎯 Mục tiêu chính | Đơn giản, chi phí thấp | Mở rộng đọc, backup | HA và consistency | HA hoàn chỉnh + routing |
| 📊 Số node ghi | 1 | 1 (Master) | 1 hoặc N | 1 (Primary) |
| 📈 Scalability đọc | ❌ Không | ✅ Tốt (nhiều Slaves) | ✅ Tốt (Secondaries) | ✅ Tốt + Load balancing |
| 📈 Scalability ghi | ❌ Không | ❌ Không | ⚡ Có (Multi-Primary) | ❌ Không |
| 🔄 Automatic Failover | ❌ Không | ❌ Không | ✅ Có | ✅ Có + Transparent |
| 🔌 Connection Management | Direct DB | Direct Master/Slave | Direct Primary (phải update khi failover) | Via Router (auto, transparent) |
| 🎯 Data Consistency | ✅ Tuyệt đối | ⚡ Eventual | ✅ Strong | ✅ Strong |
| ⚡ Độ trễ replication | N/A | Có (Async) | Thấp (Sync) | Thấp (Sync) |
| 💾 Redundancy | ❌ Không | ✅ Có (Slaves) | ✅ Có (Group) | ✅ Có (Group) |
| 🔧 Độ phức tạp setup | ⭐ Rất thấp | ⭐⭐ Thấp | ⭐⭐⭐ Trung bình | ⭐⭐⭐⭐ Cao |
| 👨💻 Yêu cầu kỹ năng | Junior | Mid-level | Senior | Senior/Expert |
| 💰 Chi phí | $ | $$ | $$$ | $$$$ |
| 📊 Uptime target | 95-98% | 98-99% | 99.5-99.9% | 99.95-99.99% |
| ⚙️ Management tool | Manual | Manual | Manual/Shell | MySQL Shell + Router |
| 🌐 Network requirement | Thấp | Trung bình | Cao (low latency) | Cao (low latency) |
| 📚 Use cases | Dev, MVP, small apps | Read-heavy apps | Business apps | Mission-critical |
Decision Tree - Cây Quyết Định
Bạn cần triển khai MySQL Database?
│
├─→ MVP/Prototype/Development?
│ └─→ ✅ Single Instance
│
├─→ Production nhưng budget hạn chế?
│ ├─→ Read-heavy (90%+ đọc)?
│ │ └─→ ✅ Replication (1 Master + N Slaves)
│ └─→ Write-heavy?
│ └─→ ⚠️ Xem xét sharding hoặc NoSQL
│
├─→ Cần High Availability và tự động failover?
│ ├─→ Budget trung bình, accept 10-30s downtime?
│ │ └─→ ✅ Group Replication
│ └─→ Budget cao, cần downtime < 10s?
│ └─→ ✅ InnoDB Cluster + Router
│
└─→ Enterprise, mission-critical, SLA 99.95%+?
└─→ ✅ InnoDB Cluster + Router (+ Monitoring)
Nhu Cầu và Giải Pháp
| Nhu Cầu | Giải Pháp Phù Hợp | Lý Do |
|---|---|---|
| Startup giai đoạn đầu | Single Instance | Chi phí thấp, setup nhanh, đủ cho traffic nhỏ |
| Website tin tức, blog | Replication | 90% đọc, cần scale read, backup realtime |
| E-commerce nhỏ/vừa | Replication | Đọc sản phẩm nhiều, ghi order ít hơn |
| SaaS B2B Application | Group Replication | Cần HA, tự động failover, data consistency |
| Banking/Financial | InnoDB Cluster | Mission-critical, không thể downtime, SLA cao |
| Healthcare System | InnoDB Cluster | Dữ liệu nhạy cảm, cần HA và consistency |
| Gaming Leaderboard | Xem xét Redis | Write-heavy realtime, MySQL không phù hợp |
| Analytics/Big Data | Xem xét ClickHouse | OLAP workload, MySQL không tối ưu |
VI. Roadmap Triển Khai Từ Nhỏ Đến Lớn
Giai Đoạn 1: Startup (0-1K Users)
Single Instance
├─ 1 MySQL server
├─ Daily mysqldump backups
├─ Basic monitoring (CloudWatch, DataDog free tier)
└─ Chi phí: ~$50-100/tháng (t2.small/t2.medium)
Giai Đoạn 2: Growth (1K-10K Users)
Master-Slave Replication
├─ 1 Master (writes)
├─ 2 Slaves (reads, backup)
├─ Load balancer cho read traffic
├─ Automated backups + offsite
└─ Chi phí: ~$300-500/tháng
Giai Đoạn 3: Scale (10K-100K Users)
Group Replication hoặc Managed Service
├─ 3-node Group Replication (self-managed)
│ hoặc AWS RDS Multi-AZ / Aurora
├─ Read replicas cho analytics
├─ Redis cache layer
├─ Advanced monitoring (Prometheus + Grafana)
└─ Chi phí: ~$1,000-2,000/tháng
Giai Đoạn 4: Enterprise (100K+ Users)
InnoDB Cluster + Multi-Region
├─ Primary Cluster (3+ nodes + Router)
├─ Secondary Cluster ở region khác (DR)
├─ CDN + Application-level caching
├─ DBA team dedicated
├─ 24/7 monitoring và on-call
└─ Chi phí: $5,000+/tháng
VII. Case Studies Thực Tế
Case Study 1: E-commerce Startup → Scale-up
📌 Tình Huống:
- Startup e-commerce Việt Nam
- Bắt đầu: 100 orders/ngày
- Sau 1 năm: 5,000 orders/ngày
- Yêu cầu: 99.9% uptime, không mất orders
🔄 Evolution:
Year 1: Single Instance (t2.medium)
↓ Traffic tăng, đọc sản phẩm chậm
Year 2: Master-Slave Replication
├─ 1 Master (orders, users, inventory)
├─ 2 Slaves (product catalog reads)
└─ Chi phí: $400/tháng
↓ Black Friday: Master crash, downtime 45 phút
Year 3: Group Replication
├─ 3-node cluster với auto failover
├─ MySQL Router cho applications
├─ Downtime: 0 trong 6 tháng qua
└─ Chi phí: $1,200/tháng
Result:
✅ 99.95% uptime
✅ Order processing không bị gián đoạn
✅ Customer trust tăng → Revenue tăng 3x
Case Study 2: Fintech Company
📌 Tình Huống:
- Fintech payment gateway
- 10,000+ transactions/ngày
- Yêu cầu: ACID compliance, zero data loss
💡 Solution:
InnoDB Cluster (5 nodes)
├─ Primary site: 3 nodes + Router
├─ DR site: 2 nodes (async replication từ primary)
├─ SSL/TLS encryption
├─ Audit logging enabled
├─ Real-time monitoring + PagerDuty
└─ DBA team on-call 24/7
Backup Strategy:
├─ Hourly incremental backups
├─ Daily full backups
├─ Binlog shipping realtime
├─ Offsite backups (AWS S3)
└─ Monthly DR drills
Result:
✅ 99.99% uptime trong 2 năm
✅ Zero data loss
✅ Tuân thủ compliance (PCI-DSS)
✅ Average failover time: < 8 giây
XIII. Tổng Kết và Khuyến Nghị
Key Takeaways
🎯 Điểm Quan Trọng Cần Nhớ:
-
Không Có "One Size Fits All"
- Mỗi stage của dự án cần approach khác nhau
- Start simple, scale khi cần
-
Single Instance → Replication → Group Replication → InnoDB Cluster
- Đây là evolution tự nhiên khi hệ thống phát triển
- Mỗi bước giải quyết vấn đề của bước trước
-
High Availability ≠ Zero Downtime
- HA giảm downtime, không loại bỏ hoàn toàn
- Cần kết hợp: DB HA + Application resilience + Monitoring
-
Trade-offs Luôn Tồn Tại
Simplicity ←→ Availability Performance ←→ Consistency Cost ←→ Features -
Backup Là Bắt Buộc Bất Kể Dùng Mô Hình Nào
- Replication ≠ Backup
- Test restore thường xuyên
Decision Matrix Cuối Cùng
📝 Checklist Lựa Chọn:
□ Budget: Có bao nhiêu cho infrastructure?
□ Team Skill: Team có kinh nghiệm nào?
□ Traffic: Đọc nhiều hay ghi nhiều?
□ Uptime SLA: Cần 99% hay 99.99%?
□ Data Criticality: Mất dữ liệu = thiệt hại bao nhiêu?
□ Growth Plan: Dự kiến scale như thế nào?
□ Compliance: Có yêu cầu audit, security đặc biệt?
Dựa trên answers → Chọn giải pháp phù hợp
Khuyến Nghị Cuối Cùng
🚀 Cho Startups:
- Bắt đầu với Single Instance hoặc Managed Service (RDS)
- Focus vào product, đừng over-engineer database
- Setup monitoring và backups từ ngày đầu
- Scale khi có problem thực sự, không phải "vì sợ"
🏢 Cho Mid-size Companies:
- Đầu tư vào Replication hoặc Group Replication
- Hire ít nhất 1 experienced DBA hoặc DevOps
- Implement DR plan và test quarterly
- Balance giữa cost và reliability
🏦 Cho Enterprise:
- Sử dụng InnoDB Cluster hoặc Commercial solutions
- Dedicated DBA team 24/7
- Multi-region deployment cho DR
- Regular DR drills và compliance audits
💡 Bonus Tip:
"Đừng dùng MySQL để làm những việc nó không được thiết kế cho. Cache → Redis. Search → Elasticsearch. Analytics → ClickHouse. Mỗi tool cho đúng việc của nó."
Kết Luận
Việc triển khai MySQL Database đã phát triển từ mô hình Single Instance đơn giản đến các giải pháp High Availability phức tạp như Group Replication và InnoDB Cluster. Không có giải pháp nào là "tốt nhất" – chỉ có giải pháp phù hợp nhất với giai đoạn, ngân sách và yêu cầu của dự án.
🎯 Remember:
- Single Instance: Đơn giản, rẻ, cho dev/MVP
- Replication: Scale đọc, backup realtime
- Group Replication: HA với auto failover
- InnoDB Cluster: HA hoàn chỉnh với transparent routing
Hãy bắt đầu từ đơn giản, monitor chặt chẽ, và scale khi cần thiết. Database là trái tim của application – đừng để nó trở thành điểm yếu!
Chúc các bạn success trong việc xây dựng hệ thống database mạnh mẽ, scalable và highly available! Happy coding và may your queries be fast, your backups be reliable, and your downtime be zero! 🗄️✨
Xem thêm bài viết của tôi tại: codeeasy.blog
All rights reserved
